澄清问题(tl;dr)
阅读并分析了以下所有结果后,问题似乎归结为GC在服务器模式下不收集我们应用程序的Gen 0堆,一旦将其更改为工作站模式,问题就会消失。
原问题和详细信息
我的问题与此问题和此问题有些相关。
最近,在我们的测试环境中,我们的.NET应用程序出现了内存泄漏的情况。当负载较重或无负载时,工作进程的使用率会快速上升到约450MB。
在开发环境中无法复制该问题,主要区别是开发环境是物理服务器,而测试环境是虚拟化的,并由Puppet控制(除此之外,我对环境本身没有太多了解)。
为了希望看到哪些对象占用了所有内存,我在测试服务器上运行了Ants Memory Profiler,发现所有内存都保持未使用状态,从未被释放。
在研究可能导致这种情况的原因时,我发现这个论坛帖子,它又引导我找到了这篇文章。
最终,我尝试了它推荐的配置,将GC置于工作站模式:
运行了iisreset并重新进行了内存分析后,问题完全消失了,这很棒,但仍然无法解释最初发生了什么。
我阅读了更多资料,并找到了此SO问题,这让我相信这种配置更改可能会对我们应用程序的吞吐量产生负面影响。
所以我的问题是:是什么导致IIS工作进程累积大量未使用的内存,而这些内存从未被垃圾回收?
编辑: 为了更清楚地说明我的问题,我认为我们已经证明了代码不是造成这个问题的原因,因为在开发环境中,完全相同的代码没有遇到这个问题。
以下是我在配置更改前后拍摄的内存分析屏幕截图,这里没有太多信息,但图表很好地显示了内存趋势。
开发环境: 物理机器 CPU:单核 内存:6GB
测试环境: 虚拟机 CPU:4个逻辑线程(我无法评论CPU数量) 内存:8GB
机器配置文件中唯一的区别是开发环境在端点和服务行为中添加了“Microsoft.VisualStudio.Diagnostics.ServiceModelSink.Behavior”。
而测试环境目前在aspnet.config文件中设置了先前提到的GC设置。
编辑3: 进行了更多的性能分析,并注意到了一些可以添加到Ants的计数器,特别是我添加了“Gen 0 heap size”,看起来这是问题的根源。当我触发用于分析的测试时,使用服务器模式的GC,此行立即跳至约300MB,然后回落到约230MB,但从未完全回落(下图)。
我还发现这篇文章对这个问题有以下描述(似乎几乎完美地描述了正在发生的事情):
最近,在我们的测试环境中,我们的.NET应用程序出现了内存泄漏的情况。当负载较重或无负载时,工作进程的使用率会快速上升到约450MB。
在开发环境中无法复制该问题,主要区别是开发环境是物理服务器,而测试环境是虚拟化的,并由Puppet控制(除此之外,我对环境本身没有太多了解)。
为了希望看到哪些对象占用了所有内存,我在测试服务器上运行了Ants Memory Profiler,发现所有内存都保持未使用状态,从未被释放。
在研究可能导致这种情况的原因时,我发现这个论坛帖子,它又引导我找到了这篇文章。
最终,我尝试了它推荐的配置,将GC置于工作站模式:
<configuration>
<runtime>
<gcServer enabled="false"/>
<gcConcurrent enabled="false"/>
</runtime>
</configuration>
运行了iisreset并重新进行了内存分析后,问题完全消失了,这很棒,但仍然无法解释最初发生了什么。
我阅读了更多资料,并找到了此SO问题,这让我相信这种配置更改可能会对我们应用程序的吞吐量产生负面影响。
所以我的问题是:是什么导致IIS工作进程累积大量未使用的内存,而这些内存从未被垃圾回收?
编辑: 为了更清楚地说明我的问题,我认为我们已经证明了代码不是造成这个问题的原因,因为在开发环境中,完全相同的代码没有遇到这个问题。
以下是我在配置更改前后拍摄的内存分析屏幕截图,这里没有太多信息,但图表很好地显示了内存趋势。
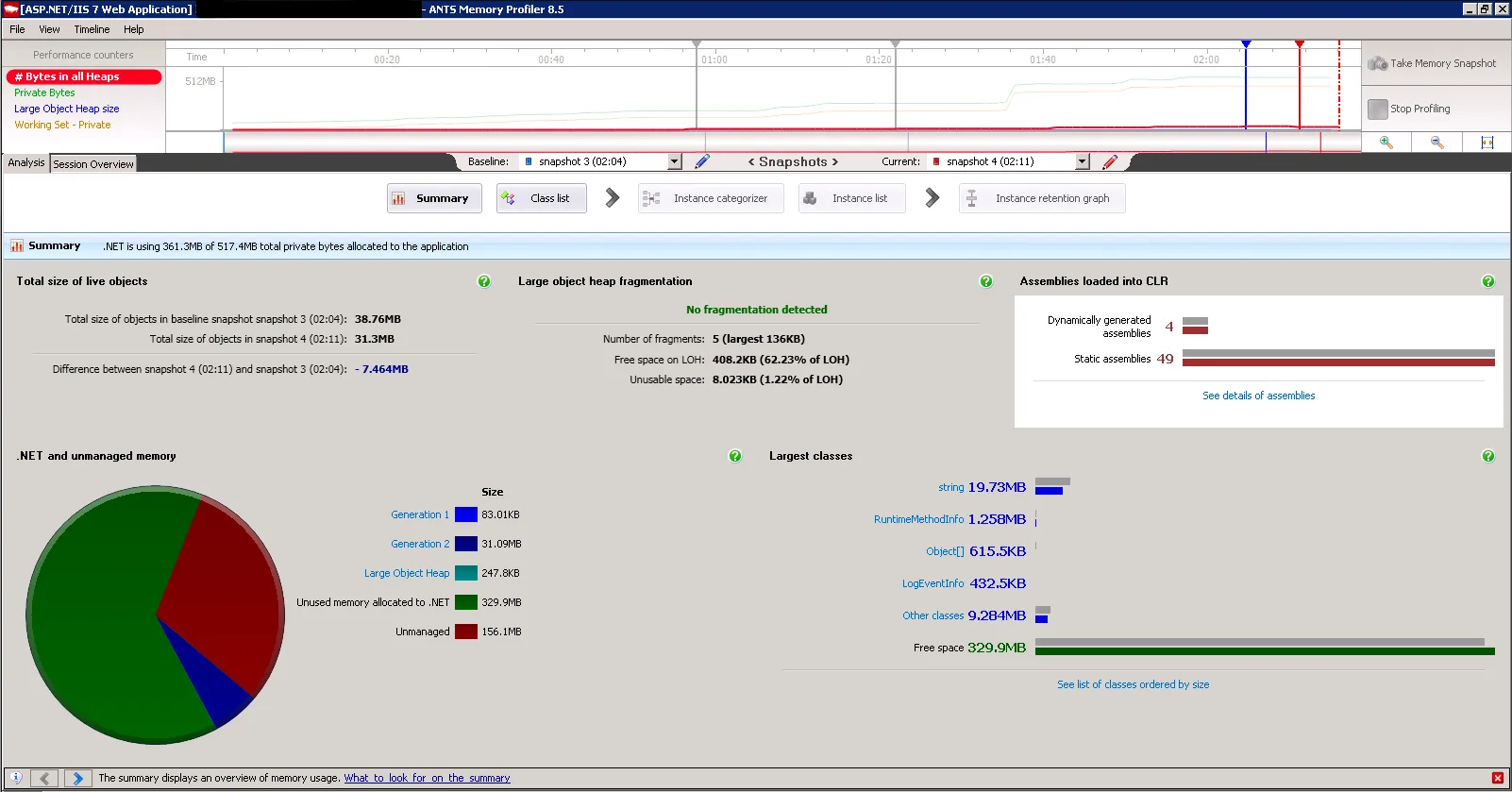
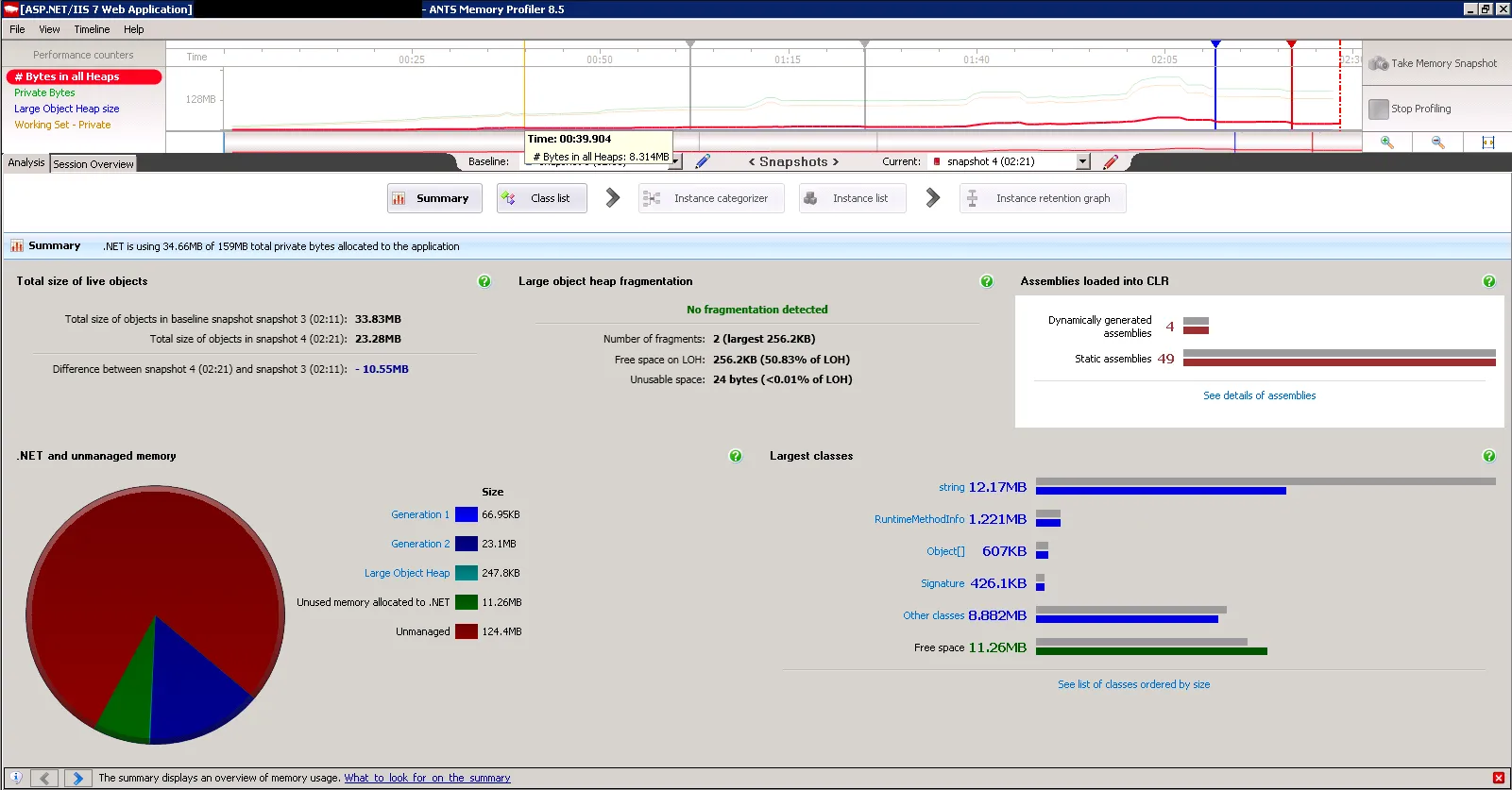
开发环境: 物理机器 CPU:单核 内存:6GB
测试环境: 虚拟机 CPU:4个逻辑线程(我无法评论CPU数量) 内存:8GB
机器配置文件中唯一的区别是开发环境在端点和服务行为中添加了“Microsoft.VisualStudio.Diagnostics.ServiceModelSink.Behavior”。
而测试环境目前在aspnet.config文件中设置了先前提到的GC设置。
编辑3: 进行了更多的性能分析,并注意到了一些可以添加到Ants的计数器,特别是我添加了“Gen 0 heap size”,看起来这是问题的根源。当我触发用于分析的测试时,使用服务器模式的GC,此行立即跳至约300MB,然后回落到约230MB,但从未完全回落(下图)。


我还发现这篇文章对这个问题有以下描述(似乎几乎完美地描述了正在发生的事情):
尽管问题仍然存在,在服务器模式下,第0代堆似乎永远不会被收集,而不仅仅是不那么频繁。在64位系统上,第0代可能会有更多的对象,特别是当您使用服务器垃圾回收而不是工作站垃圾回收时。这是因为在这些环境中触发第0代垃圾回收的阈值更高,而且第0代集合可以变得更大。当应用程序在触发垃圾回收之前分配更多内存时,性能会得到改善。