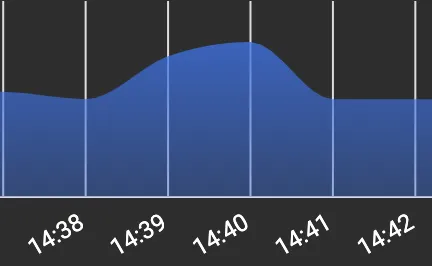
在Kubernetes仪表板上,有一个Pod,其中内存使用量(字节)显示为
该Pod持有使用
我启用了GC日志并在Pod日志中看到以下内容:
Kubernetes如何达到了
904.38Mi。该Pod持有使用
-Xms512m -Xmx1024m运行的Java应用程序,并在Kubernetes部署文件中设置requests.memory = 512M,limits.memory = 1.5G。我启用了GC日志并在Pod日志中看到以下内容:
[2020-04-29T15:41:32.051+0000] GC(1533) Phase 1: Mark live objects
[2020-04-29T15:41:32.133+0000] GC(1533) Phase 1: Mark live objects 81.782ms
[2020-04-29T15:41:32.133+0000] GC(1533) Phase 2: Compute new object addresses
[2020-04-29T15:41:32.145+0000] GC(1533) Phase 2: Compute new object addresses 11.235ms
[2020-04-29T15:41:32.145+0000] GC(1533) Phase 3: Adjust pointers
[2020-04-29T15:41:32.199+0000] GC(1533) Phase 3: Adjust pointers 54.559ms
[2020-04-29T15:41:32.199+0000] GC(1533) Phase 4: Move objects
[2020-04-29T15:41:32.222+0000] GC(1533) Phase 4: Move objects 22.406ms
[2020-04-29T15:41:32.222+0000] GC(1533) Pause Full (Allocation Failure) 510M->127M(680M) 171.359ms
[2020-04-29T15:41:32.222+0000] GC(1532) DefNew: 195639K->0K(195840K)
[2020-04-29T15:41:32.222+0000] GC(1532) Tenured: 422769K->130230K(500700K)
[2020-04-29T15:41:32.222+0000] GC(1532) Metaspace: 88938K->88938K(1130496K)
[2020-04-29T15:41:32.228+0000] GC(1532) Pause Young (Allocation Failure) 603M->127M(614M) 259.018ms
[2020-04-29T15:41:32.228+0000] GC(1532) User=0.22s Sys=0.05s Real=0.26s
Kubernetes如何达到了
904.38Mi的使用量?如果我理解正确,当前使用量仅为:DefNew (young) - 0k
Tenured - 130230K
Metaspace - 88938K
Sum - 216168K
运行ps命令显示除了这个Java应用程序之外,Pod上没有其他进程在运行。
有人能解释一下吗?
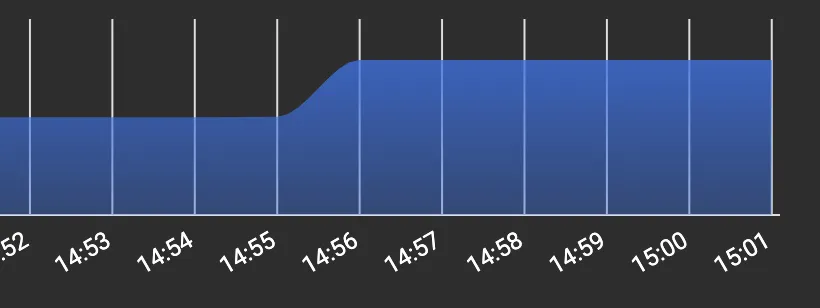
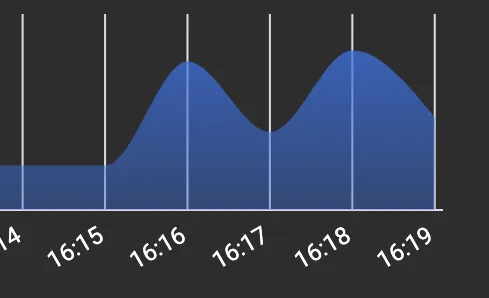
(编辑) 当Pod第一次启动并运行几分钟时,内存使用量显示为约500MB,然后让请求进来,它将突增到900MB-1GB,然后当所有内容都被处理后,尽管基于GC日志堆已经正常地进行了垃圾回收,但是k8s仪表板上的内存使用情况不会降至900MB以下。
free -m命令?它可以告诉你容器实际使用了多少内存,并可能帮助你发现Java进程不知道的泄漏问题。 - Yaron Idanfree -m是无用的。只需尝试在容器内运行docker run -m...,然后执行free -m即可。 - Eugene