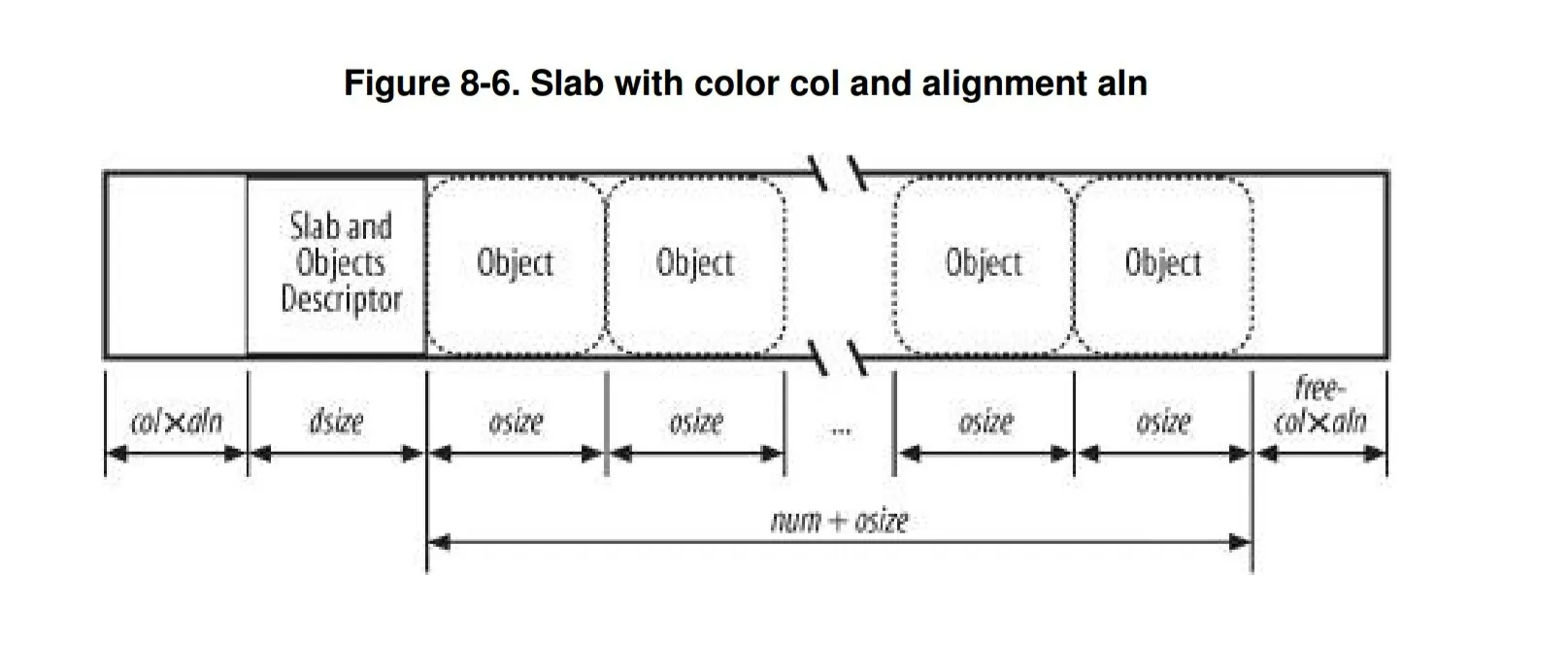
来自指南《理解Linux内核第三版》,第8.2.10章,Slab着色-
我们从第二章知道,同一硬件高速缓存行映射许多不同的RAM块。在本章中,我们还看到,相同大小的对象最终被存储在高速缓存的相同偏移量处。在不同slab内具有相同偏移量的对象将以相对较高的概率被映射到相同的高速缓存行中。因此,高速缓存硬件可能会浪费内存周期将同一高速缓存行中的两个对象来回传输到不同的RAM位置,而其他高速缓存行则未充分利用。slab分配器通过一种称为slab着色的策略来减少这种不良的高速缓存行为:将不同的任意值分配给slab,称为颜色。