你描述了一棵带有叶子节点数据的树,称其为“不好的列表替代品”。
我认为这可以作为列表的替代品,但不一定设计得不好!请考虑数据类型。
data Tree t = Leaf t | Branch (Tree t) (Tree t)
您可以定义
cons和
snoc(在列表末尾追加)操作。
cons :: t -> Tree t -> Tree t
cons t (Leaf s) = Branch (Leaf t) (Leaf s)
cons t (Branch l r) = Branch (cons t l) r
snoc :: Tree t -> t -> Tree t
snoc (Leaf s) t = Branch (Leaf s) (Leaf t)
snoc (Branch l r) t = Branch l (snoc r t)
对于大致平衡的列表,这些操作的运行时间为O(log n),其中n是列表的长度。这与标准链表形成对比,标准链表具有O(1)的cons和O(n)的snoc操作。您还可以定义一个常数时间的append(例如templatetypedef的回答中所述)。
append :: Tree t -> Tree t -> Tree t
append l r = Branch l r
对于任意长度的两个列表,其时间复杂度为O(1),而标准列表的时间复杂度为O(n),其中n是左参数的长度。
实际上,您需要定义稍微智能一些的这些函数的版本,以尝试保持树的平衡。为此,通常有必要在分支处添加一些额外的信息,可以通过具有多种类型的分支(如具有“红色”和“黑色”节点的红黑树)或显式地在分支处包含其他数据来实现。
data Tree b a = Leaf a | Branch b (Tree b a) (Tree b a)
例如,您可以通过在节点中存储两个子树中元素的总数来支持O(1)的
size操作。由于需要正确地保留有关子树大小的信息,因此树上的所有操作都变得更加复杂 - 实际上,计算树的大小的工作在构造树的所有操作上分摊(并且巧妙地持久化,以便在稍后需要重建大小时最小化工作量)。
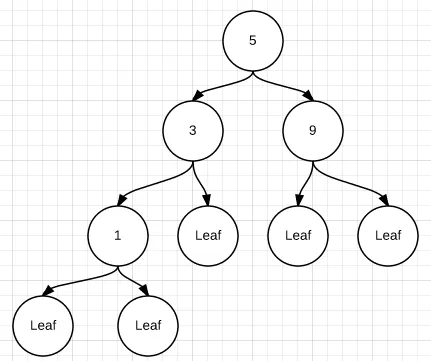
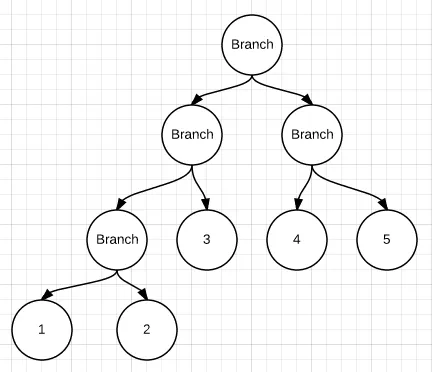
Data.IntMap是后一种形式(仅在叶子节点上有数据),而Data.Map是前一种形式。为什么要同时拥有这两个呢?文档中这样说:“[IntMap] 在联合和交集等二进制操作上表现特别好。然而,我的基准测试显示,与 [Data.Map] 相比,在插入和删除时它也(更)快。”最后,我不会说第二个版本“更为普遍”。 - user2407038