我已经使用cachegrind在Linux上对一款计算密集型的C++程序进行了性能分析。令人惊讶的是,我的程序瓶颈不在任何排序或计算方法上...而是在读取输入时。
以下是cachegrind的截图,以防我误解性能分析器结果(请参见
我使用
如果您没有发现这个输入读取代码的任何问题,能否推荐一种更快的读取输入的方法?我正在考虑尝试
我所说的“太慢”是指,这是一个更大的作业任务的一部分,在一定时间后会超时(我认为是90秒)。我非常有信心瓶颈在这里,因为我故意注释掉了程序的其他主要部分,它仍然超时。我不知道教练运行我的程序的测试用例是什么,但它肯定是一个巨大的输入文件。那么,我可以使用什么方法来最快地读取输入?
输入格式很严格:每行3个以空格分隔的整数,有多行:
示例输入:
我需要在每行整数中制作一条道路。
另请注意,输入被重定向到我的程序的标准输入(
更新
使用 Slava的方法:
输入读取似乎需要更少的时间,但仍然超时(可能不再是由于输入读取)。Slava的方法已经实现在
使用 enhzflep的方法
以下是cachegrind的截图,以防我误解性能分析器结果(请参见
scanf()):
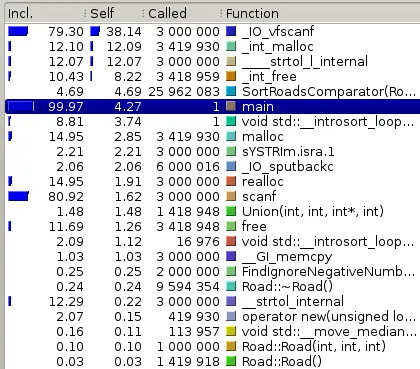
scanf() 占用了 80.92% 的运行时间。我使用
cin >> int_variable_here 来读取输入,就像这样:std::ios_base::sync_with_stdio (false); // Supposedly makes I/O faster
cin >> NumberOfCities;
cin >> NumberOfOldRoads;
Roads = new Road[NumberOfOldRoads];
for (int i = 0; i < NumberOfOldRoads; i++)
{
int cityA, cityB, length;
cin >> cityA;
//scanf("%d", &cityA); // scanf() and cin are both too slow
cin >> cityB;
//scanf("%d", &cityB);
cin >> length;
//scanf("%d", &length);
Roads[i] = Road(cityA, cityB, length);
}
如果您没有发现这个输入读取代码的任何问题,能否推荐一种更快的读取输入的方法?我正在考虑尝试
getline()(在等待响应时进行尝试)。我的猜测是getline()可能会更快,因为它需要做更少的转换并且解析流的总次数较少(只是我的猜测,但最终我也必须将字符串解析为整数)。我所说的“太慢”是指,这是一个更大的作业任务的一部分,在一定时间后会超时(我认为是90秒)。我非常有信心瓶颈在这里,因为我故意注释掉了程序的其他主要部分,它仍然超时。我不知道教练运行我的程序的测试用例是什么,但它肯定是一个巨大的输入文件。那么,我可以使用什么方法来最快地读取输入?
输入格式很严格:每行3个以空格分隔的整数,有多行:
示例输入:
7 8 3
7 9 2
8 9 1
0 1 28
0 5 10
1 2 16
我需要在每行整数中制作一条道路。
另请注意,输入被重定向到我的程序的标准输入(
myprogram < whatever_test_case.txt)。我没有读取特定的文件。我只是从cin读取。更新
使用 Slava的方法:
输入读取似乎需要更少的时间,但仍然超时(可能不再是由于输入读取)。Slava的方法已经实现在
Road() ctor(从main开始往下数2个)。所以现在它只需要80%的时间。我正在考虑优化SortRoadsComparator(),因为它被调用了26,000,000次。
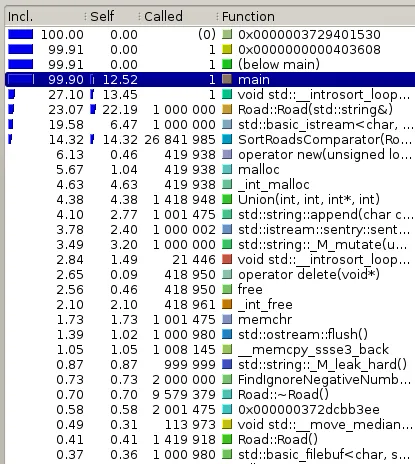
比较器代码:
// The complexity is sort of required for the whole min() max(), based off assignment instructions
bool SortRoadsComparator(const Road& a, const Road& b)
{
if (a.Length > b.Length)
return false;
else if (b.Length > a.Length)
return true;
else
{
// Non-determinism case
return ( (min(a.CityA, a.CityB) < min(b.CityA, b.CityB)) ||
(
(min(a.CityA, a.CityB) == min(b.CityA, b.CityB)) && max(a.CityA, a.CityB) < max(b.CityA, b.CityB)
)
);
}
}
使用 enhzflep的方法
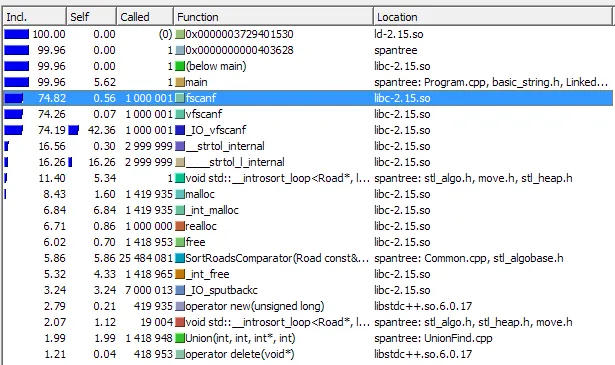
问题已解决
我认为这个问题已经解决了,因为瓶颈不再是读取输入。对于我来说,Slava的方法是最快的。
cin就是一个文件。如果您想要查看scanf是否真的成为瓶颈,那么您应该从内存中读取(即,事先将整个文件读入内存,并在分析数据时忽略它)。 - vanzagetline(cin, string, EOF)的重载版本,它应该一次性读取所有内容。我将首先按\n分割以分隔每行,然后按cin的for循环(没有roads[i] = ...和程序中的其他内容),那么需要多长时间? - Shahbaz