我发布这个问题是因为许多开发者以不同的形式提出了类似的问题。我将亲自回答这个问题(我是iText Group的创始人/CTO),以便它成为一个“维基答案”。如果Stack Overflow的“文档”功能仍然存在,那么这将是一个很好的文档主题候选。
源文件:
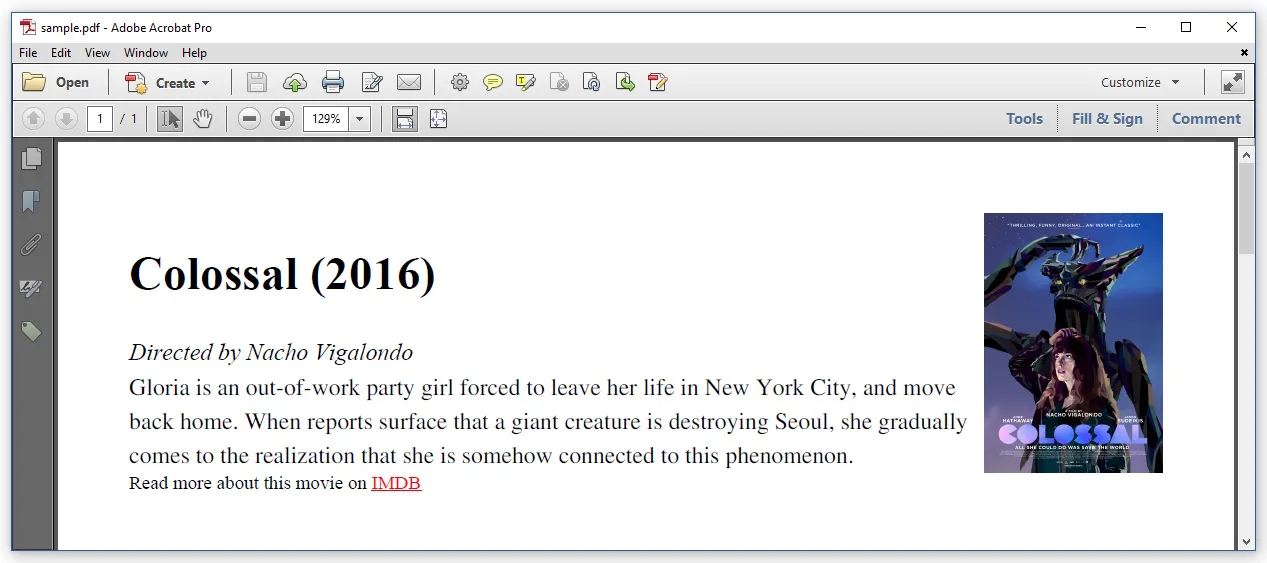
我正在尝试将以下HTML文件转换为PDF:
<html>
<head>
<title>Colossal (movie)</title>
<style>
.poster { width: 120px;float: right; }
.director { font-style: italic; }
.description { font-family: serif; }
.imdb { font-size: 0.8em; }
a { color: red; }
</style>
</head>
<body>
<img src="img/colossal.jpg" class="poster" />
<h1>Colossal (2016)</h1>
<div class="director">Directed by Nacho Vigalondo</div>
<div class="description">Gloria is an out-of-work party girl
forced to leave her life in New York City, and move back home.
When reports surface that a giant creature is destroying Seoul,
she gradually comes to the realization that she is somehow connected
to this phenomenon.
</div>
<div class="imdb">Read more about this movie on
<a href="www.imdb.com/title/tt4680182">IMDB</a>
</div>
</body>
</html>
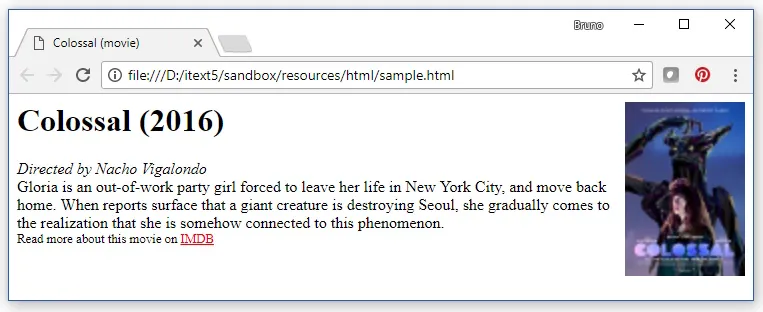
在浏览器中,这个HTML看起来像这样:
我遇到的问题:
HTMLWorker完全不考虑CSS
当我使用HTMLWorker时,我需要创建一个ImageProvider以避免出现“找不到图像”的错误。我还需要创建一个StyleSheet实例来更改一些样式:
public static class MyImageFactory implements ImageProvider {
public Image getImage(String src, Map<String, String> h,
ChainedProperties cprops, DocListener doc) {
try {
return Image.getInstance(
String.format("resources/html/img/%s",
src.substring(src.lastIndexOf("/") + 1)));
} catch (DocumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
public static void main(String[] args) throws IOException, DocumentException {
Document document = new Document();
PdfWriter.getInstance(document, new FileOutputStream("results/htmlworker.pdf"));
document.open();
StyleSheet styles = new StyleSheet();
styles.loadStyle("imdb", "size", "-3");
HTMLWorker htmlWorker = new HTMLWorker(document, null, styles);
HashMap<String,Object> providers = new HashMap<String, Object>();
providers.put(HTMLWorker.IMG_PROVIDER, new MyImageFactory());
htmlWorker.setProviders(providers);
htmlWorker.parse(new FileReader("resources/html/sample.html"));
document.close();
}
结果看起来像这样:
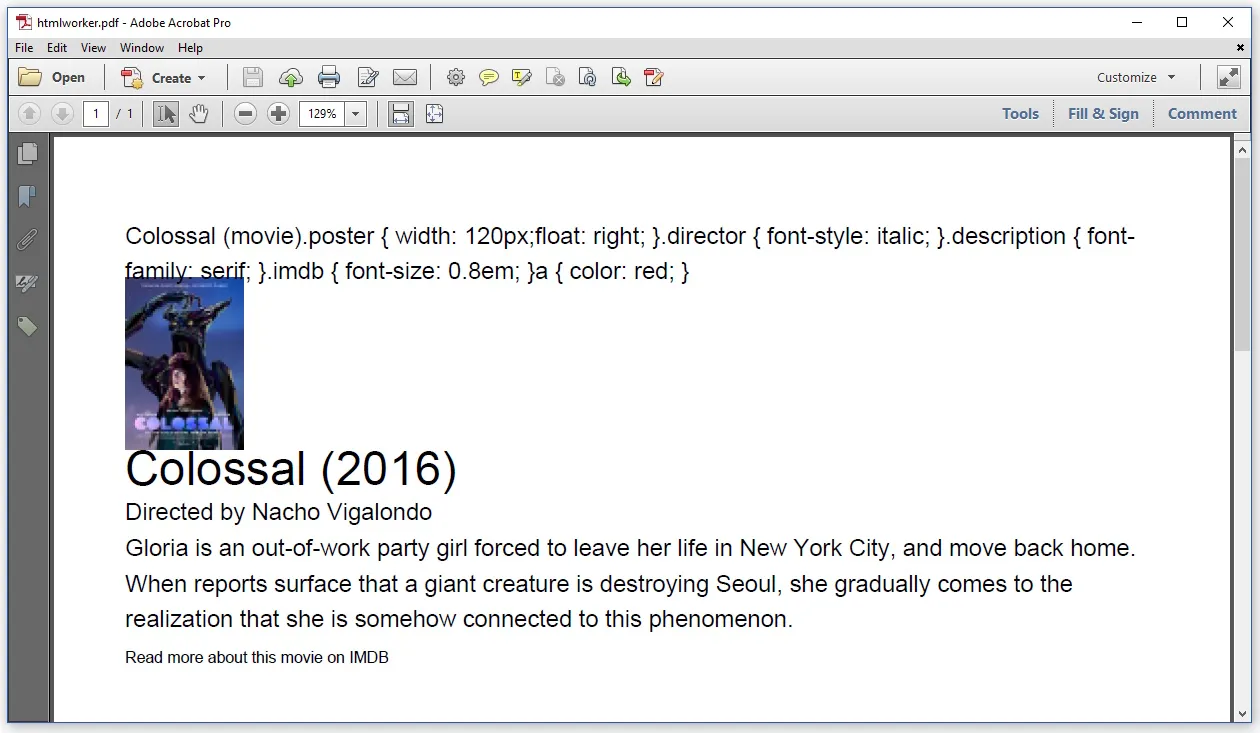
由于某种原因,HTMLWorker还显示了<title>标签的内容。我不知道如何避免这种情况。头部中的 CSS 根本没有被解析, 我必须在代码中定义所有的样式使用 StyleSheet 对象。
当我查看我的代码时,我发现我正在使用的许多对象和方法已经被弃用:

因此,我决定升级到使用 XML Worker。
在使用 XML Worker 时找不到图片
我尝试了以下代码:
public static final String DEST = "results/xmlworker1.pdf";
public static final String HTML = "resources/html/sample.html";
public void createPdf(String file) throws IOException, DocumentException {
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(file));
document.open();
XMLWorkerHelper.getInstance().parseXHtml(writer, document,
new FileInputStream(HTML));
document.close();
}
这导致产生了以下的PDF文件:
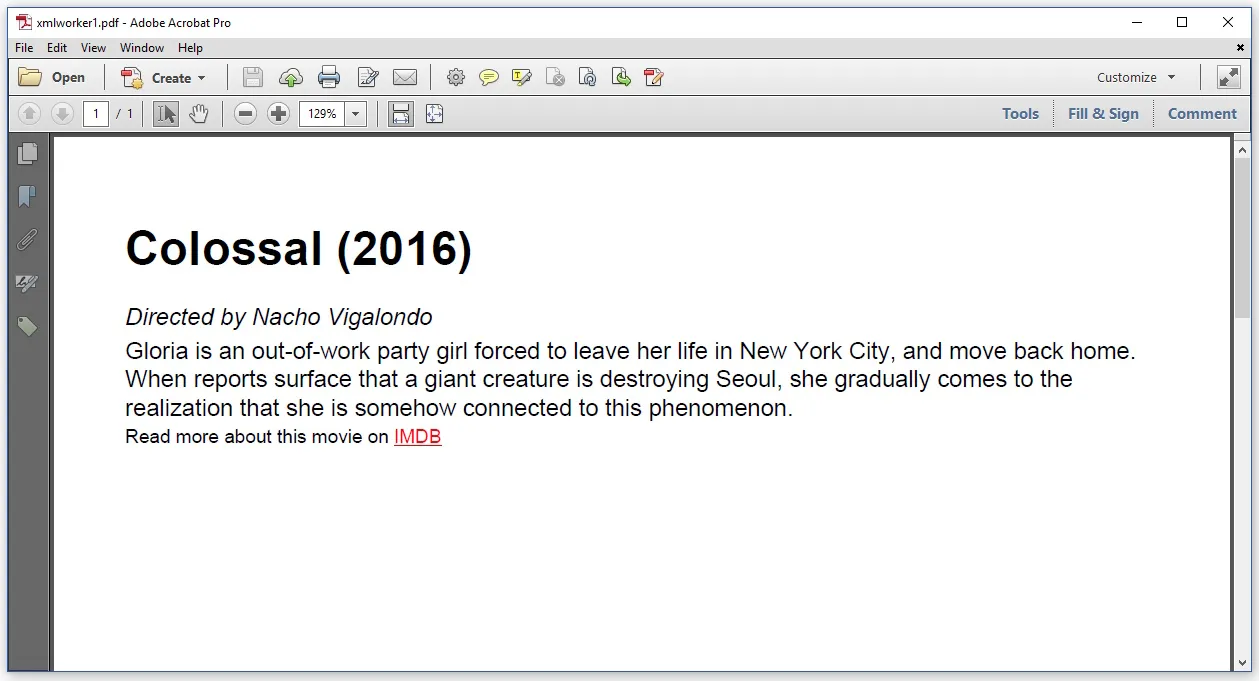
默认字体Helvetica被用来代替Times-Roman;这是iText的典型特征(我应该在HTML中显式定义字体)。除此之外,CSS似乎被正确处理,但图片丢失了,而我也没有收到错误信息。
使用HTMLWorker时,会抛出一个异常,通过引入ImageProvider,我成功解决了这个问题。现在我们看看是否适用于XML Worker。
并非所有的CSS样式都受到XML Worker的支持
我修改了我的代码如下:
public static final String DEST = "results/xmlworker2.pdf";
public static final String HTML = "resources/html/sample.html";
public static final String IMG_PATH = "resources/html/";
public void createPdf(String file) throws IOException, DocumentException {
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(file));
document.open();
CSSResolver cssResolver =
XMLWorkerHelper.getInstance().getDefaultCssResolver(true);
HtmlPipelineContext htmlContext = new HtmlPipelineContext(null);
htmlContext.setTagFactory(Tags.getHtmlTagProcessorFactory());
htmlContext.setImageProvider(new AbstractImageProvider() {
public String getImageRootPath() {
return IMG_PATH;
}
});
PdfWriterPipeline pdf = new PdfWriterPipeline(document, writer);
HtmlPipeline html = new HtmlPipeline(htmlContext, pdf);
CssResolverPipeline css = new CssResolverPipeline(cssResolver, html);
XMLWorker worker = new XMLWorker(css, true);
XMLParser p = new XMLParser(worker);
p.parse(new FileInputStream(HTML));
document.close();
}
代码长度增加了,但是现在图像被渲染出来了:
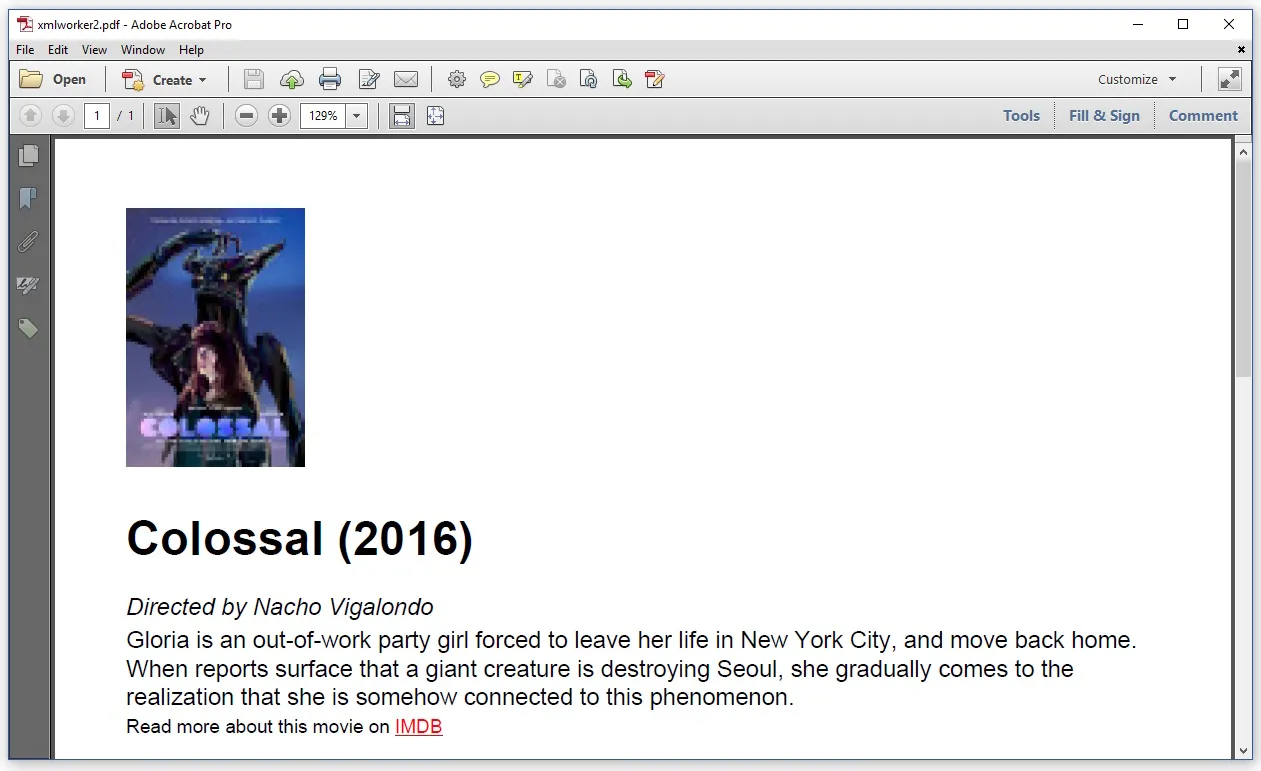
这张图片比我使用HTMLWorker渲染时要大, 这告诉我类poster的CSS属性width 被考虑进去了,但是float属性被忽略了。我该如何解决这个问题?
剩下的问题:
所以问题归结为这样: 我有一个特定的HTML文件,我想把它转换成PDF。我经历了很多的工作,一个接一个地解决问题,但有一个特定的问题我无法解决:如何让iText尊重定义元素位置(例如float:right)的CSS?
额外的问题:
当我的HTML包含表单元素(如<input>),这些表单元素会被忽略。