我有一个大型数据集,想要对时间重叠的记录进行计数求和。例如,给定以下数据:
[
{"id": 1, "name": 'A', "start": '2018-12-10 00:00:00', "end": '2018-12-20 00:00:00', count: 34},
{"id": 2, "name": 'B', "start": '2018-12-16 00:00:00', "end": '2018-12-27 00:00:00', count: 19},
{"id": 3, "name": 'C', "start": '2018-12-16 00:00:00', "end": '2018-12-20 00:00:00', count: 56},
{"id": 4, "name": 'D', "start": '2018-12-25 00:00:00', "end": '2018-12-30 00:00:00', count: 43}
]
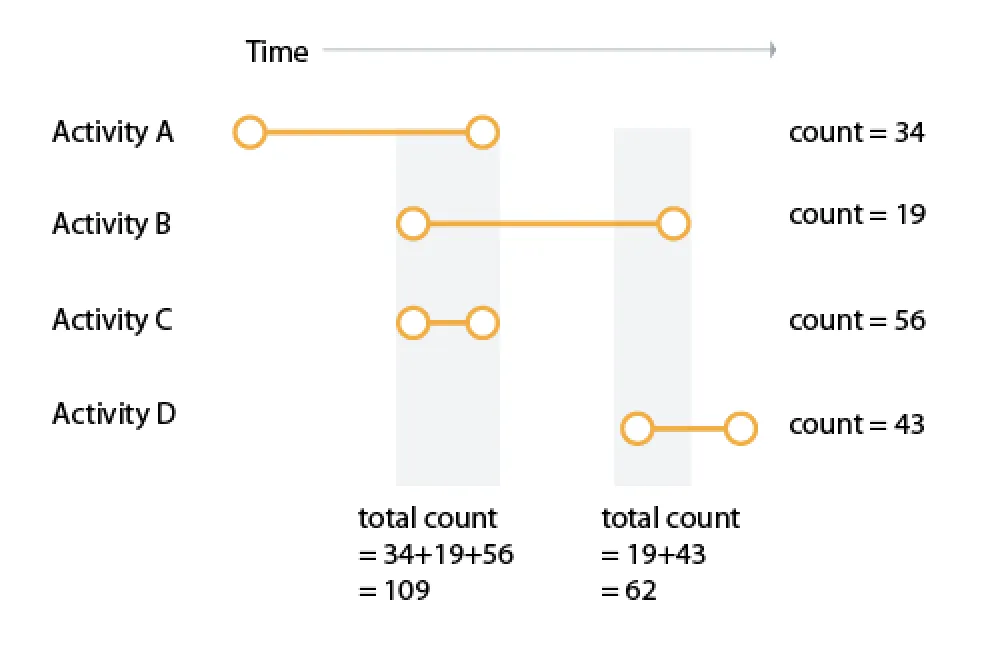
[
{start:'2018-12-16', end: '2018-12-20', overlap_ids:[1,2,3], total_count: 109},
{start:'2018-12-25', end: '2018-12-27', overlap_ids:[2,4], total_count: 62},
]
问题是,如何通过postgres查询生成这个?我正在研究generate_series然后计算每个区间的活动,但那不是很正确,因为数据是连续的 - 我真的需要确定重叠时间,然后对重叠的活动进行求和。
编辑已添加另一个示例。正如@SRack指出的那样,由于A、B、C重叠,这意味着B、C A、B和A、C也重叠。这并不重要,因为我要找的输出是包含重叠活动的日期范围数组,而不是所有重叠组合的唯一组合。还请注意,日期是时间戳,因此将具有毫秒精度,并且不一定全部在00:00:00。如果有帮助的话,可能会对总计数设置WHERE条件。例如,只想看到总计数> 100的结果