我正在使用Ruby编写一个CSV库(我知道,标准库已经很好了!)主要是为了好玩。目前它的速度大约比标准库慢4倍,我发现这很奇怪,因为我查看了stdlib中的csv.rb,它使用正则表达式来分割行,我认为这不会很快。在我的库中,我使用了一个DFA,所以我确定它将在O(n)时间内运行 - 我几乎没有回溯,只有一种情况我需要回溯一次,以适应反常的情况(转义字符==引号字符),而且这种情况只发生了大约1%的时间。
显然,我对我的代码进行了性能分析,这里是总运行时间占89%的部分。这是每个输入文件字符都要运行的循环:
显然,我对我的代码进行了性能分析,这里是总运行时间占89%的部分。这是每个输入文件字符都要运行的循环:
def consume token
if !@separator and [:BEFORE_FIELD, :FIELD, :BEFORE_SEPARATOR].include?(@state)
if @potential_separators.include? token
@separator = token
end
end
#puts "#{@state} - Token: #{token}"
@state = case @state
when :QUOTED_FIELD
if @escape.include? token
@last_escape_used = token
:MAYBE_ESCAPED_QUOTE
elsif token == @quote
:BEFORE_SEPARATOR
else
@field += token
:QUOTED_FIELD
end
when :FIELD
case token
when @newline
got_field
got_row
:BEFORE_FIELD
when @separator
got_field
:BEFORE_FIELD
else
@field += token
:FIELD
end
when :BEFORE_FIELD
case token
when @separator
got_field
:BEFORE_FIELD
when @quote
:QUOTED_FIELD
when @newline
got_field
got_row
:BEFORE_FIELD
else
@field += token
:FIELD
end
when :MAYBE_ESCAPED_QUOTE
if token == @quote
@field += @quote
:QUOTED_FIELD
elsif @last_escape_used == @quote
@state = :BEFORE_SEPARATOR
consume token
else
@field += @last_escape_used
@field += token
:QUOTED_FIELD
end
when :BEFORE_SEPARATOR
case token
when @separator
got_field
:BEFORE_FIELD
when @newline
got_field
got_row
:BEFORE_FIELD
else
raise "Error: Separator or newline expected! Got: #{token} at (#{@line}:#{@column})"
end
end
if token == @newline
@column = 1
@line += 1
else
@column += token.length
end
#puts "[#{@line}:#{@column} - #{token}] Switched to #{@state}"
#if token == @quote then exit end
@state
end
以下是性能分析输出:
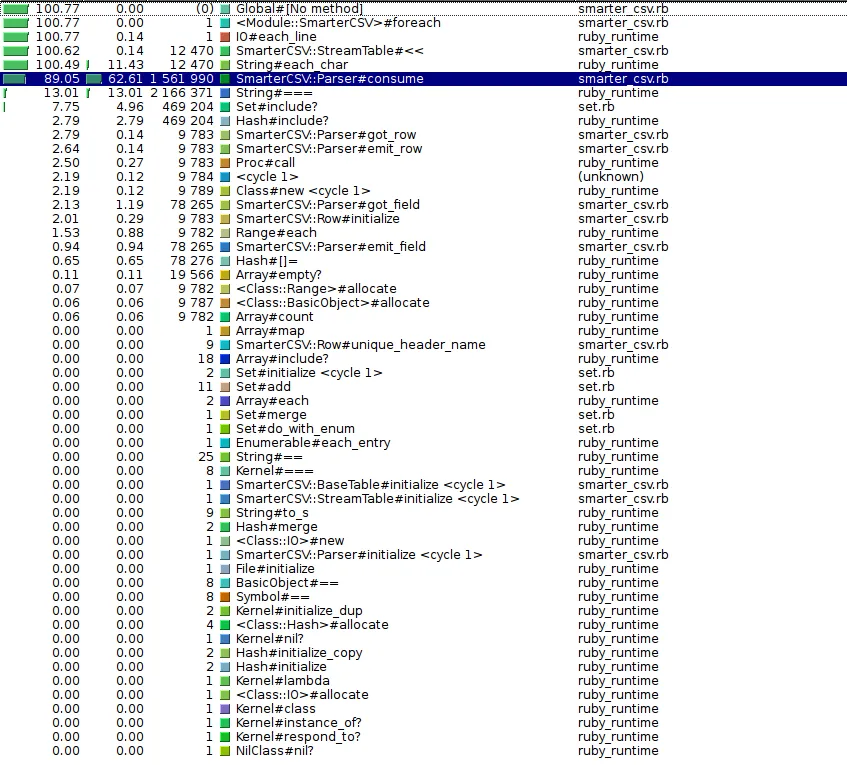
此外,真正缓慢的是consume函数本身,而不是它调用的少数函数,因为Self部分占总运行时间的62%!
#consume函数发生的详细信息如下:
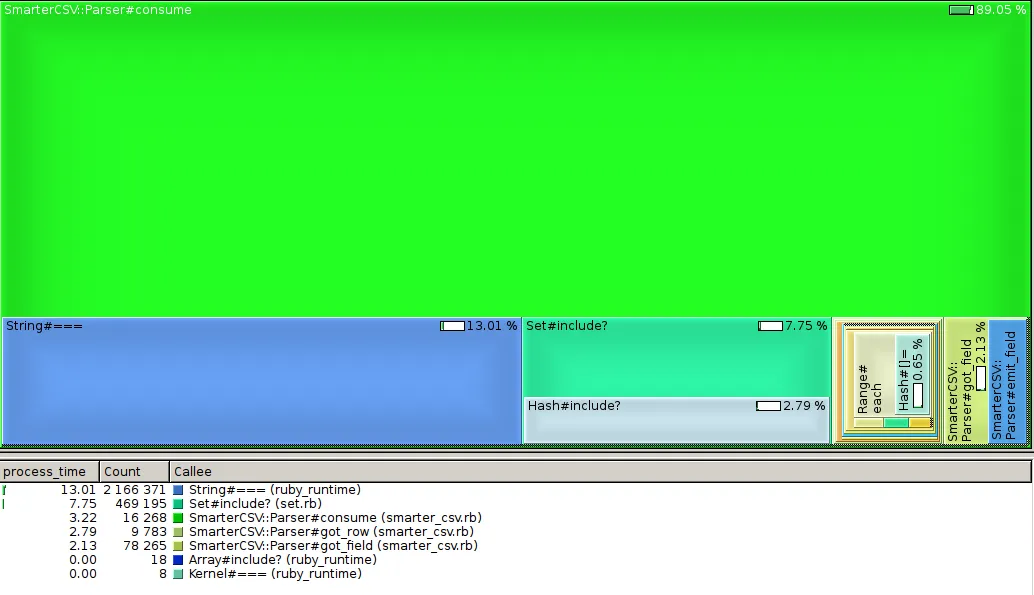
我认为case @state可能是罪魁祸首,所以我首先做的事情就是将最频繁的case放在前面(并进行了基准测试:没有变化)。代码看起来很干净,我真的不知道在哪里可以获得更多优化,但我觉得奇怪的是它比标准库慢这么多。
顺便说一下,我正在对一个2MB的CSV文件进行测试。我逐行读取它,并在内存中不存储任何内容。如果我用一个什么也不做的函数替换我的consume函数,那么我会得到与Ruby标准CSV相同的速度,但当然它什么也不做,所以我认为瓶颈不在I/O中。