我是BeautifulSoup4的新手,遇到了一个看起来很基础的问题。我只能通过id查找,而不能通过class查找。例如,我正在查看一个网站,其中包含以下html部分:
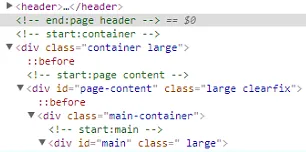
page_soup.findAll('div', {'id': 'page-content'})
而以下内容找不到:
page_soup.findAll('div', {'class': 'main-container'})
所以我的问题是:'class'和'id'属性有不同的处理方式吗?如果是这样,那么按类名搜索的正确方法是什么?
只是为了完整起见,虽然我认为这并不重要,但我使用
selenium包的page_source方法获得了html。编辑:这里是这样一个页面的示例。如果我们检查上面的表格,包括球员的位置、年龄等等,那么我们就会得到上面的html快照。
{'class: 'main-container'}- Dominic K