我正在尝试使用Power Query中的正则表达式将示例段落拆分为句子:
先生和夫人史密斯以150万美元购买了cheapsite.com,即他花了很多钱。他介意吗?亚当·琼斯博士认为他没有。无论如何,这不是真的...好吧,有90%的概率不是。然而,这行不行。Qr。测试网站.COM和Labs.ORG看起来不错。创意不工作。t和完成。9开始
拆分为:
先生和夫人史密斯以150万美元购买了cheapsite.com,即他花了很多钱。
他介意吗?亚当·琼斯博士认为他没有。
无论如何,这不是真的...
好吧,有90%的概率不是。
然而,这行不行。
Qr。
测试网站。
COM和Labs。
ORG看起来不错。
创意不工作。t和完成。
9开始
先生和夫人史密斯以150万美元购买了cheapsite.com,即他花了很多钱。他介意吗?亚当·琼斯博士认为他没有。无论如何,这不是真的...好吧,有90%的概率不是。然而,这行不行。Qr。测试网站.COM和Labs.ORG看起来不错。创意不工作。t和完成。9开始
拆分为:
先生和夫人史密斯以150万美元购买了cheapsite.com,即他花了很多钱。
他介意吗?亚当·琼斯博士认为他没有。
无论如何,这不是真的...
好吧,有90%的概率不是。
然而,这行不行。
Qr。
测试网站。
COM和Labs。
ORG看起来不错。
创意不工作。t和完成。
9开始
这里是一个函数,使PQ能够使用正则表达式替换:
FnRegexReplace
// regexReplace
let regexReplace=(text as nullable text,pattern as nullable text,replace as nullable text, optional flags as nullable text) as text =>
let
f=if flags = null or flags ="" then "" else flags,
l1 = List.Transform({text, pattern, replace}, each Text.Replace(_, "\", "\\")),
l2 = List.Transform(l1, each Text.Replace(_, "'", "\'")),
t = Text.Format("<script>var txt='#{0}';document.write(txt.replace(new RegExp('#{1}','#{3}'),'#{2}'));</script>", List.Combine({l2,{f}})),
r=Web.Page(t)[Data]{0}[Children]{0}[Children],
Output=if List.Count(r)>1 then r{1}[Text]{0} else ""
in Output
in regexReplace
我还有以下正则表达式,是从之前的帖子中提供的,似乎在Regex101上可以使用。
https://regex101.com/r/WEC0M9/6
模式: (?<!Mr|Mrs|Dr|Jr)(\.+)(\s+(?![a-z])|(?=[A-Z]))
替换为: $1\r\n (我认为这可以是任何东西,如*)
标志: gm
我的问题是,当我尝试在Power Query中执行此操作时,没有返回结果:

或者可以在这里找到,但是仍会出现同样的问题。
该问题似乎与正则表达式中的向后查找和向前查找有关,当删除?函数至少返回结果。如果有人能够建议如何最好地使用正则表达式将此段落拆分,就像PQ中所示,那将是很棒的。
M Code:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("TY9BSwNBDIX/yqPnJVRBiicRetBCD1LBQ+1hdid1Qmcmy0zWpf/e2aLgMXnv5X05Hlf7QnDZY18q4ZDEAnqdvoJhCOzGKsY0aMJZC+7oAUliFM3wGqMrtYMQEwJjdOLhENVuXjHCtm2akiT7J2xb0bN3CTvNXLFrowXJl7pYvPj8Oa3X95sWe82N6IrBVe4WT4XUPxVWJiYifHCMHeaF12Es2rteotgVegY9tvp/IXrRmb+5/F6LkhmzZmtP3DjfGss7V1udTj8=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Column1 = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Column1", type text}}),
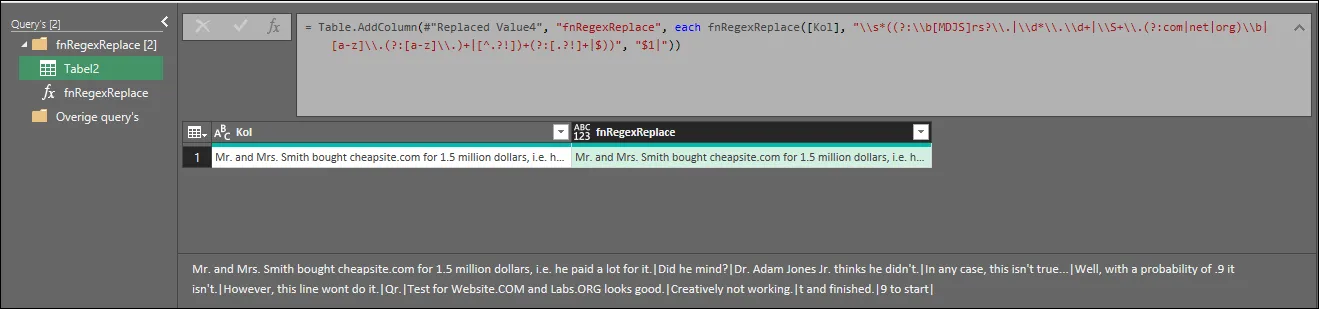
#"Invoked Custom Function" = Table.AddColumn(#"Changed Type", "FnRegexReplace", each FnRegexReplace([Column1], "(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?)\s", "$1\r\n", "gm"))
in
#"Invoked Custom Function"
更新1:使用建议的正则表达式的 M 代码:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("TY9BSwNBDIX/yqPnJVRBiicRetBCD1LBQ+1hdid1Qmcmy0zWpf/e2aLgMXnv5X05Hlf7QnDZY18q4ZDEAnqdvoJhCOzGKsY0aMJZC+7oAUliFM3wGqMrtYMQEwJjdOLhENVuXjHCtm2akiT7J2xb0bN3CTvNXLFrowXJl7pYvPj8Oa3X95sWe82N6IrBVe4WT4XUPxVWJiYifHCMHeaF12Es2rteotgVegY9tvp/IXrRmb+5/F6LkhmzZmtP3DjfGss7V1udTj8=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Column1 = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Column1", type text}}),
#"Invoked Custom Function" = Table.AddColumn(#"Changed Type", "FnRegexReplace", each FnRegexReplace([Column1], "((?:\S+\.(?:net|org|com)\b|\b[mdjs]rs?\.|\d*\.\d+|[a-z]\.(?:[a-z]\.)+|[^?.!])+(?:[.?!]+|$))[?!.\s]*)", "$1\n", "gi"))
in
#"Invoked Custom Function"
Web环境使用的是 JavaScript 正则表达式引擎,不支持向后查找。您还标记了Power BI。在 Power BI 中的 Power Query 可以运行 Python 和 R 脚本,两者都支持不仅包括向后查找,还有 re.split 方法。 - Ron Rosenfeld