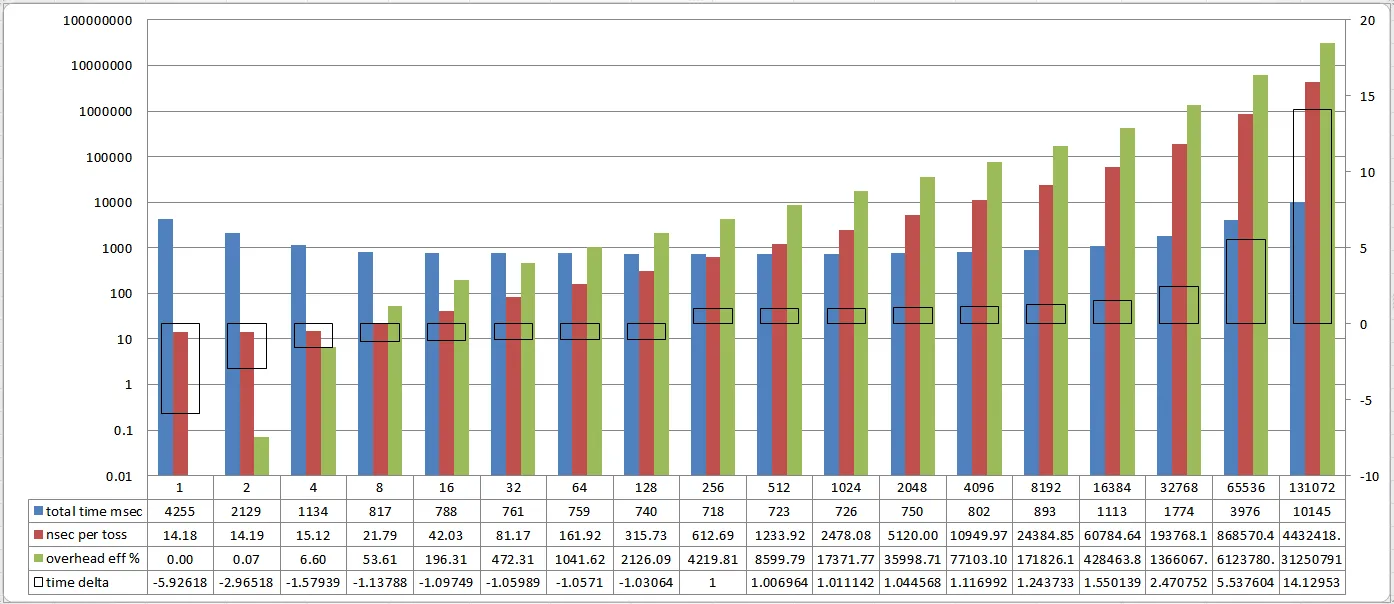
作为学校任务的一部分,我们需要构建一个玩具程序来确定我们个人计算机的最佳线程数。首先,我们需要创建一个需要运行20到30秒的任务。我选择了进行硬币抛掷模拟,将累积得到的正反面总数显示出来。在我的机器上,单线程3亿次抛掷耗时25秒。之后,我尝试使用2线程、4线程、8线程、16线程、32线程以及仅供娱乐使用的100线程进行测试。以下是测试结果:
* 线程数 抛掷次数 时间(秒) * ------------------------------------------ * 1 300,000,000 25 * 2 150,000,000 13 * 4 75,000,000 13 * 8 37,500,000 13 * 16 18,750,000 14 * 32 9,375,000 14 * 100 3,000,000 14
这是我所使用的代码:
现在是主要问题:
超过某个点后,随着添加更多线程,我本来期望计算速度会显著下降,但结果似乎并没有表现出这一点。
我的代码有根本性的错误导致这种结果吗?还是这种行为被认为是正常的?我对多线程非常新手,所以我感觉可能是前者……
谢谢!
编辑:我正在MacBook上运行,使用2.16 GHz Core 2 Duo (T7400)处理器
* 线程数 抛掷次数 时间(秒) * ------------------------------------------ * 1 300,000,000 25 * 2 150,000,000 13 * 4 75,000,000 13 * 8 37,500,000 13 * 16 18,750,000 14 * 32 9,375,000 14 * 100 3,000,000 14
这是我所使用的代码:
void toss()
{
int heads = 0, tails = 0;
default_random_engine gen;
uniform_int_distribution<int> dist(0,1);
int max =3000000; //tosses per thread
for(int x = 0; x < max; ++x){(dist(gen))?++heads:++tails;}
cout<<heads<<" "<<tails<<endl;
}
int main()
{
vector<thread>thr;
time_t st, fin;
st = time(0);
for(int i = 0;i < 100;++i){thr.push_back(thread(toss));} //thread count
for(auto& thread: thr){thread.join();}
fin = time(0);
cout<<fin-st<<" seconds\n";
return 0;
}
现在是主要问题:
超过某个点后,随着添加更多线程,我本来期望计算速度会显著下降,但结果似乎并没有表现出这一点。
我的代码有根本性的错误导致这种结果吗?还是这种行为被认为是正常的?我对多线程非常新手,所以我感觉可能是前者……
谢谢!
编辑:我正在MacBook上运行,使用2.16 GHz Core 2 Duo (T7400)处理器