我有一个内核需要使用
生成的SASS代码如下所示:
atomicMin测试点的渲染。在理想情况下的内存布局中,测试设置有大量点。有两个缓冲区,一个用于256x uint32的簇的uint32。namespace Point
{
struct PackedBitfield
{
glm::uint32_t x : 6;
glm::uint32_t y : 6;
glm::uint32_t z : 6;
glm::uint32_t nx : 4;
glm::uint32_t ny : 4;
glm::uint32_t nz : 4;
glm::uint32_t unused : 2;
};
union __align__(4) Packed
{
glm::uint32_t bits;
PackedBitfield field;
};
struct ClusterPositionBitfield
{
glm::uint32_t x : 10;
glm::uint32_t y : 10;
glm::uint32_t z : 10;
glm::uint32_t w : 2;
};
union ClusterPosition
{
glm::uint32_t bits;
ClusterPositionBitfield field;
};
}
//
// launch with blockSize=(256, 1, 1) and grid=(numberOfClusters, 1, 1)
//
extern "C" __global__ void pointsRenderKernel(mat4 u_mvp,
ivec2 u_resolution,
uint64_t* rasterBuffer,
Point::Packed* points,
Point::ClusterPosition* clusterPosition)
{
// extract and compute world position
const Point::ClusterPosition cPosition(clusterPosition[blockIdx.x]);
const Point::Packed point(points[blockIdx.x*256 + threadIdx.x]);
...use points and write to buffer...
}
生成的SASS代码如下所示:
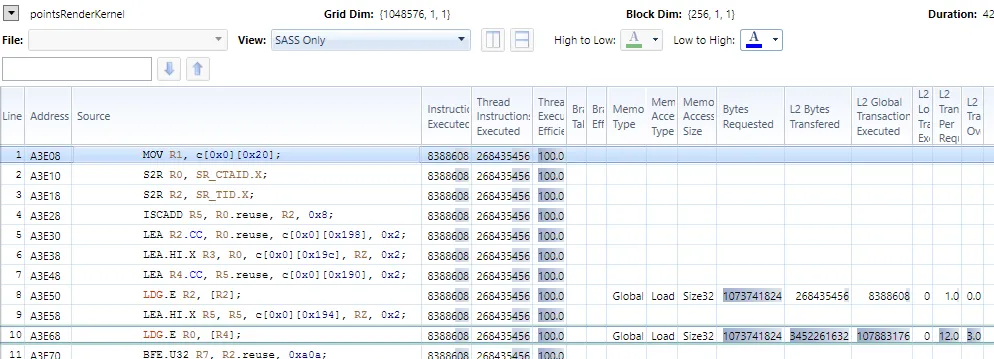
Point::Packed*缓冲区读取的L2传输开销为3.0。这是为什么呢?内存应该是完美对齐和连续的。此外,为什么会自动生成LDG(compute_50, sm_50)?我不需要这个缓存。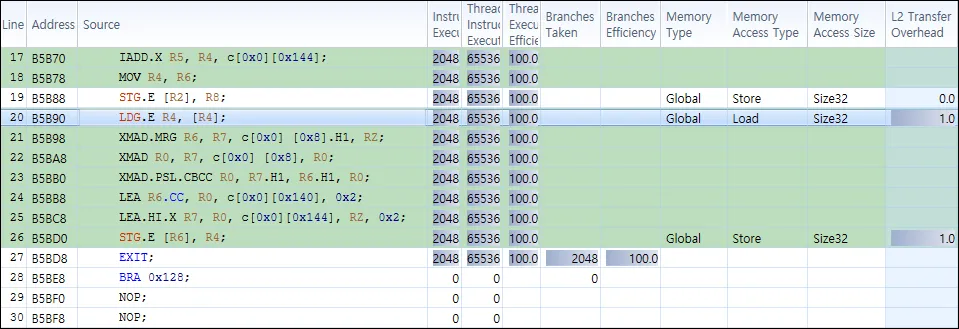
LDG使用通常最有效的加载路径,因此 CUDA 工具链更倾向于使用它。 - njuffa...use points and write to buffer...,以及汇编的前10.8行。您只展示了您认为相关的部分,显然这并没有帮助。请提供一个最小化完整可验证实例。 - Jakub Klinkovský