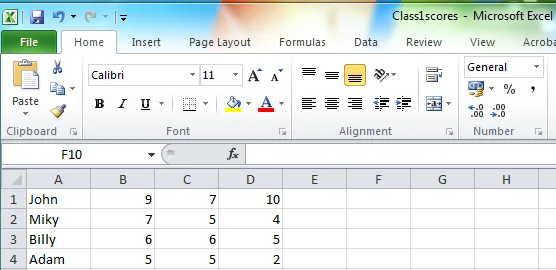
这里有一种方法可以实现。请看两个部分。首先,我们创建一个字典,以名称为键,以结果列表为值。
import csv
fileLineList = []
averageScoreDict = {}
with open('Class1scores.csv', newline='') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
fileLineList.append(row)
for row in fileLineList:
highest = 0
lowest = 0
total = 0
average = 0
for column in row:
if column.isdigit():
column = int(column)
if column > highest:
highest = column
if column < lowest or lowest == 0:
lowest = column
total += column
average = total / 3
averageScoreDict[row[0]] = [highest, lowest, round(average)]
print(averageScoreDict)
输出:
{'Milky': [7, 4, 5], 'Billy': [6, 5, 6], 'Adam': [5, 2, 4], 'John': [10, 7, 9]}
现在我们有了字典,可以通过对列表进行排序来创建您所需的最终输出。请参阅此更新的代码:
import csv
from operator import itemgetter
fileLineList = []
averageScoreDict = {}
with open('Class1scores.csv', newline='') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
fileLineList.append(row)
for row in fileLineList:
highest = 0
lowest = 0
total = 0
average = 0
for column in row:
if column.isdigit():
column = int(column)
if column > highest:
highest = column
if column < lowest or lowest == 0:
lowest = column
total += column
average = total / 3
averageScoreDict[row[0]] = [highest, lowest, round(average)]
averageScoreList = []
for key, value in averageScoreDict.items():
averageScoreList.append([key, value[2]])
averageScoreList.sort(key=itemgetter(1), reverse=True)
print('\nStudents Average Scores From Highest to Lowest\n')
print(averageScoreList)
输出:
学生平均分从高到低排序
[['约翰', 9], ['比利', 6], ['米尔基', 5], ['亚当', 4]]