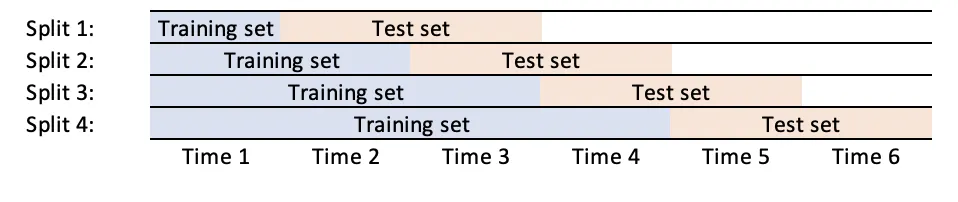
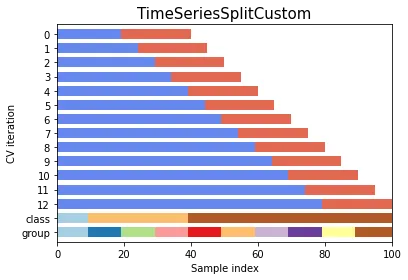
看起来你的需求是将测试集大小增加到1个fold以上。要进行此更改,你需要调整这些行。
我已经进行了这些更改,并添加了一个名为n_test_folds的新参数,以便可以自定义它。
from sklearn.model_selection._split import TimeSeriesSplit
from sklearn.utils.validation import _deprecate_positional_args
from sklearn.utils import indexable
from sklearn.utils.validation import _num_samples
class WindowedTestTimeSeriesSplit(TimeSeriesSplit):
"""
parameters
----------
n_test_folds: int
number of folds to be used as testing at each iteration.
by default, 1.
"""
@_deprecate_positional_args
def __init__(self, n_splits=5, *, max_train_size=None, n_test_folds=1):
super().__init__(n_splits,
max_train_size=max_train_size)
self.n_test_folds=n_test_folds
def split(self, X, y=None, groups=None):
"""Generate indices to split data into training and test set.
Parameters
----------
X : array-like of shape (n_samples, n_features)
Training data, where n_samples is the number of samples
and n_features is the number of features.
y : array-like of shape (n_samples,)
Always ignored, exists for compatibility.
groups : array-like of shape (n_samples,)
Always ignored, exists for compatibility.
Yields
------
train : ndarray
The training set indices for that split.
test : ndarray
The testing set indices for that split.
"""
X, y, groups = indexable(X, y, groups)
n_samples = _num_samples(X)
n_splits = self.n_splits
n_folds = n_splits + self.n_test_folds
if n_folds > n_samples:
raise ValueError(
("Cannot have number of folds ={0} greater"
" than the number of samples: {1}.").format(n_folds,
n_samples))
indices = np.arange(n_samples)
fold_size = (n_samples // n_folds)
test_size = fold_size * self.n_test_folds
test_starts = range(fold_size + n_samples % n_folds,
n_samples-test_size+1, fold_size)
for test_start in test_starts:
if self.max_train_size and self.max_train_size < test_start:
yield (indices[test_start - self.max_train_size:test_start],
indices[test_start:test_start + test_size])
else:
yield (indices[:test_start],
indices[test_start:test_start + test_size])
例子:
import numpy as np
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
tscv = WindowedTestTimeSeriesSplit(n_splits=4, n_test_folds=2)
print(tscv)
for train_index, test_index in tscv.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
注意: TRAIN: [0 1 2 3 4] TEST: [5] 没有生成,因为它不满足测试折数的要求。
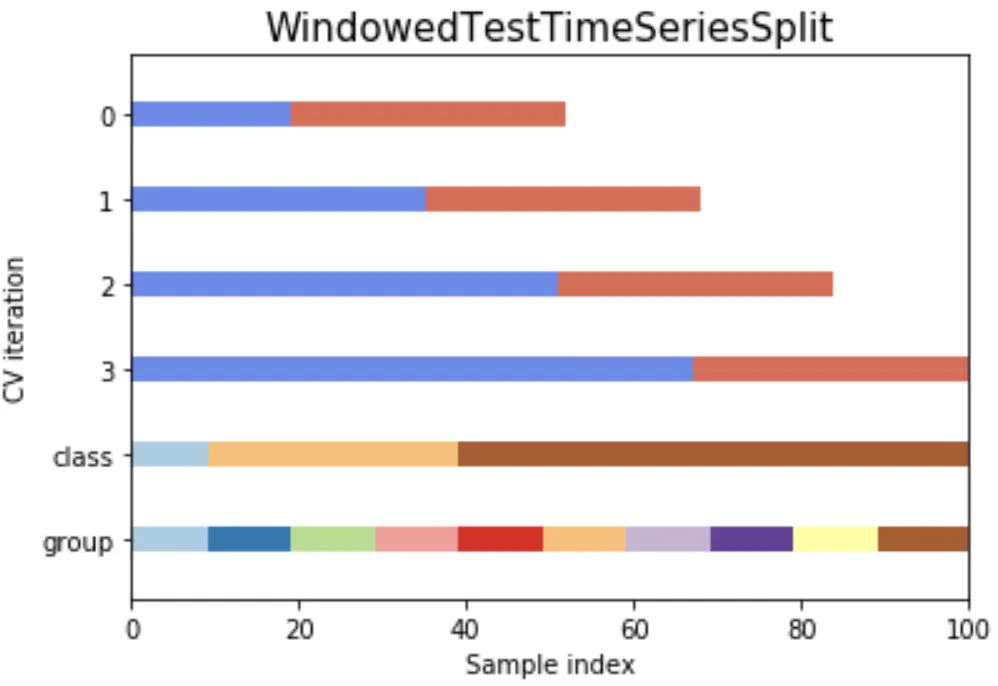
使用此函数,我们可以可视化CV的不同分割方式。请参考
此处。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
np.random.seed(1338)
cmap_data = plt.cm.Paired
cmap_cv = plt.cm.coolwarm
n_splits = 4
n_points = 100
X = np.random.randn(100, 10)
percentiles_classes = [.1, .3, .6]
y = np.hstack([[ii] * int(100 * perc)
for ii, perc in enumerate(percentiles_classes)])
groups = np.hstack([[ii] * 10 for ii in range(10)])
fig, ax = plt.subplots()
cv = WindowedTestTimeSeriesSplit(n_splits=n_splits, n_test_folds=2)
plot_cv_indices(cv, X, y, groups, ax, n_splits)
plt.show()