例如,给定列表
['one', 'two', 'one'],该算法应返回True,而给定['one', 'two', 'three']则应返回False。['one', 'two', 'one'],该算法应返回True,而给定['one', 'two', 'three']则应返回False。如果所有的值都是可哈希的,可以使用set()来去除重复项:
>>> your_list = ['one', 'two', 'one']
>>> len(your_list) != len(set(your_list))
True
仅推荐用于短列表:
any(thelist.count(x) > 1 for x in thelist)
不要在长列表上使用此方法——它的执行时间与列表中项目数量的平方成正比!
对于具有可哈希项(例如字符串、数字等)的较长列表:
def anydup(thelist):
seen = set()
for x in thelist:
if x in seen: return True
seen.add(x)
return False
如果你的项目不可哈希(子列表、字典等),那么情况会更加复杂,尽管如果它们是可比较的,仍然可能实现O(N logN)。但你需要知道或测试项目的特征(可哈希或不可哈希,可比较或不可比较),以获得最佳的性能--对于可哈希的,为O(N),对于非可哈希的可比较的,为O(N log N),否则就只能跌至O(N平方),这时就无能为力了:-(。
all 操作)。您也提到了一个所有值都为 True 的字典,它是一个荒谬、无用的模拟“集合”,根本没有任何附加价值。在编程中,大 O 并不是一切。 - Alex Martelliset.__contains__(4.42微秒/256次调用,占用2.55%的时间)比list.__contains__(173.00微秒/256次调用,占用100%的时间)快得多,以至于即使向集合中添加项目的开销比列表追加项目更慢,使用set.add而不是list.append也是值得的。在这里要果断使用集合而不是列表,对于非常大的列表,我放弃了,因为一个集合只需要几秒钟就能完成。 - ThorSummoner我认为比较这里提出的不同解决方案的时间很有用。为此,我使用了自己的库simple_benchmark:
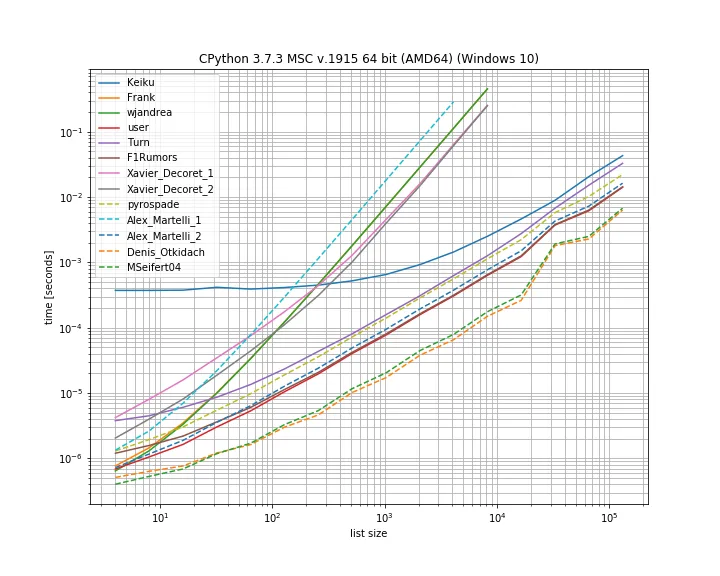
因此,在这种情况下,Denis Otkidach的解决方案最快。
一些方法还表现出更陡峭的曲线,这些是随元素数量平方缩放的方法(Alex Martellis第一个解决方案,wjandrea和Xavier Decorets的两个解决方案)。还要提到的是,Keiku的pandas解决方案具有非常大的常数因子。但对于更大的列表,它几乎赶上了其他解决方案。
而且,如果重复项位于第一个位置。 这很有用,可以看到哪些解决方案是短路的:
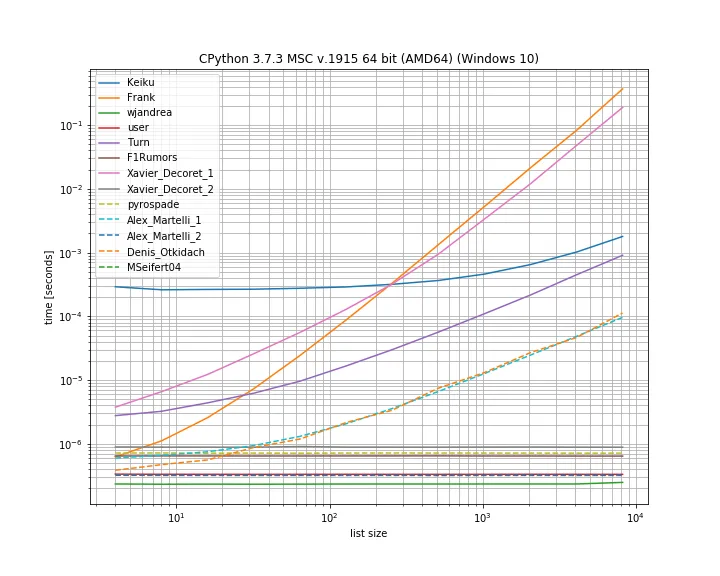
这里有几种方法不会短路:Kaiku,Frank,Xavier_Decoret(第一个解决方案),Turn,Alex Martelli(第一个解决方案)以及由Denis Otkidach提出的方法(在无重复的情况下最快)。
我在这里包括了来自我的库的一个函数:iteration_utilities.all_distinct,它可以在没有重复的情况下与最快的解决方案竞争,并在重复在开始时以常数时间执行(尽管不是最快)。
基准测试的代码:
from collections import Counter
from functools import reduce
import pandas as pd
from simple_benchmark import BenchmarkBuilder
from iteration_utilities import all_distinct
b = BenchmarkBuilder()
@b.add_function()
def Keiku(l):
return pd.Series(l).duplicated().sum() > 0
@b.add_function()
def Frank(num_list):
unique = []
dupes = []
for i in num_list:
if i not in unique:
unique.append(i)
else:
dupes.append(i)
if len(dupes) != 0:
return False
else:
return True
@b.add_function()
def wjandrea(iterable):
seen = []
for x in iterable:
if x in seen:
return True
seen.append(x)
return False
@b.add_function()
def user(iterable):
clean_elements_set = set()
clean_elements_set_add = clean_elements_set.add
for possible_duplicate_element in iterable:
if possible_duplicate_element in clean_elements_set:
return True
else:
clean_elements_set_add( possible_duplicate_element )
return False
@b.add_function()
def Turn(l):
return Counter(l).most_common()[0][1] > 1
def getDupes(l):
seen = set()
seen_add = seen.add
for x in l:
if x in seen or seen_add(x):
yield x
@b.add_function()
def F1Rumors(l):
try:
if next(getDupes(l)): return True # Found a dupe
except StopIteration:
pass
return False
def decompose(a_list):
return reduce(
lambda u, o : (u[0].union([o]), u[1].union(u[0].intersection([o]))),
a_list,
(set(), set()))
@b.add_function()
def Xavier_Decoret_1(l):
return not decompose(l)[1]
@b.add_function()
def Xavier_Decoret_2(l):
try:
def func(s, o):
if o in s:
raise Exception
return s.union([o])
reduce(func, l, set())
return True
except:
return False
@b.add_function()
def pyrospade(xs):
s = set()
return any(x in s or s.add(x) for x in xs)
@b.add_function()
def Alex_Martelli_1(thelist):
return any(thelist.count(x) > 1 for x in thelist)
@b.add_function()
def Alex_Martelli_2(thelist):
seen = set()
for x in thelist:
if x in seen: return True
seen.add(x)
return False
@b.add_function()
def Denis_Otkidach(your_list):
return len(your_list) != len(set(your_list))
@b.add_function()
def MSeifert04(l):
return not all_distinct(l)
而对于这些参数:
# No duplicate run
@b.add_arguments('list size')
def arguments():
for exp in range(2, 14):
size = 2**exp
yield size, list(range(size))
# Duplicate at beginning run
@b.add_arguments('list size')
def arguments():
for exp in range(2, 14):
size = 2**exp
yield size, [0, *list(range(size)]
# Running and plotting
r = b.run()
r.plot()
这篇文章有点旧,但是这里的回答启发了我找到了一个稍微不同的解决方案。如果你准备好滥用Python的推导式,你可以通过这种方法实现短路。
xs = [1, 2, 1]
s = set()
any(x in s or s.add(x) for x in xs)
# You can use a similar approach to actually retrieve the duplicates.
s = set()
duplicates = set(x for x in xs if x in s or s.add(x))
如果您喜欢函数式编程风格,这里有一个有用的函数,使用doctest进行自文档和测试的代码。
def decompose(a_list):
"""Turns a list into a set of all elements and a set of duplicated elements.
Returns a pair of sets. The first one contains elements
that are found at least once in the list. The second one
contains elements that appear more than once.
>>> decompose([1,2,3,5,3,2,6])
(set([1, 2, 3, 5, 6]), set([2, 3]))
"""
return reduce(
lambda (u, d), o : (u.union([o]), d.union(u.intersection([o]))),
a_list,
(set(), set()))
if __name__ == "__main__":
import doctest
doctest.testmod()
您可以通过检查返回的一对中的第二个元素是否为空来测试唯一性:
def is_set(l):
"""Test if there is no duplicate element in l.
>>> is_set([1,2,3])
True
>>> is_set([1,2,1])
False
>>> is_set([])
True
"""
return not decompose(l)[1]
def is_set(l):
try:
def func(s, o):
if o in s:
raise Exception
return s.union([o])
reduce(func, l, set())
return True
except:
return False
def getDupes(l):
seen = set()
seen_add = seen.add
for x in l:
if x in seen or seen_add(x):
yield x
list(getDupes(etc))。要仅测试是否存在重复项,应按以下方式进行包装:def hasDupes(l):
try:
if getDupes(l).next(): return True # Found a dupe
except StopIteration:
pass
return False
def getDupes(c):
d = {}
for i in c:
if i in d:
if d[i]:
yield i
d[i] = False
else:
d[i] = True
利用itertools(实质上是ifilter/izip/tee)在排序列表上,如果您获取所有重复项,则非常高效,但仅获取第一个则不太快:
def getDupes(c):
a, b = itertools.tee(sorted(c))
next(b, None)
r = None
for k, g in itertools.ifilter(lambda x: x[0]==x[1], itertools.izip(a, b)):
if k != r:
yield k
r = k
这些是我尝试过的方法中在完全重复列表中表现最佳的,第一个重复项出现在从开头到中间的100万个元素列表中的任何位置。令人惊讶的是,排序步骤增加的开销很少。您的情况可能有所不同,但以下是我的具体计时结果:
Finding FIRST duplicate, single dupe places "n" elements in to 1m element array
Test set len change : 50 - . . . . . -- 0.002
Test in dict : 50 - . . . . . -- 0.002
Test in set : 50 - . . . . . -- 0.002
Test sort/adjacent : 50 - . . . . . -- 0.023
Test sort/groupby : 50 - . . . . . -- 0.026
Test sort/zip : 50 - . . . . . -- 1.102
Test sort/izip : 50 - . . . . . -- 0.035
Test sort/tee/izip : 50 - . . . . . -- 0.024
Test moooeeeep : 50 - . . . . . -- 0.001 *
Test iter*/sorted : 50 - . . . . . -- 0.027
Test set len change : 5000 - . . . . . -- 0.017
Test in dict : 5000 - . . . . . -- 0.003 *
Test in set : 5000 - . . . . . -- 0.004
Test sort/adjacent : 5000 - . . . . . -- 0.031
Test sort/groupby : 5000 - . . . . . -- 0.035
Test sort/zip : 5000 - . . . . . -- 1.080
Test sort/izip : 5000 - . . . . . -- 0.043
Test sort/tee/izip : 5000 - . . . . . -- 0.031
Test moooeeeep : 5000 - . . . . . -- 0.003 *
Test iter*/sorted : 5000 - . . . . . -- 0.031
Test set len change : 50000 - . . . . . -- 0.035
Test in dict : 50000 - . . . . . -- 0.023
Test in set : 50000 - . . . . . -- 0.023
Test sort/adjacent : 50000 - . . . . . -- 0.036
Test sort/groupby : 50000 - . . . . . -- 0.134
Test sort/zip : 50000 - . . . . . -- 1.121
Test sort/izip : 50000 - . . . . . -- 0.054
Test sort/tee/izip : 50000 - . . . . . -- 0.045
Test moooeeeep : 50000 - . . . . . -- 0.019 *
Test iter*/sorted : 50000 - . . . . . -- 0.055
Test set len change : 500000 - . . . . . -- 0.249
Test in dict : 500000 - . . . . . -- 0.145
Test in set : 500000 - . . . . . -- 0.165
Test sort/adjacent : 500000 - . . . . . -- 0.139
Test sort/groupby : 500000 - . . . . . -- 1.138
Test sort/zip : 500000 - . . . . . -- 1.159
Test sort/izip : 500000 - . . . . . -- 0.126
Test sort/tee/izip : 500000 - . . . . . -- 0.120 *
Test moooeeeep : 500000 - . . . . . -- 0.131
Test iter*/sorted : 500000 - . . . . . -- 0.157
.next()调用在Python 3.x上不起作用。我认为使用next(getDupes(l))应该在各种Python版本中都可行,所以更改这一点可能是有意义的。 - MSeifertifilter和izip可以被内置的filter和zip简单替换。 - MSeifert另一种简洁的方法是使用计数器。
仅确定原始列表中是否有任何重复项:
from collections import Counter
def has_dupes(l):
# second element of the tuple has number of repetitions
return Counter(l).most_common()[0][1] > 1
def get_dupes(l):
return [k for k, v in Counter(l).items() if v > 1]
my_list = ['one', 'two', 'one']
duplicates = []
for value in my_list:
if my_list.count(value) > 1:
if value not in duplicates:
duplicates.append(value)
print(duplicates) //["one"]
我发现这种方法的性能最佳,因为它在找到第一个重复项时就停止了操作,所以该算法的时间和空间复杂度为O(n),其中n是列表的长度:
def has_duplicated_elements(iterable):
""" Given an `iterable`, return True if there are duplicated entries. """
clean_elements_set = set()
clean_elements_set_add = clean_elements_set.add
for possible_duplicate_element in iterable:
if possible_duplicate_element in clean_elements_set:
return True
else:
clean_elements_set_add( possible_duplicate_element )
return False
def has_duplicates(x):
for idx, item in enumerate(x):
if item in x[(idx + 1):]:
return True
return False
>>> has_duplicates(["a", "b", "c"])
False
>>> has_duplicates(["a", "b", "b", "c"])
True
>>> has_duplicates("abc")
False
>>> has_duplicates("abbc")
True