这是一个面试问题。我有K台机器,每台机器都连接到1台中央机器。每台机器上都有一个包含4字节数字的数组文件。您可以使用任何数据结构将这些数字加载到这些机器的内存中,并且它们适合内存。数字在K个机器之间不唯一。查找所有K个机器中数字的并集中的K个最大数字。我能做到最快的速度是多少?
7个回答
12
这是一个涉及并行性的有趣问题。由于我以前没有遇到过并行算法优化,所以这很有趣:你可以通过后续操作弥补一些非常高复杂度的步骤。无论如何,进入答案...
“最快能做到什么程度?”
最好的情况是O(K)。下面我将阐述一个简单的O(K log(K))算法和更复杂的O(K)算法。
你可以将其想象为计算几何中的扫描线算法,或者是归并排序中“合并”步骤的高效变体。括号中的元素表示我们将用它们初始化潜在的“候选解决方案”(在某个中央服务器上)。通过删除两个未选择的
算法:
因此,我们将拥有O(N log(N) + K)的总运行时间(并行排序,然后是O(K)*O(1)优先级队列插入)。在N=K的最坏情况下,这是O(K log(K))。
(I'd draw the relation between the unordered sets of rows and s-column here, but it would clutter things up; see the addendum right now quickly.)
对于这个分析,我们将考虑N的减少。
在给定的步骤中,我们能够消除标记为ELIMIN的元素;这已经从上面的矩形表示中删除了面积,将问题规模从K*N减小到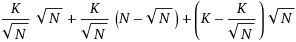 ,这极大地简化为
,这极大地简化为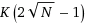 。请快速查看补充说明以了解未排序的行和s列之间的关系。
。请快速查看补充说明以了解未排序的行和s列之间的关系。
Now,具有未消除元素的计算机将其数据(上方的
因此,在每个大小为
子问题规模的减少速度比普通的几何级数快得多(是 √N 而不是像常见的分治算法一样的 N/2)。不幸的是,既不适用主定理,也不适用强大的 Akra-Bazzi 定理,但是我们可以通过模拟来确信它是线性的:
“最快能做到什么程度?”
最好的情况是O(K)。下面我将阐述一个简单的O(K log(K))算法和更复杂的O(K)算法。
第一步:
每台计算机需要足够的时间来读取每个元素。这意味着,除非元素已经在内存中,否则时间的两个边界之一为O(最大数组大小)。例如,如果您的最大数组大小变化为O(K log(K))或O(K^2)等,则无论如何进行算法技巧,都无法使速度更快。因此,实际的最佳运行时间在技术上是O(max(K, largestArraySize))。
假设数组的最大长度为N,即<=K。在上述警告下,我们可以限制N<K,因为每台计算机都必须至少查看其每个元素(每台计算机的O(N)预处理),每台计算机可以选择最大的K个元素(这被称为查找kth-order-statistics,参见这些线性时间algorithms)。此外,我们可以免费这样做(因为它也是O(N))。
范围和合理预期:
让我们从一些最坏情况和所需最小工作量的估计开始思考。
- 一个所需最小工作量的估计是O(K*N/K) = O(N),因为我们至少需要查看每个元素。但是,如果我们聪明地将工作均匀分配到所有K台计算机上(因此除以K),我们可以完成这项工作。
- 另一个所需最小工作量的估计是O(N):如果一个数组大于所有其他计算机上的所有元素,我们就返回该集合。
- 我们必须输出所有K个元素;这至少需要O(K)来打印它们。如果我们仅满足于知道元素在哪里,那么O(K)的限制不一定适用。
这个O(N)的限制能够实现吗?让我们看看...
简单方法 - O(NlogN + K) = O(KlogK):
现在让我们想出一个简单的方法,达到O(NlogN + K)。
考虑数据按以下方式排列,其中每列是一台计算机,每行是数组中的一个数字:
computer: A B C D E F G
10 (o) (o)
9 o (o) (o)
8 o (o)
7 x x (x)
6 x x (x)
5 x ..........
4 x x ..
3 x x x . .
2 x x . .
1 x x .
0 x x .
你可以将其想象为计算几何中的扫描线算法,或者是归并排序中“合并”步骤的高效变体。括号中的元素表示我们将用它们初始化潜在的“候选解决方案”(在某个中央服务器上)。通过删除两个未选择的
o的(x)答案,该算法将收敛于正确的o响应。算法:
- 所有计算机最初都是“活动的”。
- 每台计算机对其元素进行排序。(并行O(N logN))
- 重复,直到所有计算机都处于非活动状态:
- 每个活动计算机找到下一个最高的元素(由于已排序,所以为O(1)),并将其提供给中央服务器。
- 服务器智能地将新元素与旧K个元素组合,并从组合集合中删除相等数量的最低元素。为了有效地执行此步骤,我们有一个固定大小为K的全局优先级队列。我们插入新的潜在更好的元素,不好的元素从集合中掉出。每当一个元素掉出集合时,我们告诉发送该元素的计算机不再发送另一个元素。(理由:这总是提高候选集的最小元素。)
(附注:将回调钩子添加到优先级队列中掉出是一个O(1)操作。)
我们可以从图形上看出,这将执行最多2K *(findNextHighest_time + queueInsert_time)次操作,随着我们这样做,元素自然会从优先级队列中掉落。由于我们已经排序了数组,因此findNextHighest_time为O(1),因此为了最小化2K*queueInsert_time,我们选择具有O(1)插入时间的优先级队列(例如基于斐波那契堆的优先级队列)。这给我们带来了O(log(queue_size))的提取时间(我们不能同时具有O(1)插入和提取);但是,我们从不需要使用提取操作!一旦我们完成,我们只需将优先级队列作为无序集合转储,这需要O(queue_size)=O(K)时间。因此,我们将拥有O(N log(N) + K)的总运行时间(并行排序,然后是O(K)*O(1)优先级队列插入)。在N=K的最坏情况下,这是O(K log(K))。
更好的方法 - O(N+K) = O(K):
然而,我提出了一种更好的方法,它可以实现O(K)。它基于中位数选择算法,但是并行化了。它的步骤如下:
如果我们确定在所有计算机中有至少K(不是严格的)个较大的数字,那么我们就可以消除一组数字。
算法:
- 每台计算机找到其集合中第
sqrt(N)大的元素,并将集合分成小于和大于它的元素。这在并行中需要O(N)时间。 - 计算机们合作将这些统计数据组合成一个新集合,并找到该集合中第
K/sqrt(N)大的元素(让我们称之为“超级统计数据”),并记录哪些计算机具有小于和大于超级统计数据的统计数据。这需要O(K)的时间。 - 现在考虑所有小于其计算机统计数据的元素,这些元素位于统计数据小于超级统计数据的计算机上。这些元素可以被消除。这是因为那些大于其计算机统计数据的元素位于统计数据大于超级统计数据的计算机上,是一组K个较大的元素。(请参见此处的可视化here)。
- 现在,具有未被消除元素的计算机将其数据均匀重新分配给失去数据的计算机。
- 递归:您仍然拥有K台计算机,但N的值已经减少。一旦N小于预定常量,请使用我在“简单方法-O(NlogN+K)”中提到的以前的算法;除了这种情况下,它现在是O(K)。=)
------N-----
N^.5
________________
| | s | <- computer
| | #=K s REDIST. | <- computer
| | s | <- computer
| K/N^.5|-----S----------| <- computer
| | s | <- computer
K | s | <- computer
| | s ELIMIN. | <- computer
| | s | <- computer
| | s | <- computer
| |_____s__________| <- computer
LEGEND:
s=statistic, S=superstatistic
#=K -- set of K largest elements
(I'd draw the relation between the unordered sets of rows and s-column here, but it would clutter things up; see the addendum right now quickly.)
对于这个分析,我们将考虑N的减少。
在给定的步骤中,我们能够消除标记为ELIMIN的元素;这已经从上面的矩形表示中删除了面积,将问题规模从K*N减小到
,这极大地简化为。请快速查看补充说明以了解未排序的行和s列之间的关系。Now,具有未消除元素的计算机将其数据(上方的
REDIST矩形)重新分配给具有消除元素的计算机(ELIMIN)。这是并行完成的,其中带宽瓶颈对应于REDIST的短边长度(因为它们被等待其数据的ELIMIN计算机所占多数)。因此,数据传输所需的时间与REDIST矩形的长边长度相同(另一种思考方式:面积为K/√N * (N-√N),除以K/√N每单位时间的数据,结果为O(N-√N)时间)。因此,在每个大小为
N的步骤中,我们能够将问题规模减小到K(2√N-1),代价是执行N + 3K + (N-√N)工作。现在我们进行递归。将告诉我们性能的递归关系式为:T(N) = 2N+3K-√N + T(2√N-1)
子问题规模的减少速度比普通的几何级数快得多(是 √N 而不是像常见的分治算法一样的 N/2)。不幸的是,既不适用主定理,也不适用强大的 Akra-Bazzi 定理,但是我们可以通过模拟来确信它是线性的:
>>> def T(n,k=None):
... return 1 if n<10 else sqrt(n)*(2*sqrt(n)-1)+3*k+T(2*sqrt(n)-1, k=k)
>>> f = (lambda x: x)
>>> (lambda n: T((10**5)*n,k=(10**5)*n)/f((10**5)*n) - T(n,k=n)/f(n))(10**30)
-3.552713678800501e-15
T(N)函数在大规模上是线性函数x的倍数,因此是线性的(输入翻倍输出也翻倍)。因此,这种方法几乎可以肯定地达到我们所推测的O(N)上限。不过请参见附录中的有趣可能性。
...
补充
- 一个陷阱是意外地排序。如果我们做了任何意外排序的操作,我们至少会遭受log(N)的惩罚。因此最好将数组视为集合,以避免认为它们已经排序的陷阱。
- 同时,我们可能最初认为每个步骤都需要恒定的3K工作量,因此我们必须要做3Klog(log(N))的工作量。但是-1在问题规模的消减中起着重要的作用。运行时间很可能略高于线性,但肯定比Nlog(log(log(log(N))))小得多。例如,它可能是类似于O(N*InverseAckermann(N))的东西,但我在测试时达到了递归限制。
- O(K)可能只是由于我们必须将它们打印出来的事实;如果我们仅满足于知道数据在哪里,我们甚至可以实现O(N)(例如,如果数组长度为O(log(K)),我们可能能够实现O(log(K)))...但这是另一个故事。
- 无序集之间的关系如下。在解释中会使事情混乱。
.
_
/ \
(.....) > s > (.....)
s
(.....) > s > (.....)
s
(.....) > s > (.....)
\_/
v
S
v
/ \
(.....) > s > (.....)
s
(.....) > s > (.....)
s
(.....) > s > (.....)
\_/
- ninjagecko
4
更好的解决方案总复杂度为O(K),最坏情况下不会有O(K)轮吗? - svick
排序的答案就是我给出的。你的第二个解决方案 O(k) 怎么样?难道你不需要在 k 个数组中每次找到第 i 大的元素吗? - Aks
@svick:是的,但在这种特殊情况下,如果正确执行,每个回合都将是O(1)的删除。我正在仔细检查我的工作(总是一个好习惯),如果发现问题,我会尽快更新。 - ninjagecko
@Aks:感谢您指出这一点。我已经编辑成一个真正实现O(K)的解决方案,同时您提到的解决方案(实际上是O(K log(K)))仍然作为我提到的第一个解决方案。 - ninjagecko
11
- 找到每台计算机中的k个最大数字。O(n*log(k))
- 将结果组合在一起(如果k不是很大,则在中央服务器上,否则可以在服务器集群中跨层次树形合并)。
更新:为了明确起见,合并步骤不是排序。您只需从结果中选择前k个数字即可。有很多有效的方法来做到这一点。例如,您可以使用堆,推送每个列表的头部。然后您可以从堆中删除头部,并将元素所属的列表的头部推送出去。这样做k次会给您结果。所有这些都是O(k*log(k))。
- Karoly Horvath
2
将结果合并并进行排序需要k^k步骤和比较。请查看我的答案,解决这个问题。但如果我错了,请纠正我。谢谢... - Tabrez Ahmed
如果最大的数字都在一个或几个数组中怎么办? - mekbib.awoke
3
- 在集中式服务器中维护一个大小为'k'的最小堆。
- 最初将前k个元素插入最小堆中。
- 对于剩下的元素
- 检查(peek)堆中的最小元素(O(1))
- 如果最小元素小于当前元素,则从堆中删除最小元素并插入当前元素。
- 最后,最小堆将有'k'个最大的元素
- 这将需要n(log k)时间。
- Algorist
1
我建议这样做:
按排序顺序在每台机器上取出k个最大的数字,O(Nk),其中N是每台机器上元素的数量
对这些k个元素的每个数组进行排序,按最大元素排序(您将获得k个按最大元素排序的k个元素数组:一个kxk的方阵)
取由这k个k个元素数组组成的矩阵的“上三角”(k个最大元素将在此上三角中)
现在,中央机器可以找到这k(k+1)/2个元素中的k个最大元素
- Ricky Bobby
5
“sort each of these arrays of k elements by largest element” 是什么意思? - Aks
你可以从这些数组中创建一个矩阵(其中每一列都是来自机器的一个数组)。然后,你可以对每一列进行排序,以便将每一列的第一个元素按降序排序(即矩阵的第一行已排序)。这基本上就像组合数组,但你只需要查看组合元素的一半来找到前k个最大值。 - Ricky Bobby
但是如果其中一个数组都是K个最大的元素,那么上三角将无法覆盖它吗? - Aks
是的,如果一个数组包含了所有K个最大元素,那么它必须是排好序的数组列表中的第一个数组,因此它位于矩阵的上(左)三角形区域。 - Ricky Bobby
用矩阵的图示会更容易理解 :D。 - Ricky Bobby
1
- 让机器找到前k个最大的元素,将其复制到数据结构(堆栈)中,进行排序并传递给中央机器。
- 在中央机器上接收来自所有机器的堆栈。找到堆栈顶部元素中的最大值。
- 从其堆栈中弹出最大元素,并将其复制到'TopK列表'中。保留其他堆栈不变。
- 重复步骤3,k次以获取前k个数字。
- Tabrez Ahmed
0
1) 对每台机器上的项目进行排序 2) 在中央机器上使用k-二叉堆 a)用每台机器的第一个(最大)元素填充堆 b)提取第一个元素,并将从您提取元素的机器中的第一个元素放回堆中。 (当然,在添加元素后,对堆进行堆化)。
排序将是O(Nlog(N)),其中N是机器上的最大数组。 O(k)-构建堆 O(klog(k))以k次提取和填充堆为基础。
复杂度为max(O(klog(k)),O(Nlog(N)))
- user3053247
-1
我认为MapReduce范例非常适合这样的任务。
每台机器都运行自己独立的映射任务,以查找其数组中的最大值(取决于所使用的语言),对于每台机器上的N个数字,这可能是O(N)复杂度。
归约任务将比较各个机器输出的结果,以给出最大的k个数字。
- Nikhil
5
问题在于最大的K个数字可能都在同一台机器上。这种情况下,您会低估最大值。 - Rob Neuhaus
在哪种情况下,MapReduce仍将在一台机器上以相同的方式运行。我已经在Hadoop上实现了类似的问题。它对于1个或k个机器同样有效。 - Nikhil
1谷歌支付我大量的钱来编写MapReduce,但这基本上是无关紧要的。考虑A = {-1, 0},B = {1, 2},Map(A) -> 0,Map(B) -> 2,Reduce({Map(A),Map(B)}) = {0, 2}。Max2({-1, 0, 1, 2}) = {1, 2}。为了使您的解决方案起作用,您需要将所有数据发送到Reducer,这不是非常高效/分布式的。 - Rob Neuhaus
啊好的,我明白你的观点了,谢谢。出于学术兴趣,这种方法与Karoly建议的方法相比有多大不同?Karoly建议计算每台机器上的最大值,并在中央机器上决定整体最大值。 - Nikhil
1由于您正在每台机器中选择k个最大元素,因此您不会错过任何最大的元素。 - Aks
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接