我从服务器收到的一条消息包含标签,而在标签中是我需要的数据。
我试图将负载解析为XML,但会生成非法字符异常。
我还使用了httpUtility和Security Utility来转义非法字符,唯一的问题是它会转义< >,而这些字符是解析XML所必需的。
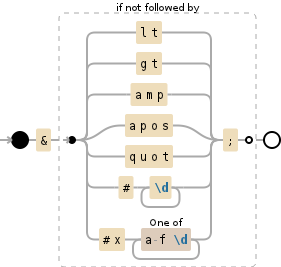
我的问题是,当数据中包含非法的非XML字符时,我该如何解析XML? (& -& gt; amp;)_
谢谢。
示例:
我试图将负载解析为XML,但会生成非法字符异常。
我还使用了httpUtility和Security Utility来转义非法字符,唯一的问题是它会转义< >,而这些字符是解析XML所必需的。
我的问题是,当数据中包含非法的非XML字符时,我该如何解析XML? (& -& gt; amp;)_
谢谢。
示例:
<item><code>1234</code><title>voi hoody & polo shirt + Mckenzie jumper</title><description>Good condition size small - medium, text me if interested</description></item>
string.Replace()方法来修复所有非法字符。 - Chuck Savage