一个丢失更新是指在同一时间内,两个不同的事务试图更新数据库中同一行的同一列。通常情况下,一个事务更新了特定行中的特定列,而另一个事务开始后很短时间内也在更新相同的值,但在更新之前没有看到第一个事务所做的更新。然后第一个事务的结果被第二个事务简单地覆盖,因此“丢失”。--https://morpheusdata.com/blog/2015-02-21-lost-update-db
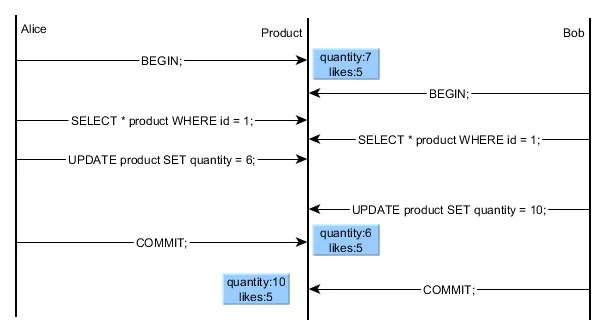
In case of optimistic locking you formulate your update-statement so that in case of a change between select and update, no update occurs. In your case you can do that using:
UPDATE product set quantity = 10
where id = 1 and quantity = <original quantity -- 7>
if not the expected number of records, usually 1, has been updated, because an update of the quantity has been done meanwhile by another process, then you have to repeat the select before the update. How do you find out, how many records have been updated? that depends on the technology you use to do your db-requests, but in my experience every Sql-Dbms returns that information to its client.
例如,有一个产品表,其中包含如下所示的id、name和stock。*当客户购买产品时,产品的库存会减少。
产品表:| id | name | stock |
|---|---|---|
| 1 | 苹果 | 10 |
| 2 | 橙子 | 20 |
首先,以下这些步骤不使用SELECT FOR UPDATE会在MySQL上显示丢失更新:
| 流程 | 事务 1(T1) | 事务 2(T2) | 说明 |
|---|---|---|---|
| 步骤 1 | BEGIN; |
T1 开始。 | |
| 步骤 2 | BEGIN; |
T2 开始。 | |
| 步骤 3 | SELECT stock FROM product WHERE id = 2 FOR UPDATE;20 |
T1 读取 20,稍后更新为 13,因为有顾客购买了 7 个橙子。 |
|
| 步骤 4 | SELECT stock FROM product WHERE id = 2 FOR UPDATE;20 |
T2 读取 20,稍后更新为 16,因为有顾客购买了 4 个橙子。 |
|
| 步骤 5 | UPDATE product SET stock = '13' WHERE id = 2; |
T1 将 20 更新为 13。 |
|
| 步骤 6 | COMMIT; |
T1 提交。 | |
| 步骤 7 | UPDATE product SET stock = '16' WHERE id = 2; |
T2 在 T1 提交后将 13 更新为 16。 |
|
| 步骤 8 | COMMIT; |
T2 提交。*出现了丢失更新问题。 |
其次,以下步骤展示了如何在MySQL上使用SELECT FOR UPDATE来预防丢失更新:
| 流程 | 事务1(T1) | 事务2(T2) | 说明 |
|---|---|---|---|
| 步骤1 | BEGIN; |
T1开始。 | |
| 步骤2 | BEGIN; |
T2开始。 | |
| 步骤3 | SELECT stock FROM product WHERE id = 2 FOR UPDATE;20 |
使用“SELECT FOR UPDATE”,T1读取20,稍后将其更新为13,因为有一个客户购买了7个橙子。 |
|
| 步骤4 | SELECT stock FROM product WHERE id = 2 FOR UPDATE; |
T2需要等待T1提交才能使用“SELECT FOR UPDATE”读取stock。 |
|
| 步骤5 | UPDATE product SET stock = '13' WHERE id = 2; |
等待中... | T1将20更新为13。 |
| 步骤6 | COMMIT; |
等待中... | T1提交。 |
| 步骤7 | SELECT stock FROM product WHERE id = 2 FOR UPDATE;13 |
现在使用“SELECT FOR UPDATE”,T2读取13,稍后将其更新为9,因为有一个客户购买了4个橙子。 |
|
| 步骤8 | UPDATE product SET stock = '9' WHERE id = 2; |
T2在T1提交后将13更新为9。 |
|
| 步骤9 | COMMIT; |
T2提交。*不会发生丢失更新。 |
COMMIT事务。现在来谈细节:
START TRANSACTION或禁用自动提交:$mysqli->autocommit(FALSE);ROLLBACK并停止正在进行的操作COMMIT更改,否则系统将认为发生了错误并为您ROLLBACK。要么
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
-- 这样会有一些死锁和性能损失
-- 不像看起来那么糟糕,但取决于您的需求
-- 对于InnoDB,REPEATABLE READ是默认级别
或者
SELECT FOR UPDATE
-- 好吧,你编写了代码,你知道哪些选择需要锁定其他人
-- 这假设您的隔离级别为READ_COMMITTED
更多关于隔离级别的信息可以在MySQL文档中找到(这次简短明了) https://dev.mysql.com/doc/refman/5.5/en/innodb-transaction-isolation-levels.html