在MySQL中有没有类似于SQL Server函数 ROW_NUMBER() 的好用的方法可以实现相似功能?
比如:
SELECT
col1, col2,
ROW_NUMBER() OVER (PARTITION BY col1, col2 ORDER BY col3 DESC) AS intRow
FROM Table1
我可以举个例子,比如添加一个条件限制intRow为1,以获取每个(col1, col2)对中最高col3的单行。
在MySQL中有没有类似于SQL Server函数 ROW_NUMBER() 的好用的方法可以实现相似功能?
比如:
SELECT
col1, col2,
ROW_NUMBER() OVER (PARTITION BY col1, col2 ORDER BY col3 DESC) AS intRow
FROM Table1
我可以举个例子,比如添加一个条件限制intRow为1,以获取每个(col1, col2)对中最高col3的单行。
WITH data(row_num, some_val) AS
(
SELECT 1 row_num, 1 some_val FROM any_table --dual in Oracle
UNION ALL
SELECT row_num+1, some_val+row_num FROM data WHERE row_num < 20 -- any number
)
SELECT * FROM data
WHERE row_num BETWEEN 5 AND 10
/
ROW_NUM SOME_VAL
-------------------
5 11
6 16
7 22
8 29
9 37
10 46
SELECT col1, col2, col3 FROM (
SELECT col1, col2, col3,
@n := CASE WHEN @v = MAKE_SET(3, col1, col2)
THEN @n + 1 -- if we are in the same group
ELSE 1 -- next group starts so we reset the counter
END AS row_number,
@v := MAKE_SET(3, col1, col2) -- we store the current value for next iteration
FROM Table1, (SELECT @n := 0, @v := NULL) r -- helper table for iteration with startup values
ORDER BY col1, col2, col3 DESC -- because we want the row with maximum value
) x WHERE row_number = 1 -- and here we select exactly the wanted row from each group
ORDER BY可能会被忽略(请参阅https://mariadb.com/kb/en/mariadb/why-is-order-by-in-a-from-subquery-ignored/)。建议的解决方法是向子查询添加`LIMIT 18446744073709551615`,这将强制进行排序。但是,这可能会导致性能问题,并且对于真正巨大的表格无效。 - pnomolos这不是最健壮的解决方案 - 但如果您只想在具有少量不同值的字段上创建分区排名,则使用尽可能多的变量使用一些 case when 逻辑可能不会很难处理。
像这样的东西过去对我有用:
SELECT t.*,
CASE WHEN <partition_field> = @rownum1 := @rownum1 + 1
WHEN <partition_field> = @rownum2 := @rownum2 + 1
...
END AS rank
FROM YOUR_TABLE t,
(SELECT @rownum1 := 0) r1, (SELECT @rownum2 := 0) r2
ORDER BY <rank_order_by_field>
;
希望这有意义/有所帮助!
在2023年仍然支持MySQL 5.7.38,并且需要ROW_NUMBER(),最后我做了类似这样的事情:
drop temporary table t1
create temporary table t1 (
USER_ID VARCHAR(50),
PRIORITY INT
)
insert into t1 (USER_ID, PRIORITY )
values
('qqq',300),
('qqq',572),
('qqq',574),
('qqq',630),
('qqq',640),
('qqq',650),
('yyy',300),
('yyy',574),
('yyy',574),
('yyy',630),
('yyy',640),
('yyy',650)
SELECT *,
@row_number := IF(@prev_userid = USER_ID, @row_number + 1, 1) AS ROWNUM,
@prev_userid := USER_ID
FROM t1
CROSS JOIN (SELECT @row_number := 0, @prev_userid := '') AS vars
ORDER BY USER_ID, PRIORITY
结果:
|USER_ID|PRIORITY|@row_number := 0|@prev_userid := ''|ROWNUM|@prev_userid := USER_ID|
|-------|--------|----------------|------------------|------|-----------------------|
|qqq |300 |0 | |1 |qqq |
|qqq |572 |0 | |2 |qqq |
|qqq |574 |0 | |3 |qqq |
|qqq |630 |0 | |4 |qqq |
|qqq |640 |0 | |5 |qqq |
|qqq |650 |0 | |6 |qqq |
|yyy |300 |0 | |1 |yyy |
|yyy |574 |0 | |2 |yyy |
|yyy |574 |0 | |3 |yyy |
|yyy |630 |0 | |4 |yyy |
|yyy |640 |0 | |5 |yyy |
|yyy |650 |0 | |6 |yyy |
这对我来说非常完美,可以在有多个列的情况下创建行号。 在这种情况下是两列。
SELECT @row_num := IF(@prev_value= concat(`Fk_Business_Unit_Code`,`NetIQ_Job_Code`), @row_num+1, 1) AS RowNumber,
`Fk_Business_Unit_Code`,
`NetIQ_Job_Code`,
`Supervisor_Name`,
@prev_value := concat(`Fk_Business_Unit_Code`,`NetIQ_Job_Code`)
FROM (SELECT DISTINCT `Fk_Business_Unit_Code`,`NetIQ_Job_Code`,`Supervisor_Name`
FROM Employee
ORDER BY `Fk_Business_Unit_Code`, `NetIQ_Job_Code`, `Supervisor_Name` DESC) z,
(SELECT @row_num := 1) x,
(SELECT @prev_value := '') y
ORDER BY `Fk_Business_Unit_Code`, `NetIQ_Job_Code`,`Supervisor_Name` DESC
自MySQL 8版本起,支持ROW_NUMBER()函数,因此您可以像在SQL Server中一样使用以下查询
SELECT
col1, col2,
ROW_NUMBER() OVER (PARTITION BY col1, col2 ORDER BY col3 DESC) AS intRow
FROM Table1
我也在Maria DB 10.4.21中测试过它。它在那里也可以工作。
对于基于另一列的分区,一种方法是由@abcdn描述的。然而,它的性能较低。我建议使用这段代码,它不需要将表与自身连接:
考虑相同的表格。
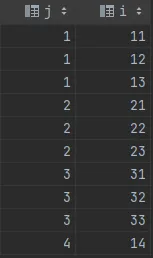
您可以像这样获得分区:
set @row_num := 0;
set @j:= 0;
select IF(j= @j, @row_num := @row_num + 1, @row_num := 1) as row_num,
i, @j:= j as j
from tbl fh
order by j, i;
结果会像这样:
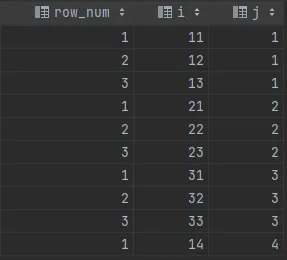
优点是我们不需要将表与自身连接