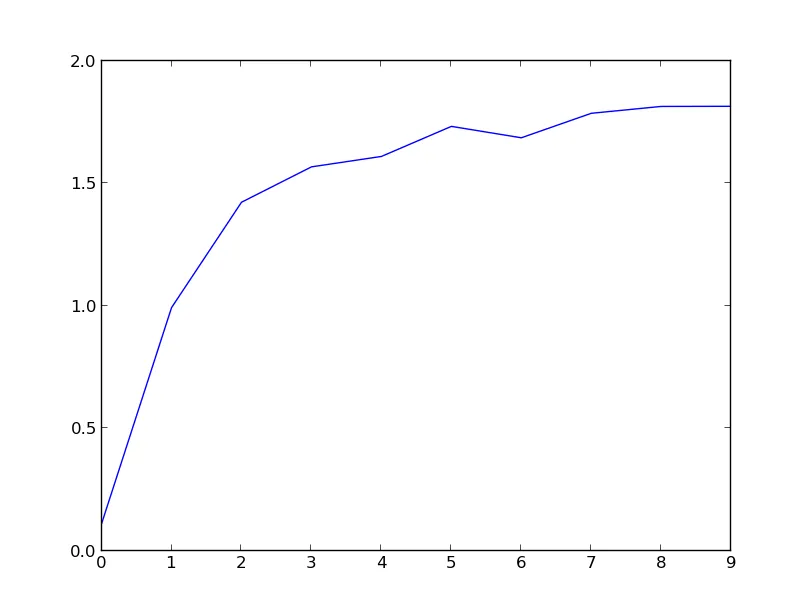
我正在尝试将gap统计和预测强度的R实现http://edchedch.wordpress.com/2011/03/19/counting-clusters/翻译为Python脚本,以估计3个群集的鸢尾花数据的数量。但是,每次运行时得到的结果都不同,估计出的群集数量与实际的3个相差很大。图表显示估计数量为10而不是3。我是否漏掉了什么?有人能帮我找出问题所在吗?
import random
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
def dispersion (data, k):
if k == 1:
cluster_mean = np.mean(data, axis=0)
distances_from_mean = np.sum((data - cluster_mean)**2,axis=1)
dispersion_val = np.log(sum(distances_from_mean))
else:
k_means_model_ = KMeans(n_clusters=k, max_iter=50, n_init=5).fit(data)
distances_from_mean = range(k)
for i in range(k):
distances_from_mean[i] = int()
for idx, label in enumerate(k_means_model_.labels_):
if i == label:
distances_from_mean[i] += sum((data[idx] - k_means_model_.cluster_centers_[i])**2)
dispersion_val = np.log(sum(distances_from_mean))
return dispersion_val
def reference_dispersion(data, num_clusters, num_reference_bootstraps):
dispersions = [dispersion(generate_uniform_points(data), num_clusters) for i in range(num_reference_bootstraps)]
mean_dispersion = np.mean(dispersions)
stddev_dispersion = float(np.std(dispersions)) / np.sqrt(1. + 1. / num_reference_bootstraps)
return mean_dispersion
def generate_uniform_points(data):
mins = np.argmin(data, axis=0)
maxs = np.argmax(data, axis=0)
num_dimensions = data.shape[1]
num_datapoints = data.shape[0]
reference_data_set = np.zeros((num_datapoints,num_dimensions))
for i in range(num_datapoints):
for j in range(num_dimensions):
reference_data_set[i][j] = random.uniform(data[mins[j]][j],data[maxs[j]][j])
return reference_data_set
def gap_statistic (data, nthCluster, referenceDatasets):
actual_dispersion = dispersion(data, nthCluster)
ref_dispersion = reference_dispersion(data, nthCluster, num_reference_bootstraps)
return actual_dispersion, ref_dispersion
if __name__ == "__main__":
data=np.loadtxt('iris.mat', delimiter=',', dtype=float)
maxClusters = 10
num_reference_bootstraps = 10
dispersion_values = np.zeros((maxClusters,2))
for cluster in range(1, maxClusters+1):
dispersion_values_actual,dispersion_values_reference = gap_statistic(data, cluster, num_reference_bootstraps)
dispersion_values[cluster-1][0] = dispersion_values_actual
dispersion_values[cluster-1][1] = dispersion_values_reference
gaps = dispersion_values[:,1] - dispersion_values[:,0]
print gaps
print "The estimated number of clusters is ", range(maxClusters)[np.argmax(gaps)]+1
plt.plot(range(len(gaps)), gaps)
plt.show()
{kind=link}
{kind=link}
random_state参数为None(这会导致使用np.random)。如果你想获得持久的结果,你应该像这样做:KMeans(n_clusters=k, max_iter=50, n_init=5, random_state=1234)。 - VnC