我不知道如何构建适用于以下示例值的正则表达式:
123,456,789
-12,34
1234
-8
你能帮我吗?
我对你的“简单”问题有一个简单的问题:你所说的“数字”具体指的是什么?
−0是一个数字吗?√−1有何感想?⅝或⅔是一个数字吗?186,282.42±0.02英里/秒是一个数字吗,还是两个或三个数字?6.02e23是一个数字吗?3.141_592_653_589是一个数字吗?π、ℯ、−2π⁻³ ͥ呢?0.083̄中有多少个数字?128.0.0.1中有多少个数字?⚄代表什么数字?⚂⚃呢?10,5 mm中有一个数字吗,还是有两个数字?∛8³是一个数字吗,还是三个数字?ↀↀⅮⅭⅭⅬⅫ AUC代表哪个数字,2762还是2009?४५६७和৭৮৯৮是数字吗?0377、0xDEADBEEF和0b111101101呢?Inf是一个数字吗?NaN呢?④②是一个数字吗?⓰呢?㊅有何感想?ℵ₀和ℵ₁与数字有什么关系?或者ℝ、ℚ和ℂ呢?另外,您是否熟悉这些模式?您能解释每个模式的优缺点吗?
/\D//^\d+$//^\p{Nd}+$//^\pN+$//^\p{Numeric_Value:10}$//^\P{Numeric_Value:NaN}+$//^-?\d+$//^[+-]?\d+$//^-?\d+\.?\d*$//^-?(?:\d+(?:\.\d*)?|\.\d+)$//^([+-]?)(?=\d|\.\d)\d*(\.\d*)?([Ee]([+-]?\d+))?$//^((\d)(?(?=(\d))|$)(?(?{ord$3==1+ord$2})(?1)|$))$//^(?:(?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2}))$//^(?:(?:[0-9a-fA-F]{1,2}):(?:[0-9a-fA-F]{1,2}):(?:[0-9a-fA-F]{1,2}):(?:[0-9a-fA-F]{1,2}):(?:[0-9a-fA-F]{1,2}):(?:[0-9a-fA-F]{1,2}))$//^(?:(?:[+-]?)(?:[0123456789]+))$//(([+-]?)([0123456789]{1,3}(?:,?[0123456789]{3})*))//^(?:(?:[+-]?)(?:[0123456789]{1,3}(?:,?[0123456789]{3})*))$//^(?:(?i)(?:[+-]?)(?:(?=[0123456789]|[.])(?:[0123456789]*)(?:(?:[.])(?:[0123456789]{0,}))?)(?:(?:[E])(?:(?:[+-]?)(?:[0123456789]+))|))$//^(?:(?i)(?:[+-]?)(?:(?=[01]|[.])(?:[01]{1,3}(?:(?:[,])[01]{3})*)(?:(?:[.])(?:[01]{0,}))?)(?:(?:[E])(?:(?:[+-]?)(?:[01]+))|))$//^(?:(?i)(?:[+-]?)(?:(?=[0123456789ABCDEF]|[.])(?:[0123456789ABCDEF]{1,3}(?:(?:[,])[0123456789ABCDEF]{3})*)(?:(?:[.])(?:[0123456789ABCDEF]{0,}))?)(?:(?:[G])(?:(?:[+-]?)(?:[0123456789ABCDEF]+))|))$//((?i)([+-]?)((?=[0123456789]|[.])([0123456789]{1,3}(?:(?:[_,]?)[0123456789]{3})*)(?:([.])([0123456789]{0,}))?)(?:([E])(([+-]?)([0123456789]+))|))/\p{Nd}、\p{Decimal_Number}或\p{General_Category=Decimal_Number}。这实际上只是那些数值类型类别为十进制的代码点的反映,可用作\p{Numeric_Type=Decimal}。\w和\W、\d和\D、\s和\S以及\b或\B映射到适当的 Unicode 属性中。这意味着您不能使用这八个一字符转义中的任何一个来处理 Java 中的任何 Unicode 数据,因为它们只对 ASCII 有效,即使 Java 内部始终使用 Unicode 字符。\pN、\p{Number}或\p{General_Category=Number}属性的字符。这些包括用于罗马数字的\p{Nl}或\p{Letter_Number}和用于上下标和圆形数字的\p{No}或\p{Other_Number}等。Ⅹ)和⑩、⑽、⒑、⓾、❿、➉和➓之类的东西。模式1、2、7-11来自于先前版本的Perl“常见问题”列表中的问题“如何验证输入?”。该部分已被建议使用Abigail和Damian Conway编写的Regexp::Common模块代替。原始模式仍可在Perl Cookbook的Recipe 2.1中找到,“检查字符串是否为有效数字”,其中包括各种不同语言的解决方案,例如ada、common lisp、groovy、guile、haskell、java、merd、ocaml、php、pike、python、rexx、ruby和tcl,可以在the PLEAC project上找到。
模式12可以更清晰地重写
m{
^
(
( \d )
(?(?= ( \d ) ) | $ )
(?(?{ ord $3 == 1 + ord $2 }) (?1) | $ )
)
$
}x
它使用正则表达式递归,这在许多模式引擎中都可以找到,包括Perl和所有基于PCRE的语言。但它还使用了嵌入式代码调用作为第二个条件模式的测试;据我所知,代码调用仅在Perl和PCRE中可用。
模式13-21是从上述Regexp::Common模块派生的。请注意,为简洁起见,这些都没有写入您在生产代码中肯定需要的空格和注释。以下是在/x模式下的示例:
$real_rx = qr{ ( # start $1 to hold entire pattern
( [+-]? ) # optional leading sign, captured into $2
( # start $3
(?= # look ahead for what next char *will* be
[0123456789] # EITHER: an ASCII digit
| [.] # OR ELSE: a dot
) # end look ahead
( # start $4
[0123456789]{1,3} # 1-3 ASCII digits to start the number
(?: # then optionally followed by
(?: [_,]? ) # an optional grouping separator of comma or underscore
[0123456789]{3} # followed by exactly three ASCII digits
) * # repeated any number of times
) # end $4
(?: # begin optional cluster
( [.] ) # required literal dot in $5
( [0123456789]{0,} ) # then optional ASCII digits in $6
) ? # end optional cluster
) # end $3
(?: # begin cluster group
( [E] ) # base-10 exponent into $7
( # exponent number into $8
( [+-] ? ) # optional sign for exponent into $9
( [0123456789] + ) # one or more ASCII digits into $10
) # end $8
| # or else nothing at all
) # end cluster group
) }xi; # end $1 and whole pattern, enabling /x and /i modes
从软件工程的角度来看,上面的/x模式版本仍存在一些问题。首先,有很多代码重复,你会看到相同的[0123456789];如果其中一个序列意外地漏掉了一个数字,会发生什么?其次,你依赖于位置参数,必须计数。这意味着你可能会写出像这样的代码:
(
$real_number, # $1
$real_number_sign, # $2
$pre_exponent_part, # $3
$pre_decimal_point, # $4
$decimal_point, # $5
$post_decimal_point, # $6
$exponent_indicator, # $7
$exponent_number, # $8
$exponent_sign, # $9
$exponent_digits, # $10
) = ($string =~ /$real_rx/);
这实在是太糟糕了!容易弄错编号,很难记住符号名称的位置,而且写起来很繁琐,特别是如果你不需要所有这些部分。将其改为使用命名组而不仅仅是编号组。同样,我将使用 Perl 语法来表示变量,但 Pattern 的内容应该适用于任何支持命名组的地方。
use 5.010; # Perl got named patterns in 5.10
$real_rx = qr{
(?<real_number>
# optional leading sign
(?<real_number_sign> [+-]? )
(?<pre_exponent_part>
(?= # look ahead for what next char *will* be
[0123456789] # EITHER: an ASCII digit
| [.] # OR ELSE: a dot
) # end look ahead
(?<pre_decimal_point>
[0123456789]{1,3} # 1-3 ASCII digits to start the number
(?: # then optionally followed by
(?: [_,]? ) # an optional grouping separator of comma or underscore
[0123456789]{3} # followed by exactly three ASCII digits
) * # repeated any number of times
) # end <pre_decimal_part>
(?: # begin optional anon cluster
(?<decimal_point> [.] ) # required literal dot
(?<post_decimal_point>
[0123456789]{0,} )
) ? # end optional anon cluster
) # end <pre_exponent_part>
# begin anon cluster group:
(?:
(?<exponent_indicator> [E] ) # base-10 exponent
(?<exponent_number> # exponent number
(?<exponent_sign> [+-] ? )
(?<exponent_digits> [0123456789] + )
) # end <exponent_number>
| # or else nothing at all
) # end anon cluster group
) # end <real_number>
}xi;
if ($string =~ /$real_rx/) {
($pre_exponent, $exponent_number) =
@+{ qw< pre_exponent exponent_number > };
}
还有一件事情可以做来让这个模式更易于维护。问题在于仍然存在太多的重复,这意味着它在一个地方很容易被修改,但在另一个地方却不容易。如果你正在进行McCabe分析,你会说它的复杂度指标太高。大多数人会说它缩进太多了,这使得它难以跟踪。为了解决所有这些问题,我们需要一个“语法模式”,其中包含一个定义块来创建命名的抽象,然后我们稍后在匹配中将其视为子程序调用。
use 5.010; # Perl first got regex subs in v5.10
$real__rx = qr{
^ # anchor to front
(?&real_number) # call &real_number regex sub
$ # either at end or before final newline
##################################################
# the rest is definition only; think of ##
# each named buffer as declaring a subroutine ##
# by that name ##
##################################################
(?(DEFINE)
(?<real_number>
(?&mantissa)
(?&abscissa) ?
)
(?<abscissa>
(?&exponent_indicator)
(?&exponent)
)
(?<exponent>
(&?sign) ?
(?&a_digit) +
)
(?<mantissa>
# expecting either of these....
(?= (?&a_digit)
| (?&point)
)
(?&a_digit) {1,3}
(?: (?&digit_separator) ?
(?&a_digit) {3}
) *
(?: (?&point)
(?&a_digit) *
) ?
)
(?<point> [.] )
(?<sign> [+-] )
(?<digit_separator> [_,] )
(?<exponent_indicator> [Ee] )
(?<a_digit> [0-9] )
) # end DEFINE block
}x;
语法模式看起来更像BNF,而不是人们开始讨厌的丑陋的正则表达式。 它们更容易阅读,编写和维护。 所以,不要再使用丑陋的模式了,好吗?
perl -Mv5.14 -MUnicode::UCD=num -CSA -E 'say "$_ is ",num($_) for @ARGV' "४५६७" "໓໑໔໑໕໙"会输出४५६७ is 4567 ໓໑໔໑໕໙ is 314159。这意味着对于数字字符串,您只需要使用/(\d+)/获取它们并调用Unicode::UCD::num函数即可。我不知道Microsoft的国际支持有多好,但肯定比Java好。 - tchrist^[-,0-9]+$。如果你还想允许空格,则使用^[-,0-9 ]+$。^([-+] ?)?[0-9]+(,[0-9]+)?$
或者直接使用.net的数字解析器(有关各种NumberStyles,请参见MSDN):
try {
double.Parse(yourString, NumberStyle.Number);
}
catch(FormatException ex) {
/* Number is not in an accepted format */
}
/^(?:(?:[+-]?)(?:[0123456789]{1,3}(?:,?[0123456789]{3})*))$/可能会满足他的需求,但由于措辞不精确且存在冲突,很难确定。但肯定比你的做得好得多! - tchrist试一下这个:
^-?\d{1,3}(,\d{3})*(\.\d\d)?$|^\.\d\d$
允许:
1
12
.99
12.34
-18.34
12,345.67
999,999,999,999,999.99
C.明智地使用正则表达式工具来节省你的正则表达式能量
在给定范围内匹配数字的问题已经得到解决。你不需要试图重新发明轮子。这是一个可以通过程序机械地解决的问题,而且保证没有错误。充分利用这个免费的方法。对于工具,您可以使用:
RegexMagic(非免费)。这是他的初学者正则表达式产品,据我回忆,它拥有在给定范围内生成数字的许多选项以及其他功能。|将它们连接起来。D. 练习:构建用于问题规格的正则表达式
这些规格相当广泛...但不一定模糊。 让我们再次查看示例值:
123,456,789
-12,34
1234
-8
第一个和第二个值有什么关系?在第一个中,逗号匹配三的幂次方组。在第二个中,它可能匹配欧洲大陆风格数字格式中的小数点。这并不意味着我们应该允许到处都有数字,比如1,2,3,44。同样,我们也不应该太过严格。例如,接受答案中的正则表达式将无法匹配123,456,789这一要求(请参见demo)。
我们如何构建正则表达式以满足规格要求?
^和$将表达式锚定,以避免子匹配-?(?:this|that)的两侧:[1-9][0-9]*(?:,[0-9]+)?[1-9][0-9]{1,2}(?:,[0-9]{3})+完整的正则表达式:
^-?(?:[1-9][0-9]*(?:,[0-9]+)?|[1-9][0-9]{1,2}(?:,[0-9]{3})+)$
请查看演示。
这个正则表达式不允许以0开头的欧洲风格数字,比如0,12。这是一个特性,而不是错误。如果想要匹配它们,只需要进行一点小调整:
^-?(?:(?:0|[1-9][0-9]*)(?:,[0-9]+)?|[1-9][0-9]{1,2}(?:,[0-9]{3})+)$
请查看演示。
^[-+]?(\d{1,3})(,?(?1))*$
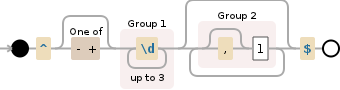
那么它是什么?!
^ 表示字符串开头[-+]? 允许在字符串开头后面加上 负号 或 正号(\d{1,3}) 匹配至少一位数字且最多三位数字 ({1,3}) 并将连续的数字作为第一组进行分组(括号 (...) 建立了一个新组)(,?(?1))* 好吧... 让我们来分解一下
(...) 建立另一个组(不是很重要),? 匹配在第一组数字后面可能存在的逗号(?1) 再次匹配第一组的模式(记得 (\d{1,3}));换言之:此时表达式已经匹配了一个符号(加号/减号/无符号)后面跟着一串数字,可能还有一个逗号,再跟着另一串数字。(,?(?1))* 中的 * 将第二部分(逗号和数字串)重复匹配尽可能多次$ 最后匹配字符串结尾这种表达式的好处在于,避免了反复定义相同的模式;缺点是有时会变得比较复杂 :-/
1,2,3,4,5,这并不是要求的。https://regex101.com/r/T3m0iQ/1你的模式没有区分逗号作为千位分隔符和逗号作为小数点的用法。验证不是很强。 - mickmackusa试试这个:
^-?[\d\,]+$
-作为第一个字符,然后是逗号和数字的任意组合。^-? # start of line, optional -
(\d+ # any number of digits
|(\d{1,3}(,\d{3})*)) # or digits followed by , and three digits
((,|\.)\d+)? # optional comma or period decimal point and more digits
$ # end of line
(,|\.)简化为[,.]呢? - mickmackusajava.util.Scanner和它的useLocale方法。Scanner myScanner = new Scanner(input).useLocale( myLocale)
isADouble = myScanner.hasNextDouble()
试试这个:
boxValue = boxValue.replace(/[^0-9\.\,]/g, "");
这个正则表达式只匹配数字、点和逗号。
关于示例:
^(-)?([,0-9])+$
应该可以工作。使用任何您想要的语言来实现它。
[\d,]+。 - user557597