我正在运行一个Rails 3.2.21应用程序,并使用capistrano(nginx和unicorn)部署到Ubuntu 12.04.5盒子上。
我已经将我的应用程序设置为无停机部署(至少我是这样认为的),我的配置文件看起来更或多或少像这些。
问题在于:当部署快要完成并重新启动unicorn时,当我观察我的unicorn.log时,我看到它启动了新的worker,收割了旧的worker……但是我的应用程序就会卡住2-3分钟。此时对应用程序的任何请求都会命中超时窗口(我将其设置为40秒),并返回我的应用程序的500错误页面。
以下是unicorn正在重新启动时从unicorn.log输出的第一部分内容(我有5个unicorn worker):
我已经将我的应用程序设置为无停机部署(至少我是这样认为的),我的配置文件看起来更或多或少像这些。
问题在于:当部署快要完成并重新启动unicorn时,当我观察我的unicorn.log时,我看到它启动了新的worker,收割了旧的worker……但是我的应用程序就会卡住2-3分钟。此时对应用程序的任何请求都会命中超时窗口(我将其设置为40秒),并返回我的应用程序的500错误页面。
以下是unicorn正在重新启动时从unicorn.log输出的第一部分内容(我有5个unicorn worker):
I, [2015-04-21T23:06:57.022492 #14347] INFO -- : master process ready
I, [2015-04-21T23:06:57.844273 #15378] INFO -- : worker=0 ready
I, [2015-04-21T23:06:57.944080 #15381] INFO -- : worker=1 ready
I, [2015-04-21T23:06:58.089655 #15390] INFO -- : worker=2 ready
I, [2015-04-21T23:06:58.230554 #14541] INFO -- : reaped #<Process::Status: pid 15551 exit 0> worker=4
I, [2015-04-21T23:06:58.231455 #14541] INFO -- : reaped #<Process::Status: pid 3644 exit 0> worker=0
I, [2015-04-21T23:06:58.249110 #15393] INFO -- : worker=3 ready
I, [2015-04-21T23:06:58.650007 #15396] INFO -- : worker=4 ready
I, [2015-04-21T23:07:01.246981 #14541] INFO -- : reaped #<Process::Status: pid 32645 exit 0> worker=1
I, [2015-04-21T23:07:01.561786 #14541] INFO -- : reaped #<Process::Status: pid 15534 exit 0> worker=2
I, [2015-04-21T23:07:06.657913 #14541] INFO -- : reaped #<Process::Status: pid 16821 exit 0> worker=3
I, [2015-04-21T23:07:06.658325 #14541] INFO -- : master complete
随后,当应用程序挂起2-3分钟时,以下是正在发生的事情:
E, [2015-04-21T23:07:38.069635 #14347] ERROR -- : worker=0 PID:15378 timeout (41s > 40s), killing
E, [2015-04-21T23:07:38.243005 #14347] ERROR -- : reaped #<Process::Status: pid 15378 SIGKILL (signal 9)> worker=0
E, [2015-04-21T23:07:39.647717 #14347] ERROR -- : worker=3 PID:15393 timeout (41s > 40s), killing
E, [2015-04-21T23:07:39.890543 #14347] ERROR -- : reaped #<Process::Status: pid 15393 SIGKILL (signal 9)> worker=3
I, [2015-04-21T23:07:40.727755 #16002] INFO -- : worker=0 ready
I, [2015-04-21T23:07:43.212395 #16022] INFO -- : worker=3 ready
E, [2015-04-21T23:08:24.511967 #14347] ERROR -- : worker=3 PID:16022 timeout (41s > 40s), killing
E, [2015-04-21T23:08:24.718512 #14347] ERROR -- : reaped #<Process::Status: pid 16022 SIGKILL (signal 9)> worker=3
I, [2015-04-21T23:08:28.010429 #16234] INFO -- : worker=3 ready
最终,经过2到3分钟后,应用程序开始重新响应,但一切都变得更加缓慢。您可以在New Relic中清楚地看到这一点(水平线标记部署,浅蓝色区域表示Ruby):
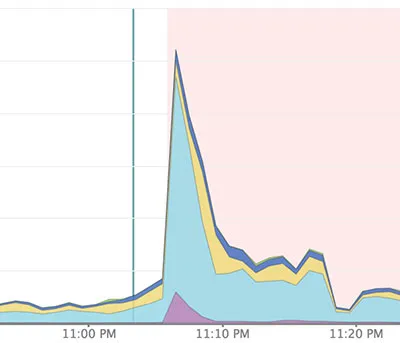
我有一个完全相同的演示服务器,但是我无法在演示环境中复制出现的问题...当然,演示环境没有负载(只有我一个人尝试进行页面请求)。
这是我的config/unicorn.rb文件:
root = "/home/deployer/apps/myawesomeapp/current"
working_directory root
pid "#{root}/tmp/pids/unicorn.pid"
stderr_path "#{root}/log/unicorn.log"
stdout_path "#{root}/log/unicorn.log"
shared_path = "/home/deployer/apps/myawesomeapp/shared"
listen "/tmp/unicorn.myawesomeapp.sock"
worker_processes 5
timeout 40
preload_app true
before_exec do |server|
ENV['BUNDLE_GEMFILE'] = "#{root}/Gemfile"
end
before_fork do |server, worker|
if defined?(ActiveRecord::Base)
ActiveRecord::Base.connection.disconnect!
end
old_pid = "#{root}/tmp/pids/unicorn.pid.oldbin"
if File.exists?(old_pid) && server.pid != old_pid
begin
Process.kill("QUIT", File.read(old_pid).to_i)
rescue Errno::ENOENT, Errno::ESRCH
end
end
end
after_fork do |server, worker|
if defined?(ActiveRecord::Base)
ActiveRecord::Base.establish_connection
end
end
为了完整地说明情况,在我的capistrano的deploy.rb文件中,unicorn重启任务如下:
namespace :deploy do
task :restart, roles: :app, except: { no_release: true } do
run "kill -s USR2 `cat #{release_path}/tmp/pids/unicorn.pid`"
end
end
有什么想法可以解释为什么独角兽工作者在部署后立即超时?我认为零停机的重点是要保留旧的工作者,直到新工作者启动并准备好提供服务为止?
谢谢!
更新
我进行了另一个部署,并这次密切关注了production.log,以查看那里发生了什么。唯一可疑的是以下行,它们与正常请求混在一起:
Dalli/SASL authenticating as 7510de
Dalli/SASL: 7510de
Dalli/SASL authenticating as 7510de
Dalli/SASL: 7510de
Dalli/SASL authenticating as 7510de
Dalli/SASL: 7510de
更新 #2
根据以下答案的建议,我更改了before_fork块以添加sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU,以便逐步杀死工作进程。
相同的结果,部署非常缓慢,并出现了上面图表中所示的峰值。仅供参考,我的5个工作进程中,前4个发送了TTOU信号,第5个发送了QUIT信号。然而,似乎并没有产生任何区别。
executing "cd -- /home/deployer/apps/myawesomeapp/releases/20150422035053 && bundle exec rake RAILS_ENV=production RAILS_GROUPS=assets assets:precompile",这是一个需要大约30秒才能完成的命令。 - DelPiero