我搜索了一下,但没有找到这个问题的答案。
我建立了一个非二叉树,因此每个节点可以有任意数量的子节点(我认为称为n元树)。
为了帮助搜索,我在构建树时给每个节点赋予了一个数字,以便每个节点的子节点都比它大,并且它右侧的所有节点也都比它大。
类似于这样:
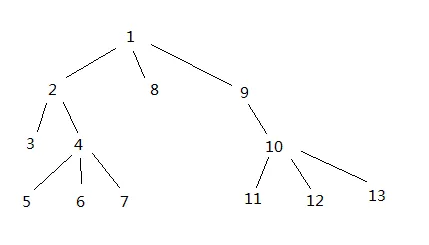
这样我就可以在搜索中得到较长的时间。
问题出现在我想要插入节点时。如果我要将节点插入到任意位置,那么这个模型就行不通了。
我想了几种方法:
将新节点插入到所需位置,然后更新其后面所有节点的数量。
不使用单个数字来表示每个节点,而是使用数字数组。数组中的数字表示该特定级别上其位置。例如,节点1将是{0}。节点9将是{0,2}。节点7将是{0,0,1,2}。现在在插入时,只需要改变该级别上的数字即可。
忘记所有编号,只是比较每个节点,直到找到正确的节点。插入也不需要关心数字。
我的问题是,哪种方式更好?我不确定使用整数数组来表示每个节点是否非常快速..也许仍然比第一种方式更快?还有其他方法可以处理这个问题吗?
提前感谢您。