如果我在Java中有一个实现
元素的顺序是否取决于我所拥有的特定映射实现?
Map接口的对象,并且希望遍历其中包含的每一对键-值对,最有效的方法是什么?元素的顺序是否取决于我所拥有的特定映射实现?
Map接口的对象,并且希望遍历其中包含的每一对键-值对,最有效的方法是什么?Map<String, String> map = ...
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + "/" + entry.getValue());
}
在 Java 10+ 版本中:
for (var entry : map.entrySet()) {
System.out.println(entry.getKey() + "/" + entry.getValue());
}
remove方法,唯一需要使用迭代器的原因是。如果是这种情况,另外一个答案展示了如何实现。否则,上面回答中展示的增强型循环是可行的方式。 - assyliasmap.values() 或 map.keySet()。 - dguay总结其他答案,并结合我的经验,我发现了10种主要的方法来实现这个目标(见下文)。此外,我编写了一些性能测试(见下面的结果)。例如,如果我们想要找到一个映射表中所有键和值的总和,我们可以这样写:
使用迭代器和Map.Entry
long i = 0;
Iterator<Map.Entry<Integer, Integer>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, Integer> pair = it.next();
i += pair.getKey() + pair.getValue();
}
使用 foreach 和 Map.Entry
long i = 0;
for (Map.Entry<Integer, Integer> pair : map.entrySet()) {
i += pair.getKey() + pair.getValue();
}
使用Java 8中的forEach
final long[] i = {0};
map.forEach((k, v) -> i[0] += k + v);
使用 keySet 和 foreach
long i = 0;
for (Integer key : map.keySet()) {
i += key + map.get(key);
}
使用 keySet 和 iterator
long i = 0;
Iterator<Integer> itr2 = map.keySet().iterator();
while (itr2.hasNext()) {
Integer key = itr2.next();
i += key + map.get(key);
}
使用 for 和 Map.Entry
long i = 0;
for (Iterator<Map.Entry<Integer, Integer>> entries = map.entrySet().iterator(); entries.hasNext(); ) {
Map.Entry<Integer, Integer> entry = entries.next();
i += entry.getKey() + entry.getValue();
}
使用Java 8的Stream API
final long[] i = {0};
map.entrySet().stream().forEach(e -> i[0] += e.getKey() + e.getValue());
使用Java 8的Stream API并行处理
final long[] i = {0};
map.entrySet().stream().parallel().forEach(e -> i[0] += e.getKey() + e.getValue());
使用 Apache Collections 的 IterableMap
long i = 0;
MapIterator<Integer, Integer> it = iterableMap.mapIterator();
while (it.hasNext()) {
i += it.next() + it.getValue();
}
使用Eclipse (CS) collections的MutableMap
final long[] i = {0};
mutableMap.forEachKeyValue((key, value) -> {
i[0] += key + value;
});
性能测试(模式=平均时间,系统=Windows 8.1 64位,Intel i7-4790 3.60 GHz,16 GB)
对于一个小地图(100个元素),得分0.308是最好的。
Benchmark Mode Cnt Score Error Units
test3_UsingForEachAndJava8 avgt 10 0.308 ± 0.021 µs/op
test10_UsingEclipseMap avgt 10 0.309 ± 0.009 µs/op
test1_UsingWhileAndMapEntry avgt 10 0.380 ± 0.014 µs/op
test6_UsingForAndIterator avgt 10 0.387 ± 0.016 µs/op
test2_UsingForEachAndMapEntry avgt 10 0.391 ± 0.023 µs/op
test7_UsingJava8StreamApi avgt 10 0.510 ± 0.014 µs/op
test9_UsingApacheIterableMap avgt 10 0.524 ± 0.008 µs/op
test4_UsingKeySetAndForEach avgt 10 0.816 ± 0.026 µs/op
test5_UsingKeySetAndIterator avgt 10 0.863 ± 0.025 µs/op
test8_UsingJava8StreamApiParallel avgt 10 5.552 ± 0.185 µs/op
对于一个包含10000个元素的地图,得分37.606是最佳的
Benchmark Mode Cnt Score Error Units
test10_UsingEclipseMap avgt 10 37.606 ± 0.790 µs/op
test3_UsingForEachAndJava8 avgt 10 50.368 ± 0.887 µs/op
test6_UsingForAndIterator avgt 10 50.332 ± 0.507 µs/op
test2_UsingForEachAndMapEntry avgt 10 51.406 ± 1.032 µs/op
test1_UsingWhileAndMapEntry avgt 10 52.538 ± 2.431 µs/op
test7_UsingJava8StreamApi avgt 10 54.464 ± 0.712 µs/op
test4_UsingKeySetAndForEach avgt 10 79.016 ± 25.345 µs/op
test5_UsingKeySetAndIterator avgt 10 91.105 ± 10.220 µs/op
test8_UsingJava8StreamApiParallel avgt 10 112.511 ± 0.365 µs/op
test9_UsingApacheIterableMap avgt 10 125.714 ± 1.935 µs/op
对于一个拥有100000个元素的地图,得分1184.767为最佳
Benchmark Mode Cnt Score Error Units
test1_UsingWhileAndMapEntry avgt 10 1184.767 ± 332.968 µs/op
test10_UsingEclipseMap avgt 10 1191.735 ± 304.273 µs/op
test2_UsingForEachAndMapEntry avgt 10 1205.815 ± 366.043 µs/op
test6_UsingForAndIterator avgt 10 1206.873 ± 367.272 µs/op
test8_UsingJava8StreamApiParallel avgt 10 1485.895 ± 233.143 µs/op
test5_UsingKeySetAndIterator avgt 10 1540.281 ± 357.497 µs/op
test4_UsingKeySetAndForEach avgt 10 1593.342 ± 294.417 µs/op
test3_UsingForEachAndJava8 avgt 10 1666.296 ± 126.443 µs/op
test7_UsingJava8StreamApi avgt 10 1706.676 ± 436.867 µs/op
test9_UsingApacheIterableMap avgt 10 3289.866 ± 1445.564 µs/op
图表(性能测试取决于地图大小)
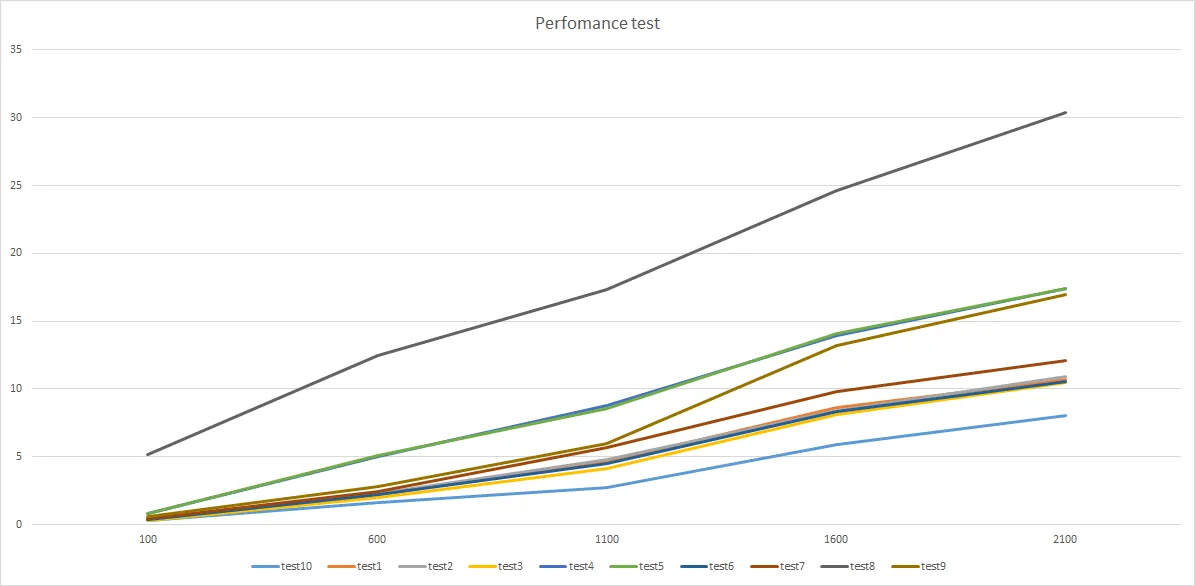
表格(性能测试取决于地图大小)
100 600 1100 1600 2100
test10 0.333 1.631 2.752 5.937 8.024
test3 0.309 1.971 4.147 8.147 10.473
test6 0.372 2.190 4.470 8.322 10.531
test1 0.405 2.237 4.616 8.645 10.707
test2 0.376 2.267 4.809 8.403 10.910
test7 0.473 2.448 5.668 9.790 12.125
test9 0.565 2.830 5.952 13.220 16.965
test4 0.808 5.012 8.813 13.939 17.407
test5 0.810 5.104 8.533 14.064 17.422
test8 5.173 12.499 17.351 24.671 30.403
所有的测试都在GitHub上进行。
long sum = 0; map.forEach( /* accumulate in variable sum*/);捕获了sum long,这可能比例如stream.mapToInt(/*whatever*/).sum慢。当然,你不能总是避免捕获状态,但这可能是基准测试的一个合理补充。 - GPIx±e时,结果在从x-e到x+e的区间内。因此最快的结果(1184.767±332.968)范围从852到1518,而第二慢的结果(1706.676±436.867)范围在 1270 和 2144 之间,因此结果仍然有重叠部分。现在看看最慢的结果,3289.866±1445.564,这意味着它在1844和4735之间发散,你知道这些测试结果是没有意义的。 - Holgerwhile循环和for循环并不是迭代的不同技术。我惊讶于它们在您的测试中之间存在如此大的差异,这表明测试没有与与您打算测试的事物无关的外部因素正确地隔离开来。 - ErikE在Java 8中,您可以使用新的lambda功能来快速而干净地完成它:
Map<String,String> map = new HashMap<>();
map.put("SomeKey", "SomeValue");
map.forEach( (k,v) -> [do something with key and value] );
// such as
map.forEach( (k,v) -> System.out.println("Key: " + k + ": Value: " + v));
编译器将推断k和v的类型,不再需要使用Map.Entry。
非常简单!
map.entrySet().stream() 返回的条目上使用流 API。http://docs.oracle.com/javase/8/docs/api/java/util/stream/Stream.html - Vitalii Fedorenko是的,顺序取决于具体的Map实现。
@ScArcher2拥有更优雅的Java 1.5语法。在1.4中,我会做类似于这样的事情:
Iterator entries = myMap.entrySet().iterator();
while (entries.hasNext()) {
Entry thisEntry = (Entry) entries.next();
Object key = thisEntry.getKey();
Object value = thisEntry.getValue();
// ...
}
for 循环语句的形式 for (Entry e : myMap.entrySet) 无法修改集合元素,但是像 @HanuAthena 所提到的例子应该可以工作,因为它提供了一个在作用域内的 Iterator。 (除非我漏掉了什么...) - pkaedingEntry thisEntry = (Entry) entries.next();上给我报错:无法识别Entry。这是代表其他东西的伪代码吗? - JohnKjava.util.Map.Entry。 - pkaeding迭代Map的典型代码如下:
Map<String,Thing> map = ...;
for (Map.Entry<String,Thing> entry : map.entrySet()) {
String key = entry.getKey();
Thing thing = entry.getValue();
...
}
HashMap 是经典的映射实现,如果没有进行任何更改操作,则不保证其顺序不变(尽管它应该保持顺序不变)。SortedMap 将根据键的自然排序或提供的 Comparator 返回条目。LinkedHashMap 根据其构造方式返回插入顺序或访问顺序的条目。EnumMap 按键的自然顺序返回条目。
(更新:我认为这已经不再正确了。) 注意,IdentityHashMap 的 entrySet 迭代器目前具有奇特的实现,它会为 entrySet 中的每个项目返回相同的 Map.Entry 实例!但是,每次新迭代器推进时,Map.Entry 都会被更新。
LinkedHashMap 的直接访问才会计入顺序更改的操作,通过 iterator、spliterator、entrySet 等方式访问时不会修改顺序。 - Tom Hawtin - tacklineIterator<Map.Entry<String, String>> entries = myMap.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry<String, String> entry = entries.next();
String key = entry.getKey();
String value = entry.getValue();
// ...
}
Iterator放在for循环中,以限制它的作用域。 - Steve Kuoentries的作用域限制在for循环内,可以通过遍历myMap的entry set来获取每个键值对的信息。代码如下:for(Iterator<Map.Entry<K, V>> entries = myMap.entrySet().iterator(); entries.hasNext(); ) { Map.Entry<K, V> entry = entries.next(); }。 - ComFreek这是一个由两个部分组成的问题:
如何迭代Map的条目 - @ScArcher2在回答中已经解答得很好。
迭代的顺序是什么 - 如果你只是使用Map,那么严格来说,并没有任何排序保证。因此,你不应该依赖于任何实现给出的排序方式。然而,SortedMap接口扩展自Map,并提供了你正在寻找的东西——实现将始终给出一致的排序顺序。
NavigableMap是另一个有用的扩展 - 这是一个带有额外方法的SortedMap,可以通过它们在键集中的有序位置查找条目。因此,可能可以省去首先进行迭代的必要性——你可以使用higherEntry、lowerEntry、ceilingEntry或floorEntry方法找到你想要的特定entry。而descendingMap方法甚至提供了一种明确的方法来反转遍历顺序。
有几种方法可以迭代map。
这里比较它们在常见的数据集上的性能,该数据集将一百万个键值对存储在map中,并将对map进行迭代。
1)使用for each循环中的entrySet()
for (Map.Entry<String,Integer> entry : testMap.entrySet()) {
entry.getKey();
entry.getValue();
}
50毫秒
2) 在for each循环中使用keySet()
for (String key : testMap.keySet()) {
testMap.get(key);
}
76毫秒
3) 使用entrySet()和迭代器
Iterator<Map.Entry<String,Integer>> itr1 = testMap.entrySet().iterator();
while(itr1.hasNext()) {
Map.Entry<String,Integer> entry = itr1.next();
entry.getKey();
entry.getValue();
}
50毫秒
4) 使用keySet()和迭代器
Iterator itr2 = testMap.keySet().iterator();
while(itr2.hasNext()) {
String key = itr2.next();
testMap.get(key);
}
75毫秒
我参考了这个链接。
提示:如果你只关心Map的键或值而不是其他内容,也可以使用map.keySet()和map.values()。
正确的做法是使用被接受的答案,因为它最有效。我发现以下代码看起来更简洁。
for (String key: map.keySet()) {
System.out.println(key + "/" + map.get(key));
}
O(1) = 2*O(1)几乎是大O符号的定义。你说得没错,它的运行速度略慢,但从复杂度角度来看,它们是相同的。 - kritzikratzi2,因为遍历entrySet()并不涉及查找;它只是线性遍历所有条目。相比之下,遍历keySet()并对每个键执行查找则涉及到每个键一次查找,因此这里涉及零次查找与n次查找,其中n是Map的大小。因此,该因子远远超过2... - Holgerhashcode%capacity相同时,就已经发生了冲突。从Java 8开始,具有相同hashcode%capacity但不同hashcode或是实现了Comparable接口的项的复杂度会回退到O(log n),只有具有相同哈希码且未实现Comparable接口的键才会导致O(n)的复杂度。但是,实际上查找的复杂度可能仍然超过O(1)。 - Holger
Map map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
map.forEach((key, value) -> {
System.out.println(key + " : " + value);
}); 此外,还可以使用Stream API将Map转换为流,并使用forEach或其他终端操作对其进行迭代。示例代码如下:Map map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
map.entrySet().stream().forEach(entry -> {
System.out.println(entry.getKey() + " : " + entry.getValue());
}); 请注意,在迭代Map时,应该使用entrySet而不是keySet或values,因为entrySet提供了更好的性能。 - akhil_mittal