我想在这里提一下一些东西,之前我花了很长时间进行实验,最后才意识到发生了什么。这对于这里的每个人来说可能是如此明显,以至于他们没有提及它。但如果他们这样做了,那会帮助我,所以根据这个原则...!
注意:我专门使用
Jython,版本为 2.7,因此这可能不适用于
CPython...
注意2:我这里的 .py 文件的前两行是:
from __future__ import print_function
"
“%”(也称为“插值运算符”)字符串构造机制也会导致其他问题...如果“环境”的默认编码是ASCII,并且您尝试执行以下操作
"
print( "bonjour, %s" % "fréd" ) # Call this "print A"
您在 Eclipse 中运行时不会遇到任何困难... 在 Windows 命令行界面(DOS 窗口)中,您会发现编码方式为
代码页 850(我的 Windows 7 操作系统)或类似的编码方式,它至少可以处理欧洲重音字符,因此它能够正常工作。
print( u"bonjour, %s" % "fréd" ) # Call this "print B"
也可以工作。
然而,如果您从CLI直接引用文件,则stdout编码将为None,这将默认为ASCII(在我的操作系统上),无法处理上述任何一种打印方式...(可怕的编码错误)。
因此,您可以考虑使用重定向您的stdout:
sys.stdout = codecs.getwriter('utf8')(sys.stdout)
尝试在CLI中运行并将其导出到文件中...非常奇怪的是,上面的print A可以正常工作...但是上面的print B会抛出编码错误!然而,以下内容将可以正常工作:
print( u"bonjour, " + "fréd" ) # Call this "print C"
我得出的(暂定)结论是,如果一个字符串被指定为使用“u”前缀的
Unicode字符串,并提交给%处理机制,它似乎涉及使用默认环境编码,
无论是否设置了stdout重定向!
人们如何处理这个问题是个选择问题。我希望一个Unicode专家能说一下为什么会发生这种情况,我是否以某种方式搞错了,这个问题的首选解决方案是什么,它是否也适用于
CPython,它是否在Python 3中发生等等。
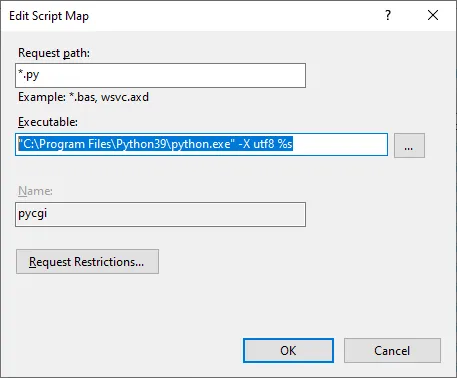
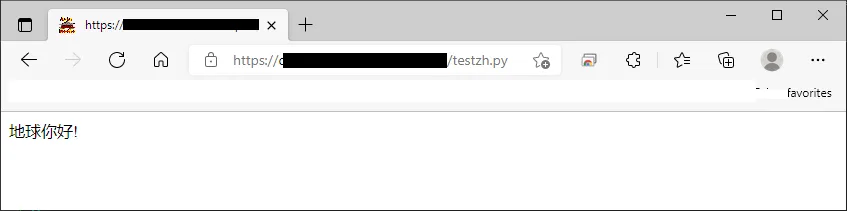
chcp 65001。这可能会有一些问题,但通常有帮助作用,并且不需要输入太多文字(少于set PYTHONIOENCODING=utf_8)。 - Tomasz Gandor