这个场景基于另一个问题的架构,我不感兴趣讨论架构的有效性!
我想知道在SQL Server中是否有任何好的技术,可以根据另一列(id1)的不同值对一列(amount1)进行聚合。
Plan1扫描了table1两次,通过p_id进行两次聚合,然后将结果连接起来。似乎这可以得到改进。查询2在某些情况下可能会返回错误的结果,并且计划也更糟糕!
有什么想法吗?
DDL
IF OBJECT_ID('tempdb..#table1') IS NOT NULL DROP TABLE #table1;
IF OBJECT_ID('tempdb..#table2') IS NOT NULL DROP TABLE #table2;
CREATE TABLE #table1 (id1 int primary key nonclustered, amount1 int, p_id int);
CREATE CLUSTERED INDEX ix ON #table1 (p_id,id1);
INSERT INTO #table1
SELECT 1,500,10 UNION ALL
SELECT 2,700,20 UNION ALL
SELECT 3,500,10 UNION ALL
SELECT 4,450,20 UNION ALL
SELECT 5,300,10;
CREATE TABLE #table2 (id2 int primary key, amount2 int, id1 int);
INSERT INTO #table2
SELECT 1,300,1 UNION ALL
SELECT 2,200,1 UNION ALL
SELECT 3,200,2 UNION ALL
SELECT 4,500,2 UNION ALL
SELECT 5,400,3 UNION ALL
SELECT 6,150,4 UNION ALL
SELECT 7,300,4 UNION ALL
SELECT 8,300,5;
查询1
WITH t1
AS (SELECT p_id,SUM(amount1) AS total1
FROM #table1
GROUP BY p_id),
t2
AS (SELECT p_id,SUM(amount2) AS total2
FROM #table2 table2
JOIN #table1 table1
ON table1.id1 = table2.id1
GROUP BY p_id)
SELECT t1.p_id,total1,total2
FROM t1
JOIN t2
ON t1.p_id = t2.p_id
计划1
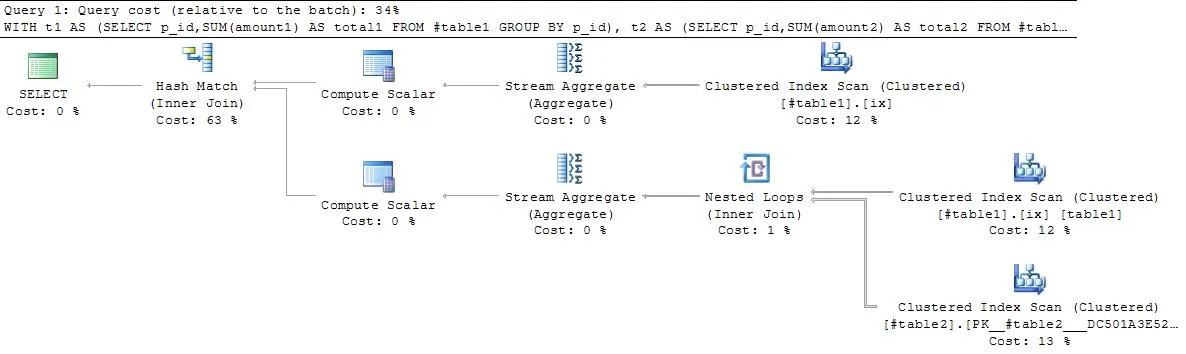
查询2
SELECT table1.p_id,
FLOOR(SUM(DISTINCT amount1 + table1.id1/100000000.0)) AS total1,
SUM(amount2) AS total2
FROM #table1 table1 JOIN #table2 table2 ON table1.id1=table2.id1
GROUP BY table1.p_id
计划 2
