我有一个数据集,想用这些数据来训练我的模型。训练完毕后,我需要知道哪些特征对SVM分类器的分类起到了主要作用。
森林算法有一个叫做特征重要性的东西,是否有类似的方法呢?
我有一个数据集,想用这些数据来训练我的模型。训练完毕后,我需要知道哪些特征对SVM分类器的分类起到了主要作用。
森林算法有一个叫做特征重要性的东西,是否有类似的方法呢?
是的,SVM分类器有属性coef_,但它仅适用于具有线性核的SVM。对于其他核,由于数据通过核方法转换为与输入空间无关的另一个空间,因此不可能使用该属性。请查看解释。
from matplotlib import pyplot as plt
from sklearn import svm
def f_importances(coef, names):
imp = coef
imp,names = zip(*sorted(zip(imp,names)))
plt.barh(range(len(names)), imp, align='center')
plt.yticks(range(len(names)), names)
plt.show()
features_names = ['input1', 'input2']
svm = svm.SVC(kernel='linear')
svm.fit(X, Y)
f_importances(svm.coef_, features_names)
而该函数的输出看起来像这样: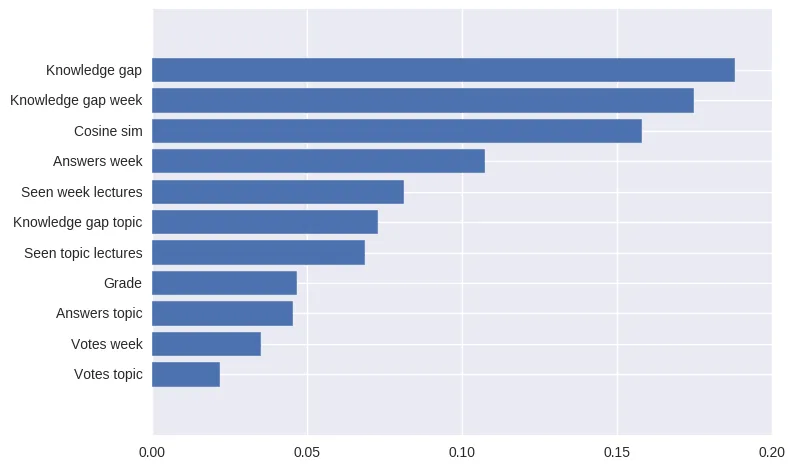
f_importances(svm.coef_[0], features_names) - hongkailsklearn.inspection.permutation_importance来获取特征重要性。[doc]
from sklearn.inspection import permutation_importance
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
svc = SVC(kernel='rbf', C=2)
svc.fit(X_train, y_train)
perm_importance = permutation_importance(svc, X_test, y_test)
feature_names = ['feature1', 'feature2', 'feature3', ...... ]
features = np.array(feature_names)
sorted_idx = perm_importance.importances_mean.argsort()
plt.barh(features[sorted_idx], perm_importance.importances_mean[sorted_idx])
plt.xlabel("Permutation Importance")
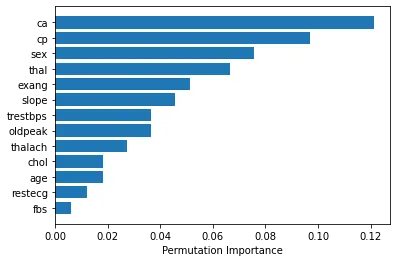
仅需一行代码:
拟合一个SVM模型:
from sklearn import svm
svm = svm.SVC(gamma=0.001, C=100., kernel = 'linear')
并按以下方式实现情节:
pd.Series(abs(svm.coef_[0]), index=features.columns).nlargest(10).plot(kind='barh')
from matplotlib import pyplot as plt
from sklearn import svm
def f_importances(coef, names, top=-1):
imp = coef
imp, names = zip(*sorted(list(zip(imp, names))))
# Show all features
if top == -1:
top = len(names)
plt.barh(range(top), imp[::-1][0:top], align='center')
plt.yticks(range(top), names[::-1][0:top])
plt.show()
# whatever your features are called
features_names = ['input1', 'input2', ...]
svm = svm.SVC(kernel='linear')
svm.fit(X_train, y_train)
# Specify your top n features you want to visualize.
# You can also discard the abs() function
# if you are interested in negative contribution of features
f_importances(abs(clf.coef_[0]), feature_names, top=10)
{kind=link}