我正在尝试使用sklearn库在Python中执行线性回归。
这是我用来训练和拟合模型的代码,当我运行预测函数调用时出现错误。
train, test = train_test_split(h1, test_size = 0.5, random_state=0)
my_features = ['bedrooms', 'bathrooms', 'sqft_living', 'sqft_lot', 'floors', 'zipcode']
trainInp = train[my_features]
target = ['price']
trainOut = train[target]
regr = LinearRegression()
# Train the model using the training sets
regr.fit(trainInp, trainOut)
print('Coefficients: \n', regr.coef_)
testPred = regr.predict(test)
在拟合模型之后,当我尝试使用测试数据进行预测时,它会抛出以下错误
Traceback (most recent call last):
File "C:/Users/gouta/PycharmProjects/MLCourse1/Python.py", line 52, in <module>
testPred = regr.predict(test)
File "C:\Users\gouta\Anaconda2\lib\site-packages\sklearn\linear_model\base.py", line 200, in predict
return self._decision_function(X)
File "C:\Users\gouta\Anaconda2\lib\site-packages\sklearn\linear_model\base.py", line 183, in _decision_function
X = check_array(X, accept_sparse=['csr', 'csc', 'coo'])
File "C:\Users\gouta\Anaconda2\lib\site-packages\sklearn\utils\validation.py", line 393, in check_array
array = array.astype(np.float64)
ValueError: invalid literal for float(): 20140604T000000
线性回归模型的系数为:
('Coefficients: \n', array([[ -5.04902429e+04, 5.23550164e+04, 2.90631319e+02,
-1.19010351e-01, -1.25257545e+04, 6.52414059e+02]]))
以下是测试数据集的前五行
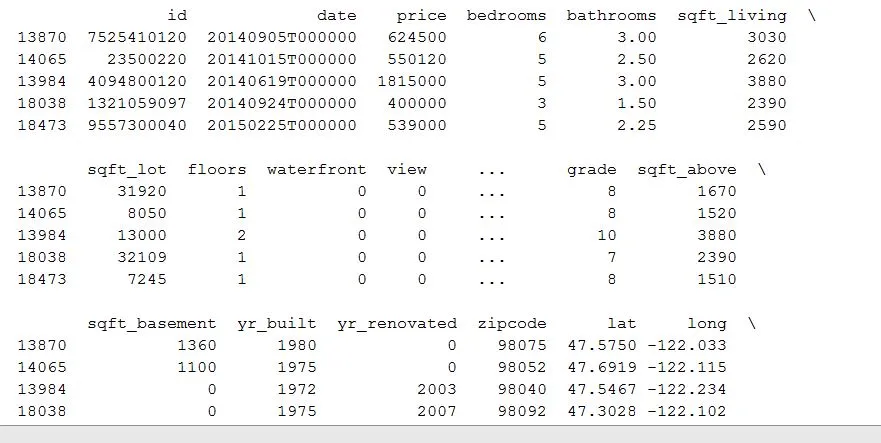
错误是否是由于系数值过大引起的?如何解决?