我正在使用Disruptor框架对一些数据执行快速的Reed-Solomon纠错。这是我的设置:
RS Decoder 1
/ \
Producer- ... - Consumer
\ /
RS Decoder 8
- 生产者从磁盘读取2064字节大小的块到缓冲区。
- 8个RS解码器消费者同时进行Reed-Solomon纠错。
- 消费者将文件写入磁盘。
在Disruptor DSL术语中,该设置如下:
RsFrameEventHandler[] rsWorkers = new RsFrameEventHandler[numRsWorkers];
for (int i = 0; i < numRsWorkers; i++) {
rsWorkers[i] = new RsFrameEventHandler(numRsWorkers, i);
}
disruptor.handleEventsWith(rsWorkers)
.then(writerHandler);
.then(writerHandler) 部分)时,测得的吞吐量为80 M/s,一旦我添加一个消费者,即使它写入到 /dev/null 中,或者甚至不写入,但被声明为一个依赖的消费者,性能下降到50-65 M/s。我用Oracle Mission Control进行了分析,这是CPU使用率图显示的内容:
没有额外消费者:
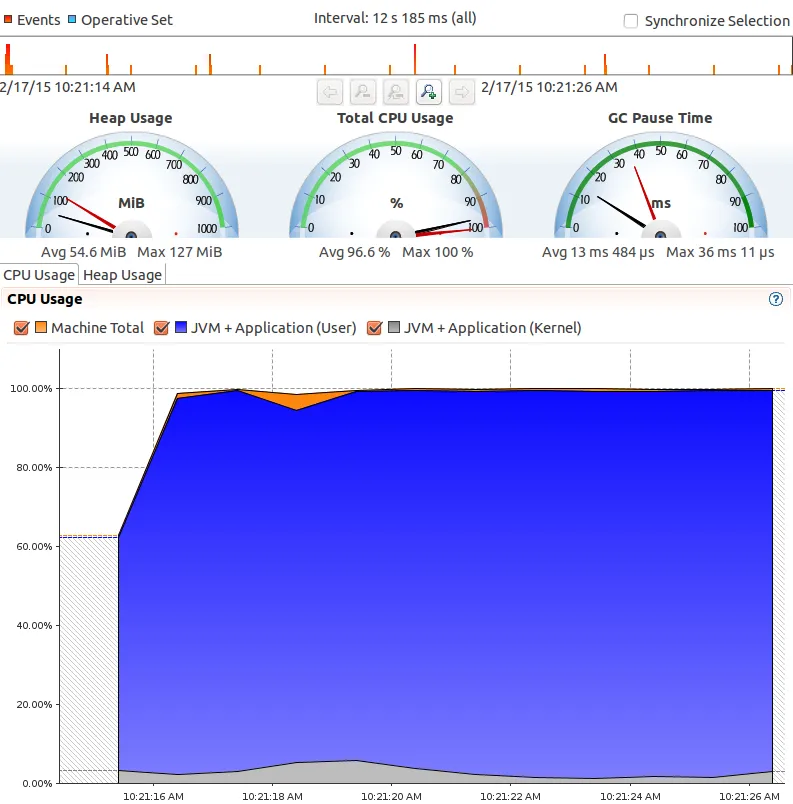 有额外的消费者:
有额外的消费者:
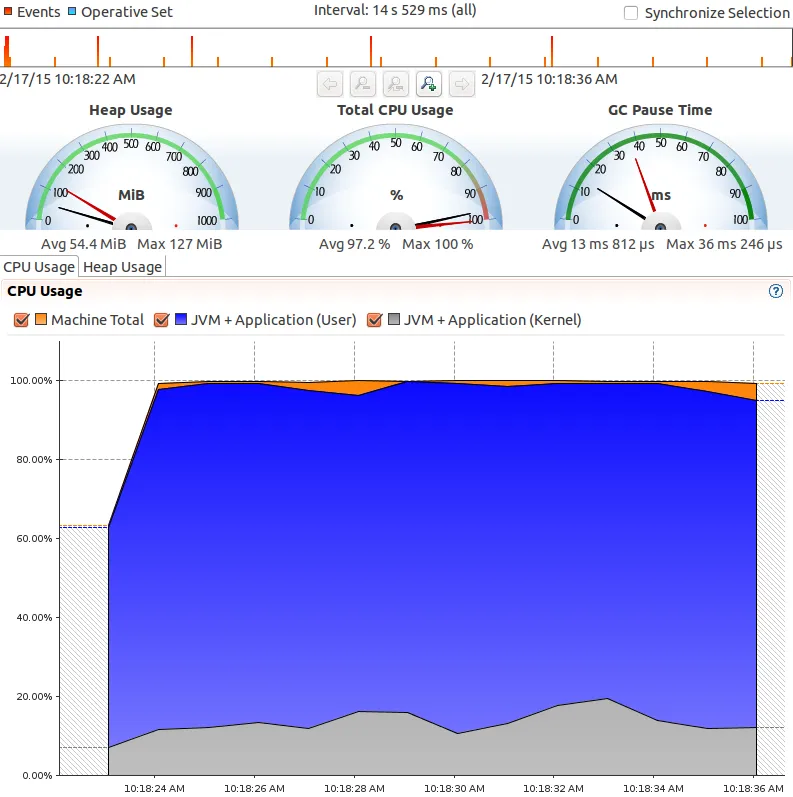 这个图表中的灰色部分是什么?它是从哪里来的?我想这可能与线程同步有关,但我在Mission Control中找不到任何其他统计数据来指示任何这样的延迟或争用。
这个图表中的灰色部分是什么?它是从哪里来的?我想这可能与线程同步有关,但我在Mission Control中找不到任何其他统计数据来指示任何这样的延迟或争用。
.then()方法轮询以查看工作是否完成引起的吗? - fge