我在使用VS 2013中的SSIS。
我需要从一个数据库获取一个ID列表,并使用该ID列表查询另一个数据库,即 SELECT ... from MySecondDB WHERE ID IN ({来自MyFirstDB的ID列表})。
根据另一个数据库查询结果查询数据库
10
- faujong
3
这些数据库在同一台服务器上吗? - Gary.Taylor717
不,它们在两个不同的服务器上。 - faujong
Google sp_addlinkedserver - Joel Coehoorn
5个回答
13
有三种方法可以实现这个目标:
第一种方法 - 使用Lookup变换
首先,您必须像@TheEsisia所回答的那样添加一个Lookup变换,但还需要满足以下要求:
在Lookup中,您必须编写包含ID列表的查询 (例如:
SELECT ID From MyFirstDB WHERE ...)至少您必须从lookup表中选择一个列
- 这些不会过滤行,但是将从第二个表中添加值
为了过滤行WHERE ID IN ({MyFirstDB中的ID列表}),您必须在查找错误输出Error case中进行一些工作,有两种方法:
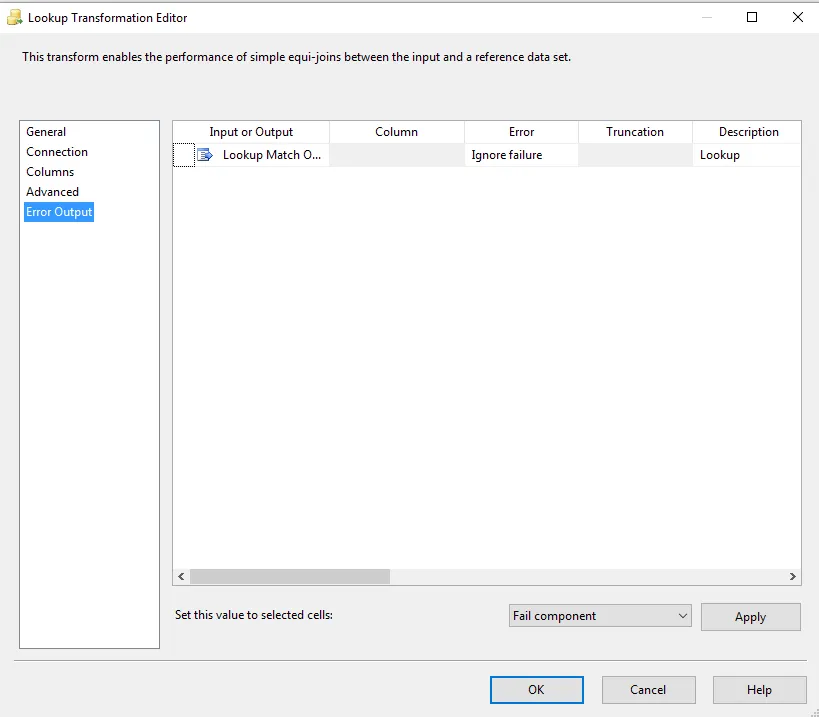
- 将错误处理设置为
忽略行,以便添加的列(来自查找)值为null,因此您必须添加一个条件分割,该分割过滤具有等于NULL值的行。
假设您已经选择将col1作为查找列,因此您必须使用类似的表达式
ISNULL([col1]) == False
- 或者您可以将错误处理设置为
重定向行,这样所有行都将被发送到错误输出行,该行可能不会被使用,因此数据将被过滤。
这种方法的缺点是在执行期间加载和过滤所有数据。
另外,如果在本地机器上(第二种服务器方法)进行网络过滤,则在加载所有数据后进行内存过滤。
第二种方法-使用脚本任务
为了避免加载所有数据,您可以使用一个解决方法。您可以使用脚本任务来实现:(以VB.NET书写的答案)
假设连接管理器名称为TestAdo,"Select [ID] FROM dbo.MyTable"是获取id列表的查询语句,并且User::MyVariableList是要存储id列表的变量。
注意:此代码将从连接管理器读取连接。
Public Sub Main()
Dim lst As New Collections.Generic.List(Of String)
Dim myADONETConnection As SqlClient.SqlConnection
myADONETConnection = _
DirectCast(Dts.Connections("TestAdo").AcquireConnection(Dts.Transaction), _
SqlClient.SqlConnection)
If myADONETConnection.State = ConnectionState.Closed Then
myADONETConnection.Open()
End If
Dim myADONETCommand As New SqlClient.SqlCommand("Select [ID] FROM dbo.MyTable", myADONETConnection)
Dim dr As SqlClient.SqlDataReader
dr = myADONETCommand.ExecuteReader
While dr.Read
lst.Add(dr(0).ToString)
End While
Dts.Variables.Item("User::MyVariableList").Value = "SELECT ... FROM ... WHERE ID IN(" & String.Join(",", lst) & ")"
Dts.TaskResult = ScriptResults.Success
End Sub
并且应该使用User::MyVariableList作为源(在变量中的Sql命令)
第三种方法 - 使用Execute Sql任务
与第二种方法类似,但是这将使用Execute SQL Task构建IN子句,然后将整个查询作为OLEDB Source使用。
- 在DataFlow任务之前添加一个Execute SQL任务
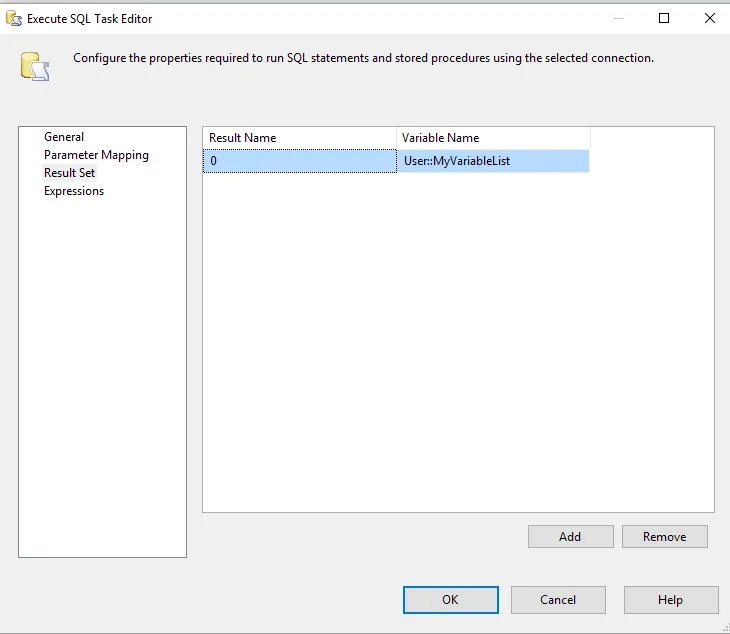
- 将
ResultSet属性设置为single - 选择
User::MyVariableList作为结果集 使用以下SQL命令
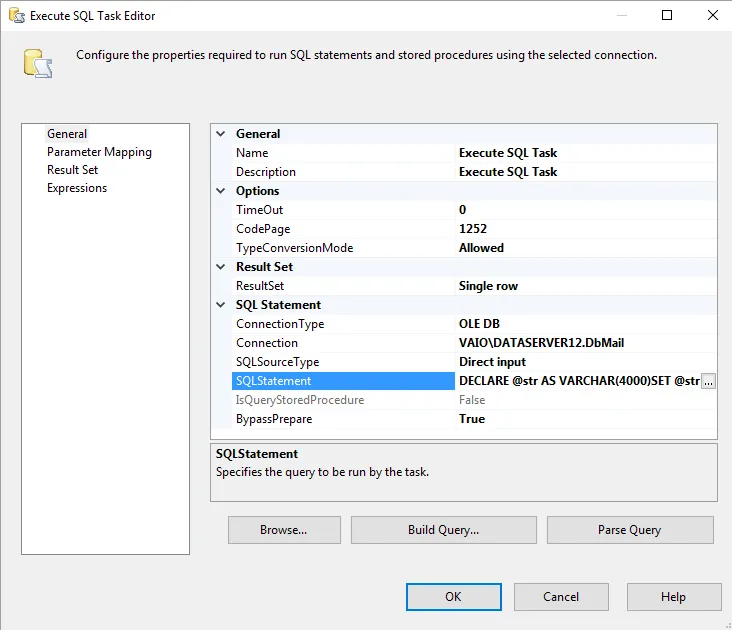
DECLARE @str AS VARCHAR(4000)
SET @str = ''
SELECT @str = @str + CAST([ID] AS VARCHAR(255)) + ','
FROM dbo.MyTable
SET @str = 'SELECT * FROM MySecondDB WHERE ID IN (' + SUBSTRING(@str,1,LEN(@str) - 1) + ')'
SELECT @str
如果列的数据类型为字符串,则应在值前后添加引号,如下所示:
SELECT @str = @str + '''' + CAST([ID] AS VARCHAR(255)) + ''','
FROM dbo.MyTable
确保您已将DataFlow Task的Delay Validation属性设置为True
- Hadi
3
1很好的解释! - amd
选项3适用于可能有超过10万个ID的情况吗?它似乎在“where ID in(select ...”语句中选择单个ID。 - ColinMac
@ColinMac 当处理大量ID时,这种方法并不理想。 - Hadi
5
这是一个使用“查找转换”经典案例。首先,使用“OLE DB源”从第一个数据库获取数据。然后,使用“查找转换”根据第二个数据集中的“ID”值过滤此数据集。以下是使用“查找转换”的步骤:
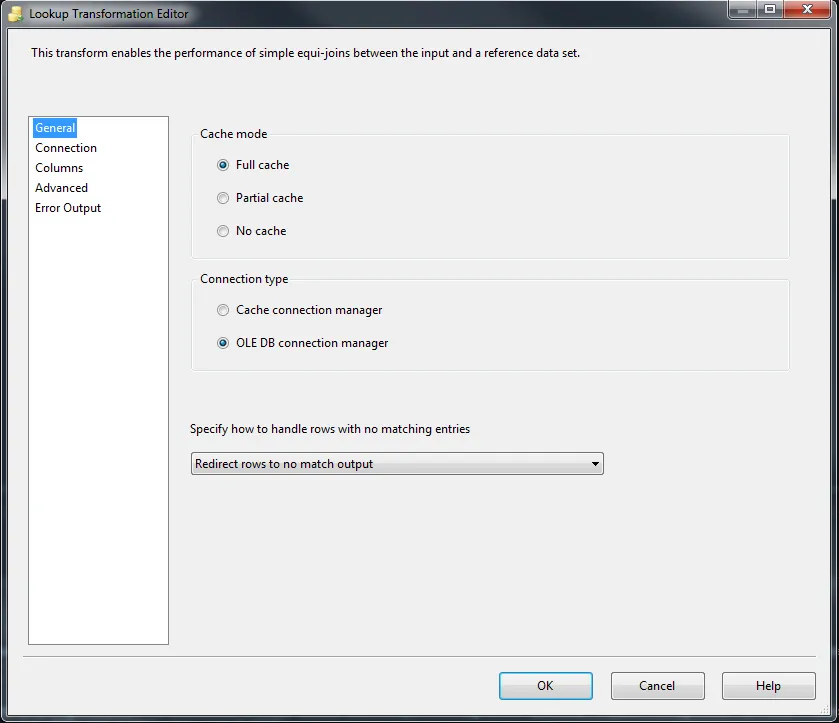
1. 在“常规”选项卡中,选择“完全缓存”,“OLE DB连接管理器”和“重定向无匹配输出”,如下图所示。请注意,使用“完全缓存”可以为您的包提供出色的性能。
常规设置
1. 在“常规”选项卡中,选择“完全缓存”,“OLE DB连接管理器”和“重定向无匹配输出”,如下图所示。请注意,使用“完全缓存”可以为您的包提供出色的性能。
常规设置
- 在
Connection选项卡中,使用OLE DB 连接管理器连接到您的第二个服务器。然后,您可以直接选择带有ID值的数据集,或者(如下图所示)使用 SQL 代码从过滤数据集中选择 ID。
连接:
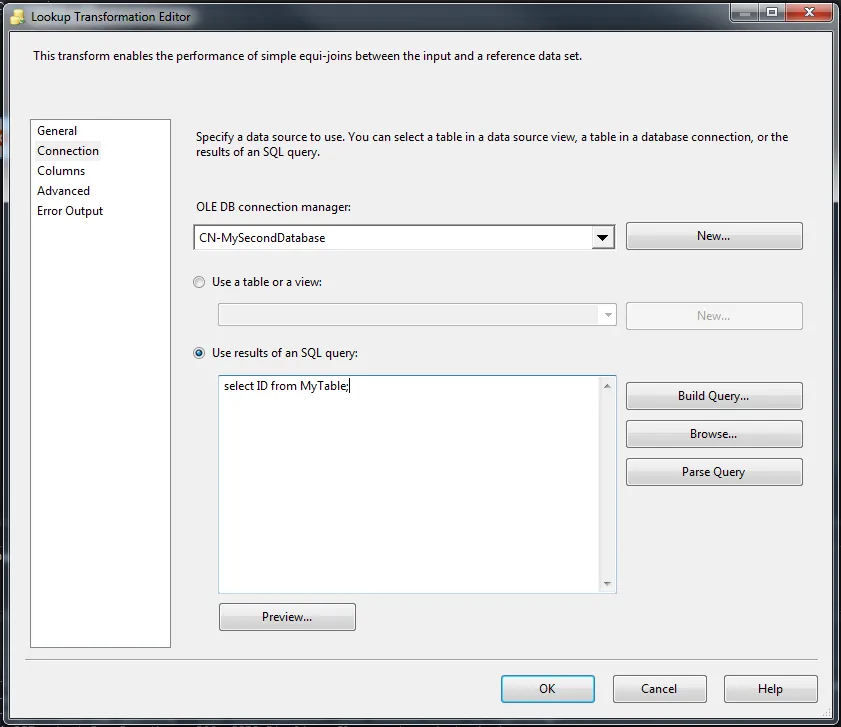
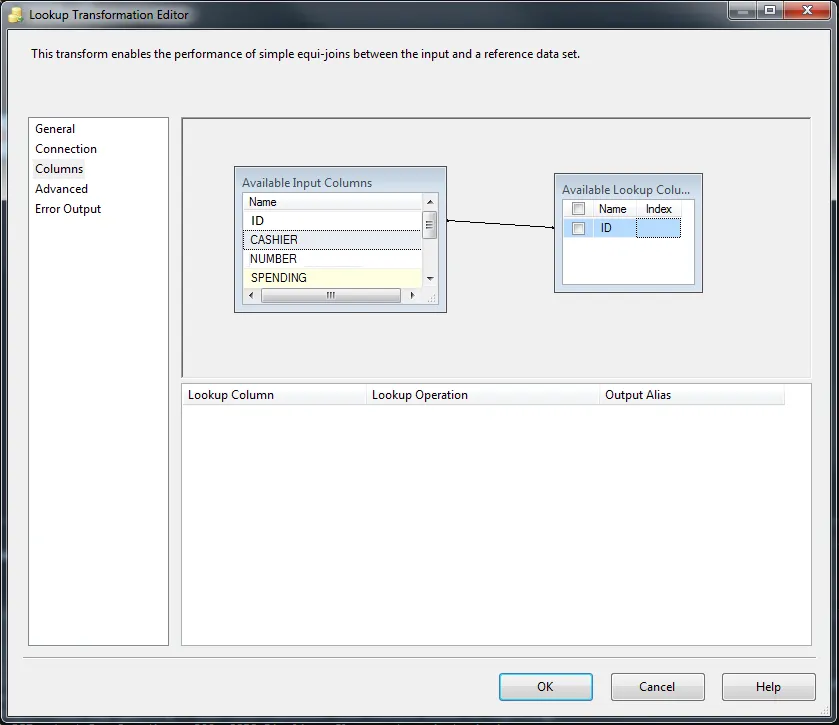
- 点击
确定关闭LookUp。然后需要选择LookUp Match Output。
匹配输出:
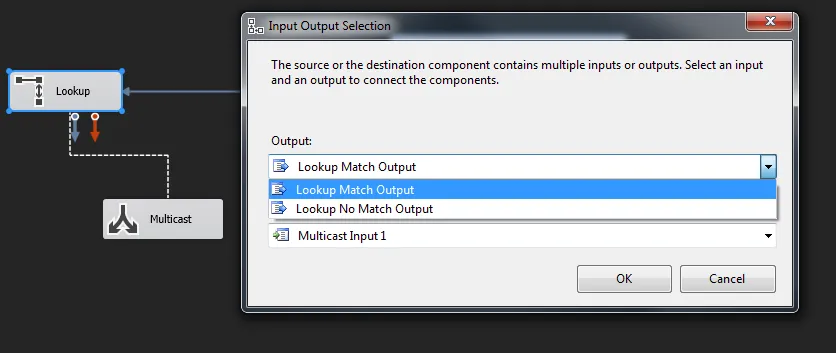
- TheEsnSiavashi
6
谢谢。@TheEsisia:myFirstDB中的ID是int,而mySecondDB中的ID是varchar(20)。因此,我创建了一个派生列,表达式为(DT_STR,20,1252)id。在查找中,我将“可用输入列”中的“Derived Column.ID”连接到“可用查找列”中的ID。我还选择了要在结果中显示的“可用查找列”的列列表。当我运行包时,我收到错误消息“查找期间未产生匹配的行”。 - faujong
1在“查找”转换中,在“连接”选项卡中选择“使用 SQL 查询的结果”。编写一个 SELECT 语句来查询表格,但对于 ID 列,使用 CAST 语句将 VARCHAR(20) 转换为 int。 - TheEsnSiavashi
3在性能方面,建议不要在此情况下使用查找功能,最好在OLEDB源中过滤数据。 - Yahfoufi
@Yahfoufi 首先,查找使用缓存技术,因此具有很好的性能。其次,在两个不同的服务器上有两个数据集时,您将如何在 OLE DB 源中过滤数据? - TheEsnSiavashi
1@TheEsisia 使用“执行 SQL 任务”获取 ID 列表并将其存储在变量中(例如:
1,2,3),在另一个变量中构建 SQL 命令作为表达式 "SELECT * FROM .... WHERE ID IN(" + @[user::variable] + ")",并将此变量用作 OLEDB SOURCE 的源。 - Yahfoufi@TheEsisia,我点赞了你的回答,因为我的第一种方法是从你的方法开始的。谢谢,祝好运。 - Hadi
2
“最佳”答案取决于涉及的数据量和源系统。许多其他答案提出了基于 SQL Server 中巧妙连接的值列表构建。如果引用的系统是Oracle、MySQL、DB2、Informix、PostGres等,这种方法就不太适用。可能会有一个等效的概念,但也可能没有。为了获得最佳性能,在任何行进入数据流之前,您需要针对第二个数据库进行过滤。这意味着在源查询中添加过滤条件,正如其他人所建议的那样。这种方法的挑战在于,您的查询将受到一些我不记得的实际限制。在您的 where 子句中使用十个、一百个、一千个值可能还好。一万、一百万 - 可能不太行。在您需要大量的值来过滤源表的情况下,可以在该服务器上创建一个表,并截断和重新加载该表(执行 SQL 任务 + 数据流)。这允许您拥有所有本地数据,然后您可以索引过滤表并让数据库引擎做它真正擅长的事情。
但是,您说源数据库是一些无法创建表格的自定义解决方案。您可以查看上述使用临时表格的方法,在 SSIS 中,您只需要将连接标记为单例/持久化(待办事项:查找此内容)。我不太喜欢在 SSIS 中使用临时表格,因为调试它们很麻烦,我甚至不希望我的敌人遭遇这种情况。
如果您还在阅读,我们已经确定了为什么在源系统中过滤可能是“行不通”的,即使它会提供最佳性能。
现在,我们只能使用纯 SSIS 解决方案。为了获得最佳性能,请不要在下拉菜单中选择表名,除非您绝对需要每个列。此外,注意您的数据类型。将 LOB(XML、文本、image(n)varchar(max)、varbinary(max))拉入数据流中会导致性能不佳。
默认建议是使用 Lookup 组件在数据流中过滤数据。只要您的源系统支持 OLE DB 提供程序(或者您可以强制将数据转换为 Cache Connection Manager),就可以做到这一点。
如果由于某些原因无法使用查找组件,则可以在源系统中显式对数据进行排序,将源组件标记为这样的组件,然后在数据流中使用内部连接类型的合并连接只带入匹配的数据。
但是,请注意,源系统中的排序将按照本机规则进行排序。我遇到过一种情况,其中SQL Server基于默认的ASCII排序进行排序,而我的运行在zOS上的DB2实例提供了一个EBCDIC排序。当我的域仅为整数时,这非常好,但当键变成字母数字时,情况就变得很糟糕(AAA、A2B和AZZ会根据此不同地排序)。
最后,除了最后一段之外,以上假定您拥有整数。如果您执行字符串匹配,则会出现额外的丑陋级别,因为不同的组件可能会执行区分大小写的匹配(使用区分大小写的系统进行排序也可能是一个因素)。
但是,您说源数据库是一些无法创建表格的自定义解决方案。您可以查看上述使用临时表格的方法,在 SSIS 中,您只需要将连接标记为单例/持久化(待办事项:查找此内容)。我不太喜欢在 SSIS 中使用临时表格,因为调试它们很麻烦,我甚至不希望我的敌人遭遇这种情况。
如果您还在阅读,我们已经确定了为什么在源系统中过滤可能是“行不通”的,即使它会提供最佳性能。
现在,我们只能使用纯 SSIS 解决方案。为了获得最佳性能,请不要在下拉菜单中选择表名,除非您绝对需要每个列。此外,注意您的数据类型。将 LOB(XML、文本、image(n)varchar(max)、varbinary(max))拉入数据流中会导致性能不佳。
默认建议是使用 Lookup 组件在数据流中过滤数据。只要您的源系统支持 OLE DB 提供程序(或者您可以强制将数据转换为 Cache Connection Manager),就可以做到这一点。
如果由于某些原因无法使用查找组件,则可以在源系统中显式对数据进行排序,将源组件标记为这样的组件,然后在数据流中使用内部连接类型的合并连接只带入匹配的数据。
但是,请注意,源系统中的排序将按照本机规则进行排序。我遇到过一种情况,其中SQL Server基于默认的ASCII排序进行排序,而我的运行在zOS上的DB2实例提供了一个EBCDIC排序。当我的域仅为整数时,这非常好,但当键变成字母数字时,情况就变得很糟糕(AAA、A2B和AZZ会根据此不同地排序)。
最后,除了最后一段之外,以上假定您拥有整数。如果您执行字符串匹配,则会出现额外的丑陋级别,因为不同的组件可能会执行区分大小写的匹配(使用区分大小写的系统进行排序也可能是一个因素)。
- billinkc
1
我会首先创建一个字符串变量,例如SQL_Select,在程序包的范围内。然后,我会使用针对第一个数据库的Execute SQL任务为其分配一个值。在“常规”页面上,“ResultSet”属性应设置为“单行”。在“结果集”选项卡中添加一个条目,将其分配给您的变量。
所使用的SQL语句需要设计为返回所需的第二个数据库的SELECT语句,以单行文本的形式呈现。以下是一个示例:
移除前5个,并将[name]和dbo.spt_values替换为您的列和表名称。
所使用的SQL语句需要设计为返回所需的第二个数据库的SELECT语句,以单行文本的形式呈现。以下是一个示例:
SELECT
'SELECT * from MySecondDB WHERE ID IN ( '
+ STUFF ( (
SELECT TOP 5
' , ''' + [name] + ''''
FROM dbo.spt_values
FOR XML PATH(''), TYPE).value('(./text())[1]', 'VARCHAR(4000)'
) , 1 , 3, '' )
+ ' ) '
AS SQL_Select
移除前5个,并将[name]和dbo.spt_values替换为您的列和表名称。
然后您可以在下游任务中使用变量SQL_Select,例如针对数据库2的OLE DB源。OLE DB源和OLE DB命令任务都允许您指定变量作为SQL语句来源。
- Mike Honey
1
1谢谢大家。我使用了Hadi的第二个解决方案。 - faujong
0
你可以在这两个服务器之间添加一个LinkedServer。SQL命令可能是这样的:
EXEC sp_addlinkedserver @server='SRV' --or any name you want
EXEC sp_addlinkedsrvlogin 'SRV', 'false', null, 'username', 'password'
SELECT * FROM SRV.CatalogNameInSecondDB.dbo.SecondDBTableName s
INNER JOIN FirstDBTableName f on s.ID = f.ID
WHERE f.ID IN (list of values)
EXEC sp_dropserver 'SRV', 'droplogins'
- Julio Di Polito
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接