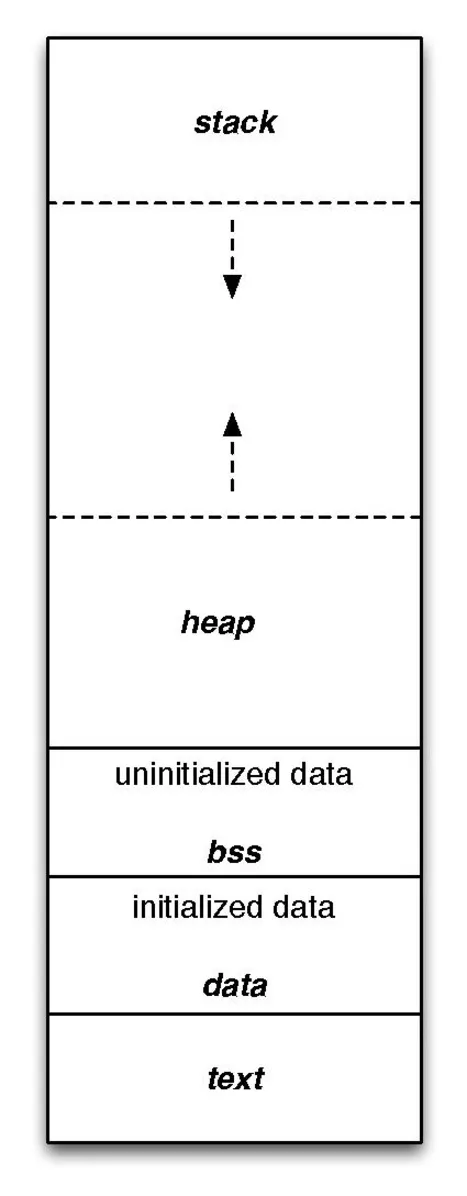
你的图表是一种教材式的视角,不一定是错误的,但对于微控制器来说并不完全准确。
C语言和汇编语言通常会生成同样的结果,一个包含机器代码、数据和某些结构以供链接器识别的对象。其中会包含指示哪些字节块属于什么的信息,通常称为“section”。具体名称如 .text、.data 等并非铁板钉钉,工具开发者可以自由选择任何名称。如果他们不使用这些名称,则会给习惯于这些术语的普通人造成困惑。因此,尽管您可能正在编写自己喜欢的新编译器,但遵循一定程度的规范是明智的。
堆栈指针与处理器中的任何其他寄存器/概念一样有用,独立于语言。大多数处理器受通用寄存器数量的限制,因此在需要临时保存一些寄存器以腾出更多空间进行工作时,必须做出某些妥协。子程序/函数的概念需要某种跳转以及返回的概念,这与编程语言无关(这意味着包括汇编语言在内)。
堆是在运行操作系统或不完全控制环境时的概念。您所说的关于微控制器的内容称为裸机编程。这通常意味着没有操作系统。这意味着/表示您拥有完全的控制权。您无需请求内存,只需要占用即可。
一般来说,微控制器(几乎所有这些语句都有例外)具有某种非易失性存储器(闪存、EEPROM 等,某种 ROM)和 RAM(SRAM)。芯片厂商会为特定芯片或芯片系列选择这些逻辑组件的地址空间。处理器核心本身很少关心它们,它们只是地址。程序员负责连接所有点。因此,MCU 内存模型将具有闪存地址空间,其中基本上包含代码和理想情况下的只读项目(您需要告诉工具如何执行此操作)。而 SRAM 则具有读/写项目。但存在另一个问题。所谓的 .data 项希望在代码主体之前或在 C 语言编译代码开始执行之前设置为某个值。同样,如果假定 .bss 被清零,则也必须发生这种情况。这是通过所谓的引导程序完成的。一些(理想情况下)汇编语言代码,用于连接应用程序的入口点和高级语言(C)的入口点之间的差距。在操作系统中,首先支持有限数量的二进制文件类型。然后,在这些文件中,操作系统作者决定是否要为您准备内存,而不仅仅是为您的应用程序分配空间。通常,如果您拥有 MCU 问题,则可以将数据放置在链接的位置并将 .bss 清零。
在使用微控制器时,通常需要启动处理器,您的代码是第一段运行的代码,没有操作系统为您准备和管理东西,这在我看来是很好的,但也意味着需要更多的工作。具体而言,在引导时,您只有非易失性存储器(non-volatile storage),为了将 .data 项放入 RAM 中,您需要在 ROM 中拥有它们的副本,并且需要在执行任何假定它们处于最终位置的编译代码之前复制它们。这是引导程序的其中一个任务,另一个任务是设置堆栈指针,因为编译器假定在生成编译代码时存在堆栈。
unsigned int a
unsigned int b = 5
const unsigned int c = 7
void fun ( void )
{
a = b + c
}
Disassembly of section .text:
00000000 <fun>:
0: e59f3010 ldr r3, [pc, #16]
4: e5933000 ldr r3, [r3]
8: e59f200c ldr r2, [pc, #12]
c: e2833007 add r3, r3, #7
10: e5823000 str r3, [r2]
14: e12fff1e bx lr
...
Disassembly of section .data:
00000000 <b>:
0: 00000005 andeq r0, r0, r5
Disassembly of section .bss:
00000000 <a>:
0: 00000000 andeq r0, r0, r0
Disassembly of section .rodata:
00000000 <c>:
0: 00000007 andeq r0, r0, r7
你可以在这个例子中看到所有的元素。
arm-none-eabi-ld -Ttext=0x1000 -Tdata=0x2000 -Tbss=0x3000 -Trodata=0x4000 so.o -o so.elf
Disassembly of section .text:
00001000 <fun>:
1000: e59f3010 ldr r3, [pc, #16]
1004: e5933000 ldr r3, [r3]
1008: e59f200c ldr r2, [pc, #12]
100c: e2833007 add r3, r3, #7
1010: e5823000 str r3, [r2]
1014: e12fff1e bx lr
1018: 00002000
101c: 00003000
Disassembly of section .data:
00002000 <b>:
2000: 00000005
Disassembly of section .bss:
00003000 <a>:
3000: 00000000
Disassembly of section .rodata:
00001020 <c>:
1020: 00000007
(自然地,这不是一个有效/可执行的二进制文件,工具并不知道/关心)
工具忽略了我的 -Trodata,但你可以看到除此之外我们控制着事物的去向,并且通常通过链接来实现。我们最终要确保构建与目标匹配,将东西链接以匹配芯片的地址空间布局。
使用许多编译器,尤其是GNU GCC,您可以创建汇编语言输出。在GCC的情况下,它会编译为汇编语言,然后调用汇编器(明智的设计选择,但不是必需的)。
arm-none-eabi-gcc -O2 -save-temps -c so.c -o so.o
cat so.s
.cpu arm7tdmi
.eabi_attribute 20, 1
.eabi_attribute 21, 1
.eabi_attribute 23, 3
.eabi_attribute 24, 1
.eabi_attribute 25, 1
.eabi_attribute 26, 1
.eabi_attribute 30, 2
.eabi_attribute 34, 0
.eabi_attribute 18, 4
.file "so.c"
.text
.align 2
.global fun
.arch armv4t
.syntax unified
.arm
.fpu softvfp
.type fun, %function
fun:
@ Function supports interworking.
@ args = 0, pretend = 0, frame = 0
@ frame_needed = 0, uses_anonymous_args = 0
@ link register save eliminated.
ldr r3, .L3
ldr r3, [r3]
ldr r2, .L3+4
add r3, r3, #7
str r3, [r2]
bx lr
.L4:
.align 2
.L3:
.word .LANCHOR1
.word .LANCHOR0
.size fun, .-fun
.global c
.global b
.global a
.section .rodata
.align 2
.type c, %object
.size c, 4
c:
.word 7
.data
.align 2
.set .LANCHOR1,. + 0
.type b, %object
.size b, 4
b:
.word 5
.bss
.align 2
.set .LANCHOR0,. + 0
.type a, %object
.size a, 4
a:
.space 4
.ident "GCC: (GNU) 10.2.0"
这里就涉及到了关键点。理解汇编语言是针对汇编器(程序)而非目标(CPU/芯片)的,也就是说,尽管它们生成的机器码相同,但相同处理器芯片可以有许多不兼容的汇编语言,只要它们能够生成正确的机器码,它们都是有用的。这是GNU汇编器(GAS)汇编语言。
.text
nop
add r0,r0,r1
eor r1,r2
b .
.align
.bss
.word 0
.data
.word 0x12345678
.section .rodata
.word 0xAABBCCDD
Disassembly of section .text:
00000000 <.text>:
0: e1a00000 nop
4: e0800001 add r0, r0, r1
8: e0211002 eor r1, r1, r2
c: eafffffe b c <.text+0xc>
Disassembly of section .data:
00000000 <.data>:
0: 12345678
Disassembly of section .bss:
00000000 <.bss>:
0: 00000000
Disassembly of section .rodata:
00000000 <.rodata>:
0: aabbccdd
以相同的方式链接:
Disassembly of section .text:
00001000 <.text>:
1000: e1a00000 nop
1004: e0800001 add r0, r0, r1
1008: e0211002 eor r1, r1, r2
100c: eafffffe b 100c <__data_start-0xff4>
Disassembly of section .data:
00002000 <__data_start>:
2000: 12345678
Disassembly of section .bss:
00003000 <__bss_start+0xffc>:
3000: 00000000
Disassembly of section .rodata:
00001010 <_stack-0x7eff0>:
1010: aabbccdd
对于带有GNU链接器(ld)的MCU,请注意链接器脚本或如何告诉链接器您想要什么是特定于该链接器的,不要假设它在来自其他工具链的其他链接器中是可移植的。
MEMORY
{
rom : ORIGIN = 0x10000000, LENGTH = 0x1000
ram : ORIGIN = 0x20000000, LENGTH = 0x1000
}
SECTIONS
{
.text : { *(.text*) } > rom
.rodata : { *(.rodata*) } > rom
.data : { *(.data*) } > ram AT > rom
.bss : { *(.bss*) } > ram AT > rom
}
我首先告诉链接器,我希望只读内容放在一个地方,可读写内容放在另一个地方。注意,rom和ram这些词只是为了连接(对于gnu链接器)。
MEMORY
{
ted : ORIGIN = 0x10000000, LENGTH = 0x1000
bob : ORIGIN = 0x20000000, LENGTH = 0x1000
}
SECTIONS
{
.text : { *(.text*) } > ted
.rodata : { *(.rodata*) } > ted
.data : { *(.data*) } > bob AT > ted
.bss : { *(.bss*) } > bob AT > ted
}
现在我们得到:
Disassembly of section .text:
10000000 <.text>:
10000000: e1a00000 nop
10000004: e0800001 add r0, r0, r1
10000008: e0211002 eor r1, r1, r2
1000000c: eafffffe b 1000000c <.text+0xc>
Disassembly of section .rodata:
10000010 <.rodata>:
10000010: aabbccdd
Disassembly of section .data:
20000000 <.data>:
20000000: 12345678
Disassembly of section .bss:
20000004 <.bss>:
20000004: 00000000
但是!我们有一个机会在MCU上成功:
arm-none-eabi-objcopy -O binary so.elf so.bin
hexdump -C so.bin
00000000 00 00 a0 e1 01 00 80 e0 02 10 21 e0 fe ff ff ea |..........!.....|
00000010 dd cc bb aa 78 56 34 12 |....xV4.|
00000018
arm-none-eabi-objcopy -O srec --srec-forceS3 so.elf so.srec
cat so.srec
S00A0000736F2E7372656338
S315100000000000A0E1010080E0021021E0FEFFFFEAFF
S30910000010DDCCBBAAC8
S3091000001478563412BE
S70510000000EA
您可以看到AABBCCDD和12345678。
S30910000010DDCCBBAAC8 AABBCCDD at address 0x10000010
S3091000001478563412BE 12345678 at address 0x10000014
在Flash中,如果您的链接器无法帮助您,那么下一步就毫无意义了。
MEMORY
{
ted : ORIGIN = 0x10000000, LENGTH = 0x1000
bob : ORIGIN = 0x20000000, LENGTH = 0x1000
}
SECTIONS
{
.text : { *(.text*) } > ted
.rodata : { *(.rodata*) } > ted
__data_rom_start__ = .;
.data :
{
__data_start__ = .;
*(.data*)
} > bob AT > ted
.bss :
{
__bss_start__ = .;
*(.bss*)
} > bob AT > ted
}
本质上是创建变量/标签,您可以在其他语言中看到:
.text
nop
add r0,r0,r1
eor r1,r2
b .
.align
.word __data_rom_start__
.word __data_start__
.word __bss_start__
.bss
.word 0
.data
.word 0x12345678
.section .rodata
.word 0xAABBCCDD
Disassembly of section .text:
10000000 <.text>:
10000000: e1a00000 nop
10000004: e0800001 add r0, r0, r1
10000008: e0211002 eor r1, r1, r2
1000000c: eafffffe b 1000000c <__data_rom_start__-0x14>
10000010: 10000020
10000014: 20000000
10000018: 20000004
Disassembly of section .rodata:
1000001c <__data_rom_start__-0x4>:
1000001c: aabbccdd
Disassembly of section .data:
20000000 <__data_start__>:
20000000: 12345678
Disassembly of section .bss:
20000004 <__bss_start__>:
20000004: 00000000
S00A0000736F2E7372656338
S315100000000000A0E1010080E0021021E0FEFFFFEAFF
S311100000102000001000000020040000205A
S3091000001CDDCCBBAABC
S3091000002078563412B2
S70510000000EA
这些工具将 .data 存放在 0x10000020 内存地址
S3091000002078563412B2
我们在闪存中看到的
10000010: 10000020 __data_rom_start__
10000014: 20000000 __data_start__
10000018: 20000004 __bss_start__
arm-none-eabi-nm so.elf
20000004 B __bss_start__
10000020 R __data_rom_start__
20000000 D __data_start__
增加更多这些类型的元素(请注意,GNU ld链接脚本很难正确配置),然后可以编写一些汇编语言代码将.data项复制到RAM中,因为您现在知道链接器将事物放置在二进制文件和RAM中的位置。并且知道.bss在哪里以及需要清除/归零的内存量。
裸机环境中的内存分配并不理想,通常是因为现在的裸机工作是微控制器类型的工作。 它不仅限于此,操作系统本身就是一个裸机程序,由另一个裸机程序引导启动-引导加载程序。 但对于MCU而言,您的资源,特别是RAM相当有限,如果您使用全局变量而不是局部变量,并且不进行动态分配而是静态声明事物,则可以通过工具查看大部分SRAM使用情况,并且也可以通过链接器脚本进行限制。
arm-none-eabi-readelf -l so.elf
Elf file type is EXEC (Executable file)
Entry point 0x10000000
There are 2 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x010000 0x10000000 0x10000000 0x00020 0x00020 R E 0x10000
LOAD 0x020000 0x20000000 0x10000020 0x00004 0x00008 RW 0x10000
Section to Segment mapping:
Segment Sections...
00 .text .rodata
01 .data .bss
通常将链接器脚本大小设置为与目标硬件匹配,这里为了演示而夸大了。
bob : ORIGIN = 0x20000000, LENGTH = 0x4
arm-none-eabi-ld -T flash.ld so.o -o so.elf
arm-none-eabi-ld: so.elf section `.bss' will not fit in region `bob'
arm-none-eabi-ld: region `bob' overflowed by 4 bytes
如果您过度使用动态分配,无论是局部变量还是 malloc() 函数族,那么您需要进行消耗分析,以查看堆栈是否溢出到数据。或者数据是否溢出到堆栈。这可能是非常困难的。
另外,要理解没有操作系统的裸机意味着你能使用的 C 库会受到很大限制,因为其中较大比例的功能依赖于操作系统,特别是一般的分配函数。因此,为了在运行时甚至拥有动态内存分配,您需要实现实现分配的 C 库的后端。 (提示:使用链接器脚本查找未使用 RAM 的大小/位置)。因此,在运行时不鼓励使用动态内存分配。但是,在某些情况下,您将希望这样做并需要实现它。
汇编语言显然可以自由地使用堆栈,因为它只是体系结构的另一个部分,并且通常也支持与堆栈相关的指令。可以从汇编语言中调用堆和任何其他 C 库语言调用,因为按定义,汇编语言可以像 C 一样调用标签/地址。
unsigned char * fun ( unsigned int x )
{
return malloc(x);
}
fun:
push {r4, lr}
bl malloc
pop {r4, lr}
bx lr
对于至少针对目标文件和链接的汇编器来说,.text、.rodata、.data、.bss、堆栈和堆都可用于汇编语言。也有一些汇编器只用于单个文件类型或不使用对象和链接器,因此不需要节(sections),但会有类似的东西
.org 0x1000
nop
add r0,r1,r2
.org 0x2000
.word 0x12345678
在汇编语言本身中声明事物所在的具体地址。一些工具可能会让你混合使用这些概念,但这可能会让你和工具感到相当困惑。
使用广泛的现代工具如gnu/binutils和clang/llvm,支持所有受支持语言的节区使用和概念,以及一个对象到另一个对象的函数/库调用(可以具有并使用独立于调用它的语言的C库)。