这些报告来自quickbooks,以Excel文件下载。请注意左侧列是基于左侧间距的嵌套层次结构。
我需要根据左侧前导空格数将描述列分成单独的列。
由于我最近一直在处理财务报告,这些报告非常常见且极难处理。是否有导入此类数据的软件包或功能?
我需要根据左侧前导空格数将描述列分成单独的列。
由于我最近一直在处理财务报告,这些报告非常常见且极难处理。是否有导入此类数据的软件包或功能?
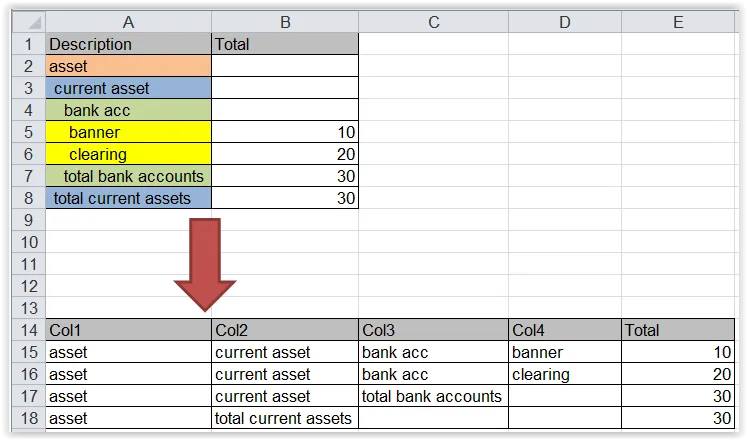
这是一个可重复的输入数据框架示例:
df1 <- structure(list(Description = c("asset", " current asset", " bank acc",
" banner", " clearing",
" total bank accounts",
" total current assets"),
Total = c(NA, NA, NA, 10L, 20L, 30L, 30L)),
.Names = c("Description", "Total"),
class = "data.frame",
row.names = c(NA, -7L))