首先作为基准,现有方法在我的机器上的时间:
Original program posted in the question:
time stack exec primorig
95673602693282040
real 0m4.601s
user 0m4.387s
sys 0m0.251s
Second the version using Data.IntMap.Strict from
here
time stack exec primIntMapStrict
95673602693282040
real 0m2.775s
user 0m2.753s
sys 0m0.052s
Shershs code with Data.Judy dropped in here
time stack exec prim-hash2
95673602693282040
real 0m0.945s
user 0m0.955s
sys 0m0.028s
Your python solution.
I compiled it with
python -O -m py_compile problem10.py
and the timing:
time python __pycache__/problem10.cpython-36.opt-1.pyc
95673602693282040
real 0m1.163s
user 0m1.160s
sys 0m0.003s
Your C++ version:
$ g++ -O2 --std=c++11 p10.cpp -o p10
$ time ./p10
sum(2000000000) = 95673602693282040
real 0m0.314s
user 0m0.310s
sys 0m0.003s
我没有为slow.hs提供基准,因为我不想等待使用
2*10^9作为参数运行时完成。
次秒级性能
下面的程序在我的机器上不到一秒钟就可以运行。
它使用手动编写的哈希映射表,采用闭散列和线性探测,并使用某种变体的Knuth哈希函数,请参见
这里。
当然,它在某种程度上是针对特定情况进行了优化,例如查找函数期望搜索键存在。
计时:
time stack exec prim
95673602693282040
real 0m0.725s
user 0m0.714s
sys 0m0.047s
首先,我实现了自己的哈希映射表,仅仅是用来散列键值对。
key `mod` size
我选择了一个比预期输入大多倍的尺寸,但程序需要22秒或更长时间才能完成。
最后,关键是选择适合工作负载的哈希函数。
以下是程序:
import Data.Maybe
import Control.Monad
import Data.Array.IO
import Data.Array.Base (unsafeRead)
type Number = Int
data Map = Map { keys :: IOUArray Int Number
, values :: IOUArray Int Number
, size :: !Int
, factor :: !Int
}
newMap :: Int -> Int -> IO Map
newMap s f = do
k <- newArray (0, s-1) 0
v <- newArray (0, s-1) 0
return $ Map k v s f
storeKey :: IOUArray Int Number -> Int -> Int -> Number -> IO Int
storeKey arr s f key = go ((key * f) `mod` s)
where
go :: Int -> IO Int
go ind = do
v <- readArray arr ind
go2 v ind
go2 v ind
| v == 0 = do { writeArray arr ind key; return ind; }
| v == key = return ind
| otherwise = go ((ind + 1) `mod` s)
loadKey :: IOUArray Int Number -> Int -> Int -> Number -> IO Int
loadKey arr s f key = s `seq` key `seq` go ((key *f) `mod` s)
where
go :: Int -> IO Int
go ix = do
v <- unsafeRead arr ix
if v == key then return ix else go ((ix + 1) `mod` s)
insertIntoMap :: Map -> (Number, Number) -> IO Map
insertIntoMap m@(Map ks vs s f) (k, v) = do
ix <- storeKey ks s f k
writeArray vs ix v
return m
fromList :: Int -> Int -> [(Number, Number)] -> IO Map
fromList s f xs = do
m <- newMap s f
foldM insertIntoMap m xs
(!) :: Map -> Number -> IO Number
(!) (Map ks vs s f) k = do
ix <- loadKey ks s f k
readArray vs ix
mupdate :: Map -> Number -> (Number -> Number) -> IO ()
mupdate (Map ks vs s fac) i f = do
ix <- loadKey ks s fac i
old <- readArray vs ix
let x' = f old
x' `seq` writeArray vs ix x'
r' :: Number -> Number
r' = floor . sqrt . fromIntegral
vs' :: Integral a => a -> a -> [a]
vs' n r = [n `div` i | i <- [1..r]] ++ reverse [1..n `div` r - 1]
vss' n r = r + n `div` r -1
list' :: Int -> Int -> [Number] -> IO Map
list' s f vs = fromList s f [(i, i * (i + 1) `div` 2 - 1) | i <- vs]
problem10 :: Number -> IO Number
problem10 n = do
m <- list' (19*vss) (19*vss+7) vs
nm <- sieve m 2 r vs
nm ! n
where vs = vs' n r
vss = vss' n r
r = r' n
sieve :: Map -> Number -> Number -> [Number] -> IO Map
sieve m p r vs | p > r = return m
| otherwise = do
v1 <- m ! p
v2 <- m ! (p - 1)
nm <- if v1 > v2 then update m vs p else return m
sieve nm (p + 1) r vs
update :: Map -> [Number] -> Number -> IO Map
update m vs p = foldM (decrease p) m $ takeWhile (>= p*p) vs
decrease :: Number -> Map -> Number -> IO Map
decrease p m k = do
v <- sumOfSieved m k p
mupdate m k (subtract v)
return m
sumOfSieved :: Map -> Number -> Number -> IO Number
sumOfSieved m v p = do
v1 <- m ! (v `div` p)
v2 <- m ! (p - 1)
return $ p * (v1 - v2)
main = do { n <- problem10 (2*10^9) ; print n; }
我对哈希和相关技术不是专业的,所以这个可以被大大改进。也许我们Haskellers应该改进现成的哈希映射或提供一些更简单的。
我的哈希映射,Shershs代码
如果我把我的哈希映射插入到Shershs(见下面的答案)代码中,请参见此处,我们甚至降到了
time stack exec prim-hash2
95673602693282040
real 0m0.601s
user 0m0.604s
sys 0m0.034s
为什么slow.hs很慢?
如果你阅读Data.HashTable.ST.Basic中insert函数的源代码,你会发现它删除了旧的键值对并插入了一个新的键值对。它没有查找值的“位置”并进行更改,正如人们可能想象的那样,如果他们读到它是一个“可变”哈希表。在这里,哈希表本身是可变的,因此您不需要复制整个哈希表以插入新的键值对,但是对于键值对的值位置则不然。我不知道这就是slow.hs缓慢的整个故事,但我的猜测是,这是其中相当大的一部分。
一些小改进
这就是我第一次尝试改进程序时遵循的思路。
看,你不需要从键到值的可变映射。你的键集已经固定了。你需要一个从键到可变位置的映射。 (顺便说一下,默认情况下C++就是这样做的。)
因此,我尝试想出一个这样的解决方案。我首先使用了Data.IntMap.Strict和Data.IORef中的IntMap IORef,其时间为
tack exec prim
95673602693282040
real 0m2.134s
user 0m2.141s
sys 0m0.028s
我认为使用非装箱值可能会有所帮助。为此,我使用每个仅包含1个元素的IOUArray Int Int代替IORef进行测试,并得出以下结果:
time stack exec prim
95673602693282040
real 0m2.015s
user 0m2.018s
sys 0m0.038s
这两种方法并没有太大区别,所以我尝试使用unsafeRead和unsafeWrite来消除1元素数组中的边界检查,并获得了以下时间:
time stack exec prim
95673602693282040
real 0m1.845s
user 0m1.850s
sys 0m0.030s
我使用 Data.IntMap.Strict 得到了最佳结果。
当然,我运行了每个程序多次以查看时间是否稳定,并且运行时间的差异不只是噪声。
看起来这些都只是微小的优化。
以下是在不使用手动构建的数据结构时,对我来说运行最快的程序:
import qualified Data.IntMap.Strict as M
import Control.Monad
import Data.Array.IO
import Data.Array.Base (unsafeRead, unsafeWrite)
type Number = Int
type Place = IOUArray Number Number
type Map = M.IntMap Place
tupleToRef :: (Number, Number) -> IO (Number, Place)
tupleToRef = traverse (newArray (0,0))
insertRefs :: [(Number, Number)] -> IO [(Number, Place)]
insertRefs = traverse tupleToRef
fromList :: [(Number, Number)] -> IO Map
fromList xs = M.fromList <$> insertRefs xs
(!) :: Map -> Number -> IO Number
(!) m i = unsafeRead (m M.! i) 0
mupdate :: Map -> Number -> (Number -> Number) -> IO ()
mupdate m i f = do
let place = m M.! i
old <- unsafeRead place 0
let x' = f old
x' `seq` unsafeWrite place 0 x'
r' :: Number -> Number
r' = floor . sqrt . fromIntegral
vs' :: Integral a => a -> a -> [a]
vs' n r = [n `div` i | i <- [1..r]] ++ reverse [1..n `div` r - 1]
list' :: [Number] -> IO Map
list' vs = fromList [(i, i * (i + 1) `div` 2 - 1) | i <- vs]
problem10 :: Number -> IO Number
problem10 n = do
m <- list' vs
nm <- sieve m 2 r vs
nm ! n
where vs = vs' n r
r = r' n
sieve :: Map -> Number -> Number -> [Number] -> IO Map
sieve m p r vs | p > r = return m
| otherwise = do
v1 <- m ! p
v2 <- m ! (p - 1)
nm <- if v1 > v2 then update m vs p else return m
sieve nm (p + 1) r vs
update :: Map -> [Number] -> Number -> IO Map
update m vs p = foldM (decrease p) m $ takeWhile (>= p*p) vs
decrease :: Number -> Map -> Number -> IO Map
decrease p m k = do
v <- sumOfSieved m k p
mupdate m k (subtract v)
return m
sumOfSieved :: Map -> Number -> Number -> IO Number
sumOfSieved m v p = do
v1 <- m ! (v `div` p)
v2 <- m ! (p - 1)
return $ p * (v1 - v2)
main = do { n <- problem10 (2*10^9) ; print n; }
如果你分析一下,会发现大部分时间都花在了自定义查找函数
(!)上,不知道如何进一步改进。尝试使用
{-# INLINE (!) #-}内联
(!)并没有取得更好的结果;也许ghc已经这样做了。
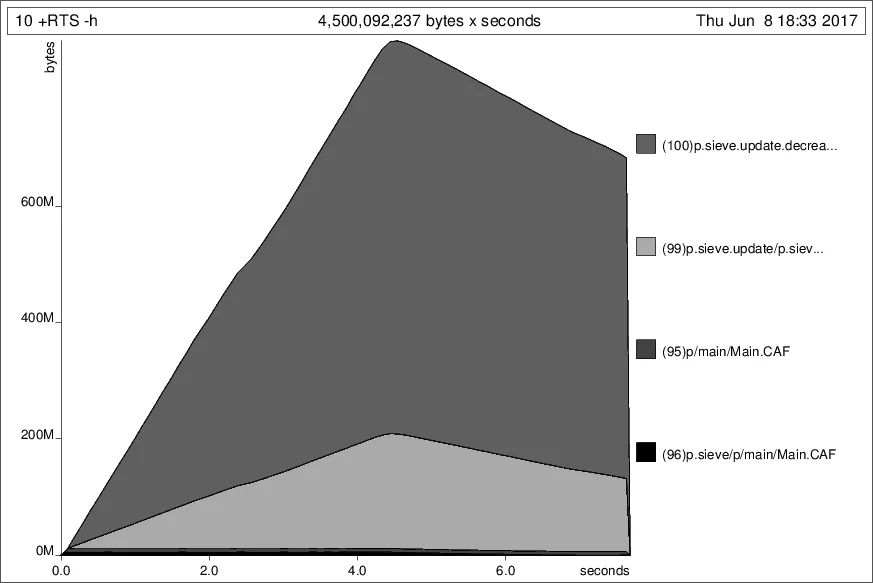
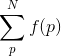
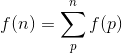
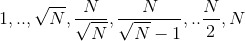
sieve、update、decrease和sumOfsieved分离出来了,希望这有所帮助。 - Adam StelmaszczykInteger改成了Int,代码在这里。这将运行时间缩短到了5秒。 - Adam Stelmaszczyk