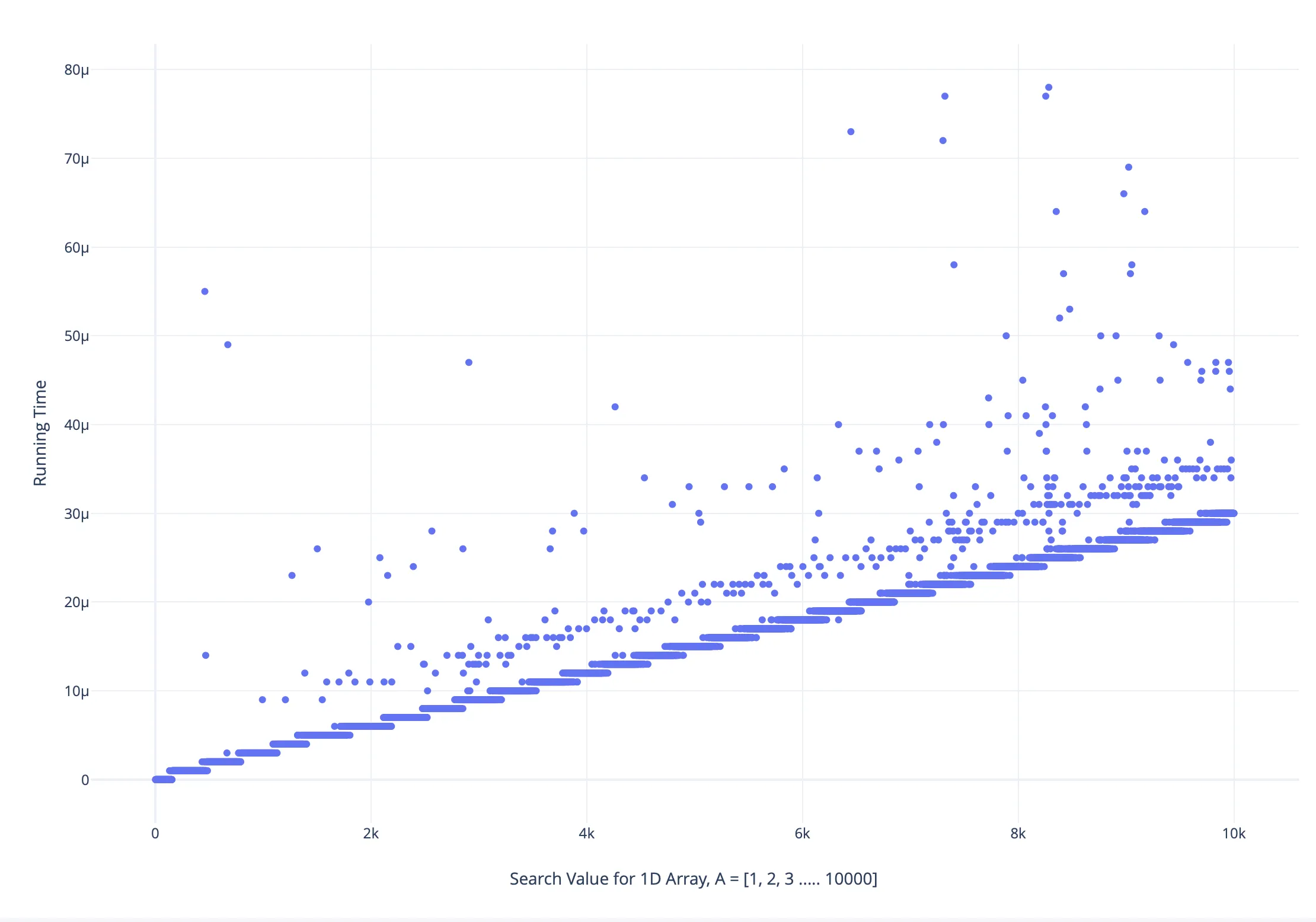
我在一个包含所有唯一元素的范围为[1, 10000]、按递增顺序排列的数组上执行了线性搜索,并将运行时间和搜索值绘制成了如下的图表:
仔细分析缩放后的图表,如下所示:
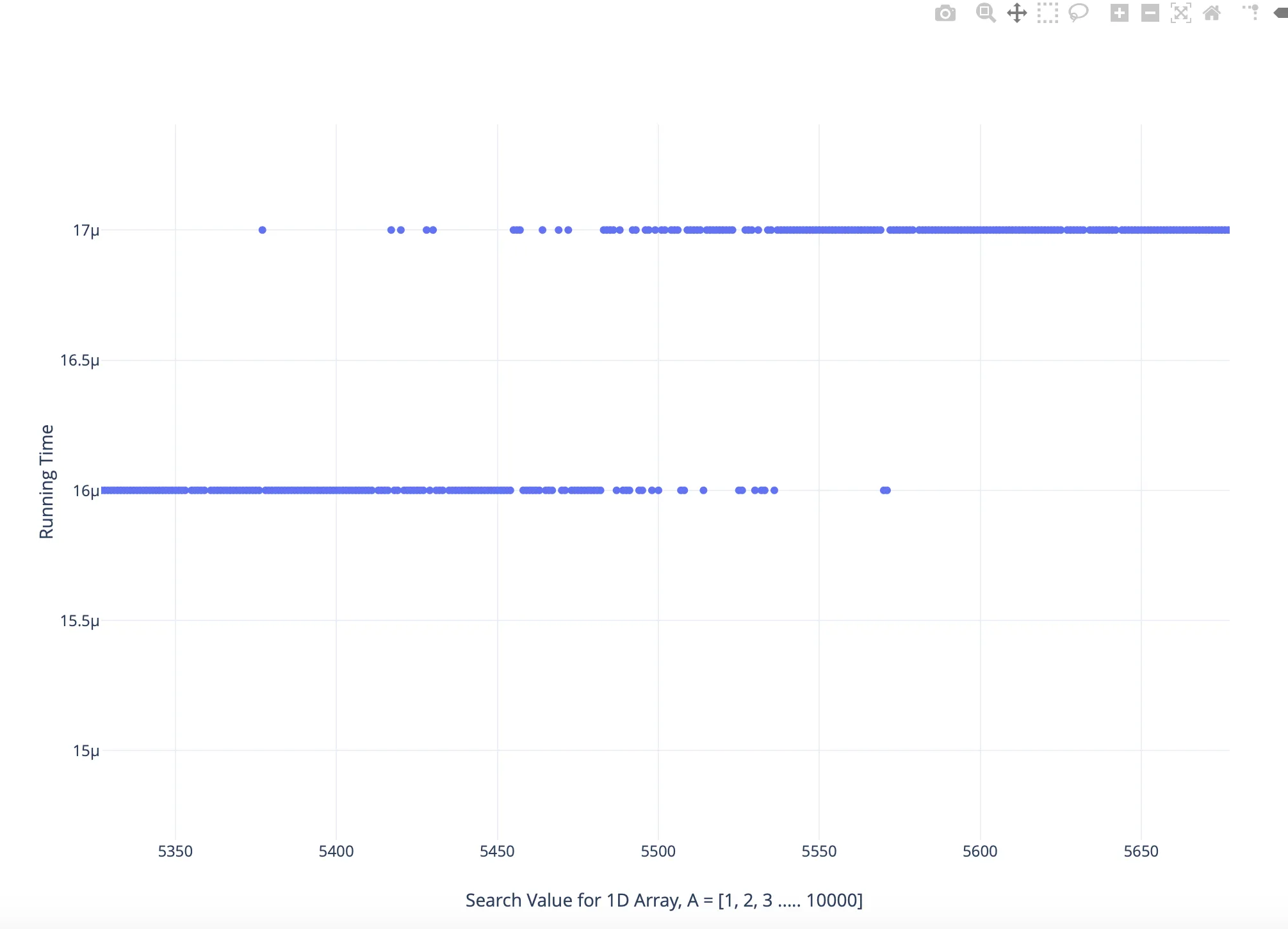
我发现对于某些较大的搜索值,运行时间比较小,而对于一些较小的搜索值,则相反。
我猜测这种现象与CPU使用主存和高速缓存处理数据有关,但没有一个明确的可量化的理由来解释这个问题。
任何提示将不胜感激。
PS: 代码是用C++编写的,在托管在Google Cloud上的虚拟机上运行。运行时间是使用C++ Chrono库测量的。
我在一个包含所有唯一元素的范围为[1, 10000]、按递增顺序排列的数组上执行了线性搜索,并将运行时间和搜索值绘制成了如下的图表:
仔细分析缩放后的图表,如下所示:
我发现对于某些较大的搜索值,运行时间比较小,而对于一些较小的搜索值,则相反。
我猜测这种现象与CPU使用主存和高速缓存处理数据有关,但没有一个明确的可量化的理由来解释这个问题。
任何提示将不胜感激。
PS: 代码是用C++编写的,在托管在Google Cloud上的虚拟机上运行。运行时间是使用C++ Chrono库测量的。