给定一个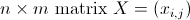 ,我们首先定义两个实值函数
,我们首先定义两个实值函数 和
和 ,如下所示:
,如下所示:
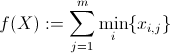
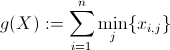 我们还定义每个矩阵的值
我们还定义每个矩阵的值
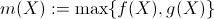 现在,给定一个
现在,给定一个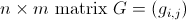 ,我们有许多区域
,我们有许多区域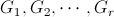 。这里,
。这里,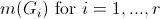 。是否有像构建哈希表或排序之类的方法来更快地获得结果?谢谢!
。是否有像构建哈希表或排序之类的方法来更快地获得结果?谢谢!
========================
例如,如果
,我们首先定义两个实值函数和,如下所示:
我们还定义每个矩阵的值m(X)如下:
现在,给定一个,我们有许多区域G,表示为。这里,G的一个区域由G的一些列和一些行中随机选择的子矩阵组成。我们的问题是尽可能少地计算。是否有像构建哈希表或排序之类的方法来更快地获得结果?谢谢!========================
例如,如果
G = {{1,2,3},{4,5,6},{7,8,9}},则G_1 could be {{1,2},{7,8}}
G_2 could be {{1,3},{4,6},{7,9}}
G_3 could be {{5,6},{8,9}}
=======================
目前,对于每个G_i,我们需要进行mxn次比较来计算m(G_i)。因此,对于m(G_1),...,m(G_r),应该进行rxmxn次比较。然而,我注意到G_i和G_j可能重叠,因此可能存在其他更有效的方法。非常感谢您的关注!