我目前正在一个关于从维基百科FR的Acadie门户提取定性和定量(统计)数据的项目中工作。总共有1905个条目需要处理,其中包含16个变量。
每次使用以下代码加载所有统计数据时,需要一些时间才能加载完毕。 有没有一种方法可以将这个数据框保存在我的电脑上,并在将来快速加载它,同时保持其组织结构不变?
# Basic information ----
library("WikipediR")
# Function
# How to make function outside of apply: https://ademos.people.uic.edu/Chapter4.html#:~:targetText=vapply%20is%20similar%20to%20sapply,VALUE).&targetText=VALUE%20is%20where%20you%20specify,single%20numeric%20value%2C%20so%20FUN.
pageInfo_fun <- function(portalAcadie_titles){
page_info(language = "fr",
project = "wikipedia",
page = portalAcadie_titles,
properties = c("url"),
clean_response = T, Sys.sleep(0.0001))} # Syssleep to prevent quote violation.
pageInfo_data <- apply(portalAcadie_titles,1, pageInfo_fun)
# Transform into dataframe
library("tidyverse")
pageInfo_df <- data.frame(map_dfr(pageInfo_data, ~flatten(.)))
这给了我一个可行的数据框,看起来像这样:
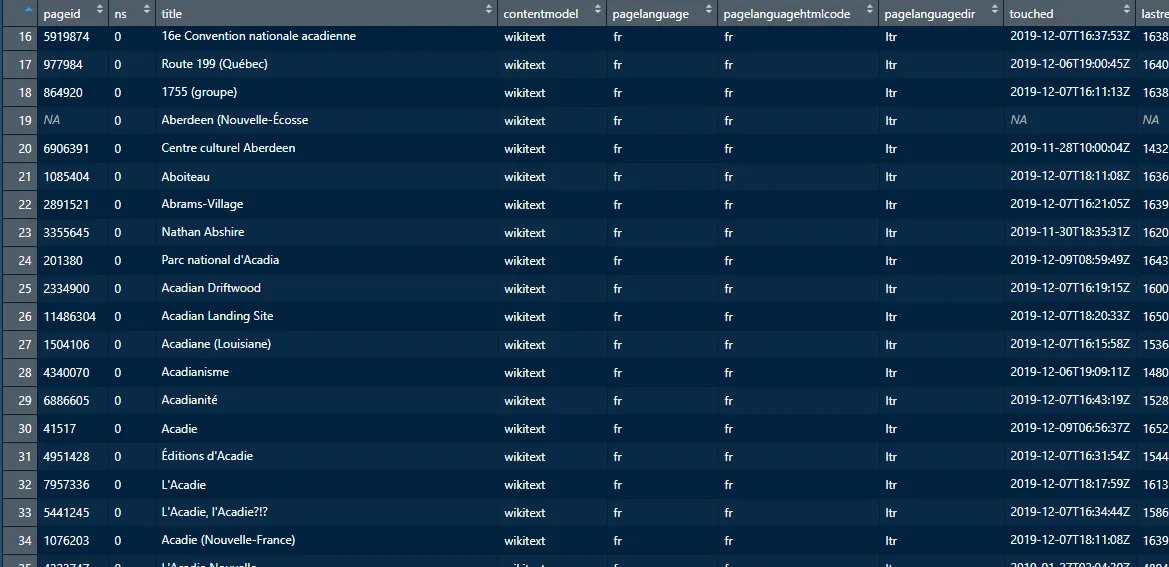
当我尝试将它保存为csv文件并使用ff包和read.csv.ffdf()时,它没有给我一个可行的数据框。它将所有变量和观察值合并到一个观察值中,其中包含大约20,000个变量。