我有一个随机递归回溯算法来生成数独(请参见这里)。平均而言,它的速度足够快,但最坏情况下的运行时间过长。以下是100次试验中运行时间的毫秒数的直方图("More"大约为200,000ms!):
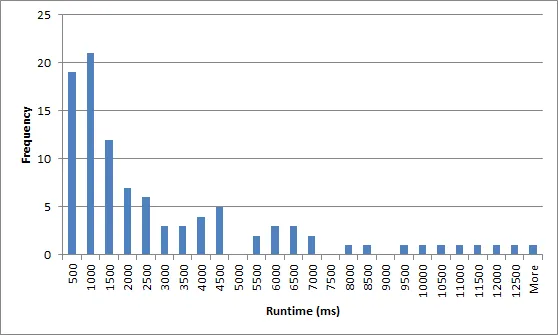
我想通过简单地在 ms后超时并使用新的随机种子重新启动来改进算法。为了防止无限重复,我将在n次尝试后停止,或在每次失败尝试后增加。如果远大于中位数,则有很大的机会在随后的尝试中获得更快的运行。
问题:
- 如何调整不同处理器的超时期?是否有一种快速可靠的方法来在每次运行之前对处理器性能进行基准测试?或者,我应该适应处理器,在此过程中使用所有先前运行的平均运行时间?我在Android上运行此操作,如果相关的话。
- 是否存在更好的策略以避免运行时间分布中的长尾巴?