我对C#非常陌生,正在尝试编写一个基本程序。目标是在给定URL的情况下获取图像并将其保存到磁盘。
这就是我的代码基本超时的地方:
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(m.Value.Trim()); // url string passed in from Regex function
HttpWebResponse resp = (HttpWebResponse) req.GetResponse(); // times out here
这段代码位于一个包含一个函数的类中,其运行方式如下:
String url; // passed in as a parameter
String folder = @"C:\SMBC";
// create directory if not exists to save comic
if(!Directory.Exists(folder))
Directory.CreateDirectory(folder);
// visit the site and check for comics
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Method = "GET";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
using (StreamReader reader = new StreamReader(response.GetResponseStream()))
{
while (reader.Peek() >= 0)
{
// if line contains "/comics/" then I'm in the right spot, we're at a URL now
String line = reader.ReadLine();
if (line.Contains("/comics/"))
{
// pull out the address of the image // example result: http://www.smbc-comics.com/comics/20020905-2.gif
Regex linkParser = new Regex(@"\b(?:https?://|www\.)\S+\b", RegexOptions.Compiled | RegexOptions.IgnoreCase);
foreach (Match m in linkParser.Matches(line))
{
// new local file in folder, use original file name
String name = @"" + folder +"\\" + m.Value.Substring(m.Value.LastIndexOf("/") + 1);
Console.WriteLine(m.Value.Trim()); //http://www.smbc-comics.com/comics/20020905-2.gif
Uri uri = new Uri(m.Value.Trim());
Console.WriteLine("Making request"); // works
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(m.Value.Trim());
Console.WriteLine("getting response"); // works
HttpWebResponse resp = (HttpWebResponse) req.GetResponse();
Console.WriteLine("opening stream"); // never shows
using (Stream inputStream = resp.GetResponseStream())
using (Stream outputStream = File.OpenWrite(name))
{
byte[] buffer = new byte[4096];
int bytesRead;
do
{
bytesRead = inputStream.Read(buffer, 0, buffer.Length);
outputStream.Write(buffer, 0, bytesRead);
} while (bytesRead != 0);
//outputStream.Close();
//inputStream.Close();
//resp.Close();
}
}
}
}
}
我在控制台中运行此命令,以下是我得到的结果:
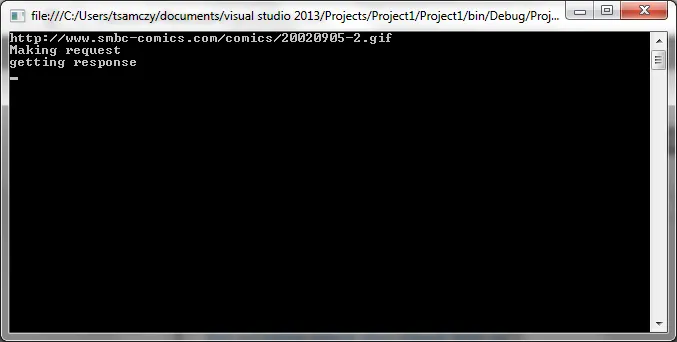 一段时间后,操作就会超时,我知道该地址是有效的,因为我已经访问过它。
一段时间后,操作就会超时,我知道该地址是有效的,因为我已经访问过它。我是否漏掉了什么?