我来自Java背景,正在学习Haskell。在编写Java代码时,我感觉对对象在内存中的布局以及其相关后果有着深刻理解。例如,我精确知道java.lang.String和java.util.LinkedList是如何工作的,因此我知道应该如何使用它们。但是在Haskell中,我有些迷茫。例如,(:)是如何工作的?我应该关心吗?是否有规定说明它的用法呢?
我需要了解Haskell如何表示数据才能编写良好的Haskell程序吗?
9
- AdamStevenson
4
这是一个好问题,因为我见过人们为了这个原因在值前加上!。 - Robert Massaioli
2通常情况下,您也不需要了解Java类的内部结构(解耦、信息隐藏、封装等)。 - musiKk
@musiKk 我同意你不应该需要阅读源代码,但我认为了解某个东西的实现方式会有所帮助。例如,LinkedList和ArrayList之间的区别很容易理解,因为它们的名称强烈暗示了实现方式,我不必查阅文档才能发现一个方法是O(1)还是O(n)或其他什么。如果你只给我一个List,我不知道操作的性能如何,除非我阅读文档。 - AdamStevenson
1在Haskell中,所有的数据都被定义为向外展开的树形结构...因此,对于实现简单列表来说,有一个非常明显的选择:单向链表。如果你在各种类型的单子内工作,可以使用可变数组进行操作,但这是一个相当高级的话题。 - Tom Crockett
2个回答
11
简短回答是不需要。在Haskell编程中,您应该将数据结构视为纯数学对象,而不必担心它们在内存中的表示方式。这是因为,在没有副作用的情况下,除了创建数据的函数和从中提取构成它的简单部分的函数之外,真的没有任何与数据有关的东西。
要查看有关数据构造函数(如(:))或任何其他术语的信息,请在GHCi中使用:type(或者缩写为:t)命令。
要查看有关数据构造函数(如(:))或任何其他术语的信息,请在GHCi中使用:type(或者缩写为:t)命令。
:Prelude> :type (:)
(:) :: a -> [a] -> [a]
这告诉你,(:) 构造函数(读作“cons”)接受任何类型的值和相同类型的列表,并返回相同类型的列表。您还可以通过使用 :info 命令获取更多信息。这将显示数据定义的外观:
Prelude> :info (:)
data [] a = ... | a : [a] -- Defined in GHC.Types
infixr 5 :
这告诉你(:)是构造函数,它将元素添加到现有列表中。
我强烈推荐使用Hoogle,不仅可以通过名称查找内容,还可以进行相反类型的搜索;您知道要查找的函数的签名,并想找出是否已经有人为您编写了该函数。 Hoogle很好用,因为它提供描述和示例用法。
归纳数据的形状
我上面说过,知道数据在内存中的表示方式并不重要... 但是,您应该了解正在处理的数据的形状,以避免做出性能差的决策。 Haskell中的所有数据都是归纳定义的,意味着它具有类似树形的形状,可以递归地展开。您可以通过查看其定义来确定数据的形状;一旦您知道如何阅读此内容,那么关于其性能特征就真的没有什么隐藏的东西了:
data MyList a = Nil | Cons a (MyList a)
从定义中可以看出,获得新的MyList的唯一方式是使用Cons构造函数。如果您多次使用此构造函数,最终会得到大致如下形状的内容:
(Cons a5 (Cons a4 (Cons a3 (Cons a2 (Cons a1 Nil)))))
列表就是一棵没有分支的树!访问最后一个元素的唯一方法是逐个弹出每个Cons,因此访问最后一个元素的时间复杂度为O(n),而访问头部的时间复杂度为常数时间。一旦你能够根据数据结构的定义进行这种推理,你就可以了解它们。
- Tom Crockett
3
+1 给 Hoogle。每个 Haskell 程序员都应该知道并使用它。这是一个很棒的工具。 - musiKk
1值得一提的是,一个只在一个地方使用的值(例如列表)通常(?总是?)实际上并不存在 --- 生产和消费函数会被合并在一起,列表表示将被跳过。 - dave4420
绝对精彩的描述。 - Marc W
2
简短回答是“不需要”,你不需要了解数据布局,但了解复杂度的知识会很有用。
然而,要编写高度优化的Haskell程序,对堆中数据结构的形状有良好的工作知识是必不可少的。一个帮助的工具是“vacuum”,它可以呈现Haskell数据结构的图表,以展示它们的布局。
以下是一些例子:
$ view "hello"
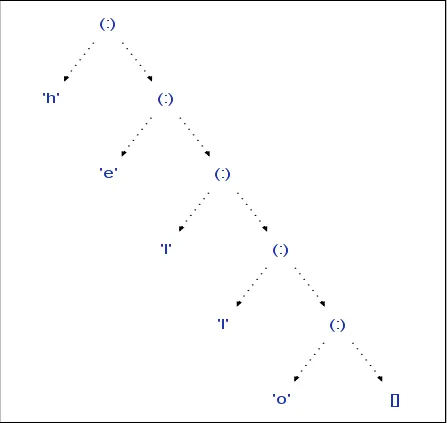
$ view (IntMap.fromList $ zip [1..10] [1..])
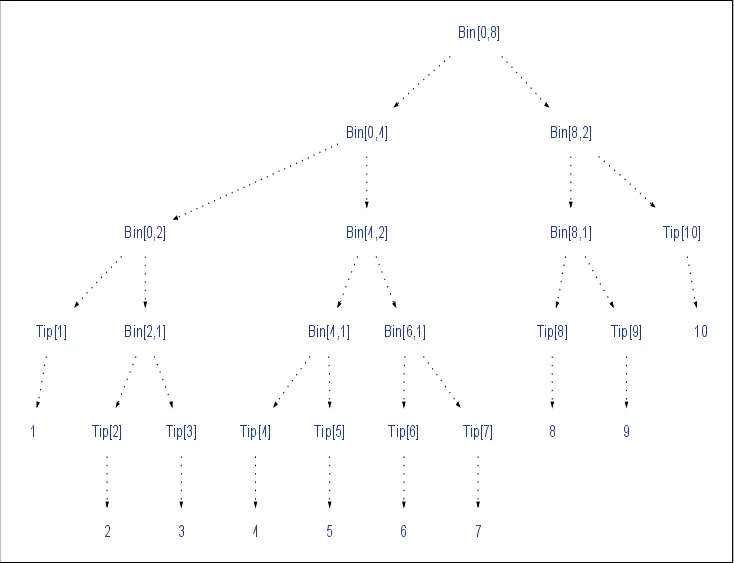
这是一个使用IT技术的工具,以下是使用方法的简短视频:http://www.youtube.com/watch?v=X4-212uMgy8
- Don Stewart
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接