在Tensorflow中,整个反向传播算法似乎是通过在某个MLP或CNN的输出上运行优化器一次完成的。我不完全明白Tensorflow如何从成本中知道它确实是某个NN的输出?可以为任何模型定义成本函数。我该如何“告诉”它某个成本函数来自于NN?
在TensorFlow中,反向传播是如何工作的?
18
- Ezer Miller
1
你应该了解深度学习库是如何工作的,特别是图计算。简而言之:代价函数是图上的一个节点,边(权重)来自于网络的最后一层。 - gidim
2个回答
40
问题
我应该如何“告诉” TensorFlow 一个特定的成本函数是由神经网络派生出来的?
(简短) 回答
这可以通过配置优化器以最小化(或最大化)张量来完成。例如,如果我有以下损失函数:
loss = tf.reduce_sum( tf.square( y0 - y_out ) )
如果y0是真实标签(或期望输出),而y_out是计算的输出,则我可以通过以下方式定义我的训练函数来最小化损失。
train = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
这告诉Tensorflow,在计算train时,应用梯度下降来最小化loss,而loss是使用y0和y_out计算的,因此梯度下降也会影响它们(如果它们是可训练变量),以此类推。
变量y0、y_out、loss和train不是标准的Python变量,而是一个计算图的描述。Tensorflow利用关于该计算图的信息,展开它并应用梯度下降。
具体它如何实现超出了本答案的范围。 这里 和 这里 是更多关于细节的信息的两个好起点。
代码示例
让我们通过一个代码示例来演示一下。首先看代码:
### imports
import tensorflow as tf
### constant data
x = [[0.,0.],[1.,1.],[1.,0.],[0.,1.]]
y_ = [[0.],[0.],[1.],[1.]]
### induction
# 1x2 input -> 2x3 hidden sigmoid -> 3x1 sigmoid output
# Layer 0 = the x2 inputs
x0 = tf.constant( x , dtype=tf.float32 )
y0 = tf.constant( y_ , dtype=tf.float32 )
# Layer 1 = the 2x3 hidden sigmoid
m1 = tf.Variable( tf.random_uniform( [2,3] , minval=0.1 , maxval=0.9 , dtype=tf.float32 ))
b1 = tf.Variable( tf.random_uniform( [3] , minval=0.1 , maxval=0.9 , dtype=tf.float32 ))
h1 = tf.sigmoid( tf.matmul( x0,m1 ) + b1 )
# Layer 2 = the 3x1 sigmoid output
m2 = tf.Variable( tf.random_uniform( [3,1] , minval=0.1 , maxval=0.9 , dtype=tf.float32 ))
b2 = tf.Variable( tf.random_uniform( [1] , minval=0.1 , maxval=0.9 , dtype=tf.float32 ))
y_out = tf.sigmoid( tf.matmul( h1,m2 ) + b2 )
### loss
# loss : sum of the squares of y0 - y_out
loss = tf.reduce_sum( tf.square( y0 - y_out ) )
# training step : gradient decent (1.0) to minimize loss
train = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
### training
# run 500 times using all the X and Y
# print out the loss and any other interesting info
with tf.Session() as sess:
sess.run( tf.global_variables_initializer() )
for step in range(500) :
sess.run(train)
results = sess.run([m1,b1,m2,b2,y_out,loss])
labels = "m1,b1,m2,b2,y_out,loss".split(",")
for label,result in zip(*(labels,results)) :
print ""
print label
print result
print ""
让我们倒过来看一下,从后面开始
sess.run(train)
这告诉TensorFlow查找由train定义的图节点并计算它。Train被定义为
train = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
为了计算这个,TensorFlow必须对损失函数执行自动微分,也就是要遍历图形。 损失函数的定义如下:
loss = tf.reduce_sum( tf.square( y0 - y_out ) )
这实际上是TensorFlow将自动微分应用于首先展开tf.reduce_sum,然后展开tf.square,最后展开y0 - y_out,这将导致必须同时遍历y0和y_out的图形。
y0 = tf.constant( y_ , dtype=tf.float32 )
y0是一个常数,不会被更新。
y_out = tf.sigmoid( tf.matmul( h1,m2 ) + b2 )
y_out 将类似于 loss 进行处理,首先会进行 tf.sigmoid 的处理,等等...
总之,每个操作(例如 tf.sigmoid、tf.square)不仅定义了前向操作(应用 sigmoid 或 square),而且还包含了 自动微分 所需的信息。这与标准的 Python 数学运算不同,如:
x = 7 + 9
上述方程仅编码如何更新x,而不涉及其他方面。
z = y0 - y_out
将 y_out 减去 y0 的图形编码,并存储前向操作及足够进行自动微分的内容在 z 中。
- Anton Codes
2
1这非常有帮助!非常感谢。我在其他网站上找不到这种信息。它们只是演示代码和指令,而没有解释背后正在发生的事情。你能推荐一个更深入解释TF的网站吗?一个也解释了这种独特编程范例背后的理性的地方。 - Ezer Miller
1很遗憾,我没有找到任何有用的阅读材料。我是通过为自己制定一个小型学习课程并实践来加深对Tensorflow的理解的。这是链接:https://github.com/panchishin/learn-to-tensorflow ,我确实按照README中所写的做了。每天花费大约一个小时,连续几周才能在所有挑战中达到Level 4 - Solo,而且没有作弊。一旦我达到了Level 4 - Solo,即使我只是处理小例子,Tensorflow也感觉非常自然。 - Anton Codes
2
反向传播算法由Rumelhart和Hinton等人创造,并于1986年在Nature上发表。
正如深度学习书籍第6.5节所述,反向传播梯度通过计算图的两种方法:从符号到数字的微分和从符号到符号的导数。Tensorflow更相关的是后者,正如这篇论文所述:TensorFlow简介,可以用以下图表说明:
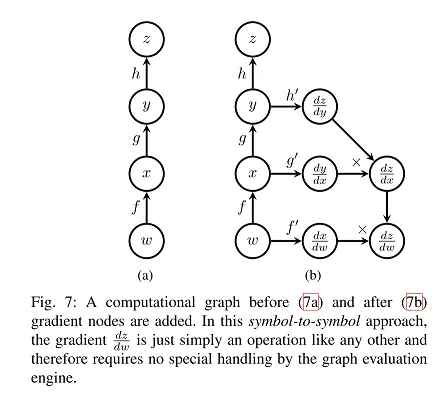
在上图7的左侧,w代表Tensorflow中的权重(或变量),x和y是两个中间操作(或节点,w、x、y和z都是操作),用于得到标量损失z。
Tensorflow将为每个节点添加一个节点(如果我们打印某个检查点中变量的名称,我们可以看到这些节点的一些附加变量,并且如果我们将模型冻结到协议缓冲区文件以进行部署,则它们将被消除),用于梯度,如右侧的图(b)所示:dz/dy,dy/dx,dx/dw。
在反向传播遍历过程中,我们将每个节点的梯度与前一个节点的梯度相乘,最终得到一个符号处理器,用于整体目标导数dz/dw=dz/dy*dy/dx*dx/dw,这正好应用了链式法则。一旦梯度计算出来,w就可以使用学习率更新自己。
请阅读这篇论文以获取更详细的信息:TensorFlow: 大规模异构分布式系统上的机器学习。
- Lerner Zhang
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接