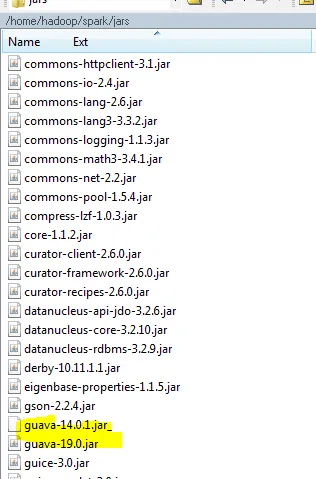
我在EMR上运行Spark作业,并使用DataStax连接器连接到Cassandra集群。我遇到了关于Guava jar的问题,请查看以下详细信息 我正在使用以下Cassandra依赖项
cqlsh 5.0.1 | Cassandra 3.0.1 | CQL spec 3.3.1
在EMR 4.4上运行spark作业,使用以下Maven依赖项:
org.apache.spark spark-streaming_2.10 1.5.0
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId><dependency>
<groupId>com.datastax.spark</groupId>
<artifactId>spark-cassandra-connector_2.10</artifactId>
<version>1.5.0</version>
</dependency>
<artifactId>spark-streaming-kinesis-asl_2.10</artifactId>
<version>1.5.0</version>
</dependency>
我在提交以下Spark作业时遇到了问题。
ava.lang.ExceptionInInitializerError
at com.datastax.spark.connector.cql.DefaultConnectionFactory$.clusterBuilder(CassandraConnectionFactory.scala:35)
at com.datastax.spark.connector.cql.DefaultConnectionFactory$.createCluster(CassandraConnectionFactory.scala:87)
at com.datastax.spark.connector.cql.CassandraConnector$.com$datastax$spark$connector$cql$CassandraConnector$$createSession(CassandraConnector.scala:153)
at com.datastax.spark.connector.cql.CassandraConnector$$anonfun$2.apply(CassandraConnector.scala:148)
at com.datastax.spark.connector.cql.CassandraConnector$$anonfun$2.apply(CassandraConnector.scala:148)
at com.datastax.spark.connector.cql.RefCountedCache.createNewValueAndKeys(RefCountedCache.scala:31)
at com.datastax.spark.connector.cql.RefCountedCache.acquire(RefCountedCache.scala:56)
at com.datastax.spark.connector.cql.CassandraConnector.openSession(CassandraConnector.scala:81)
at ampush.event.process.core.CassandraServiceManagerImpl.getAdMetaInfo(CassandraServiceManagerImpl.java:158)
at ampush.event.config.metric.processor.ScheduledEventAggregator$4.call(ScheduledEventAggregator.java:308)
at ampush.event.config.metric.processor.ScheduledEventAggregator$4.call(ScheduledEventAggregator.java:290)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$foreachPartition$1.apply(JavaRDDLike.scala:222)
at org.apache.spark.api.java.JavaRDDLike$$anonfun$foreachPartition$1.apply(JavaRDDLike.scala:222)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$29.apply(RDD.scala:902)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$29.apply(RDD.scala:902)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1850)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1850)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)
at org.apache.spark.scheduler.Task.run(Task.scala:88)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:214)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.IllegalStateException: Detected Guava issue #1635 which indicates that a version of Guava less than 16.01 is in use. This introduces codec resolution issues and potentially other incompatibility issues in the driver. Please upgrade to Guava 16.01 or later.
at com.datastax.driver.core.SanityChecks.checkGuava(SanityChecks.java:62)
at com.datastax.driver.core.SanityChecks.check(SanityChecks.java:36)
at com.datastax.driver.core.Cluster.<clinit>(Cluster.java:67)
... 23 more
请告诉我如何在这里管理Guava依赖项?
谢谢。