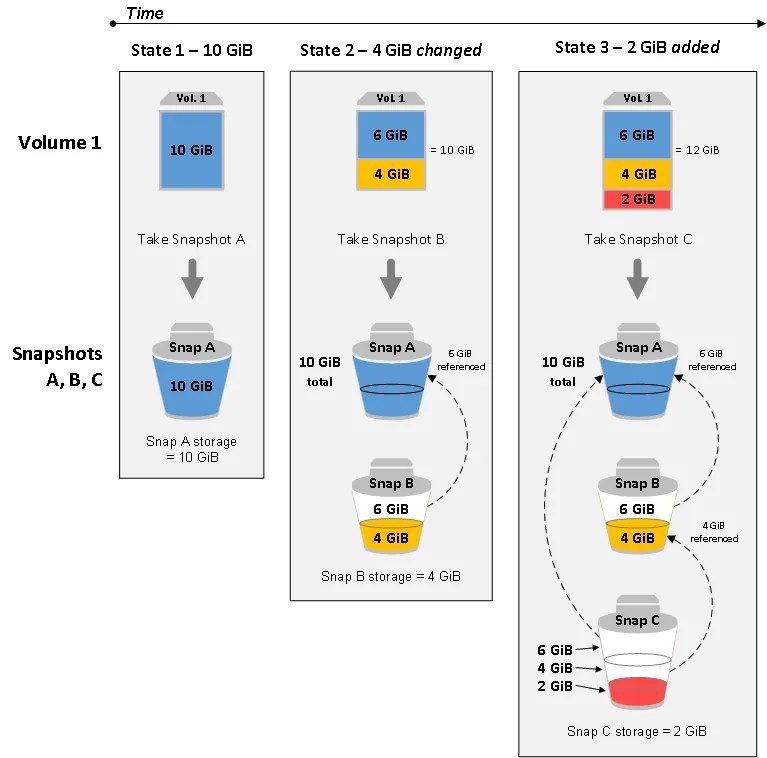
我知道在AWS中,EBS "快照是增量备份,这意味着只有设备上自最近一次快照以来发生更改的块会被保存。"
但是,当使用EBS快照来恢复数据时,如何同时恢复该EBS快照中的所有数据以及以前快照中的数据?
例如,假设我有一个空卷。然后,我添加了10 GB的数据并拍摄了一个快照(快照1)。接着,我又添加了5 GB的数据并拍摄了第二个快照(快照2)。
如果快照仅仅是增量备份,那么当我使用快照2来恢复数据时,我应该只有5 GB的数据。但当我测试时,我得到了15 GB的数据。
我知道增量快照可以最大限度地减少创建快照所需的时间,并通过不复制数据来节省存储成本,但如何使用增量备份来完全恢复数据呢?