我希望使用HTML Agility Pack来确定主文章部分,然后从中提取主文章图片。我注意到大多数网站管理员都将其主要内容容器包含在H1标签中,但这并不是每次都遵循的规则,因此我不能基于此做出假设。
下面的2个截图来自这两个网站。
下面的2个截图来自这两个网站。
http://www.24matins.fr/the-walking-dead-saison-4-le-deces-de-ce-personnage-ne-sera-pas-anodin-40685
这些只是我想要抓取的网站的一些示例。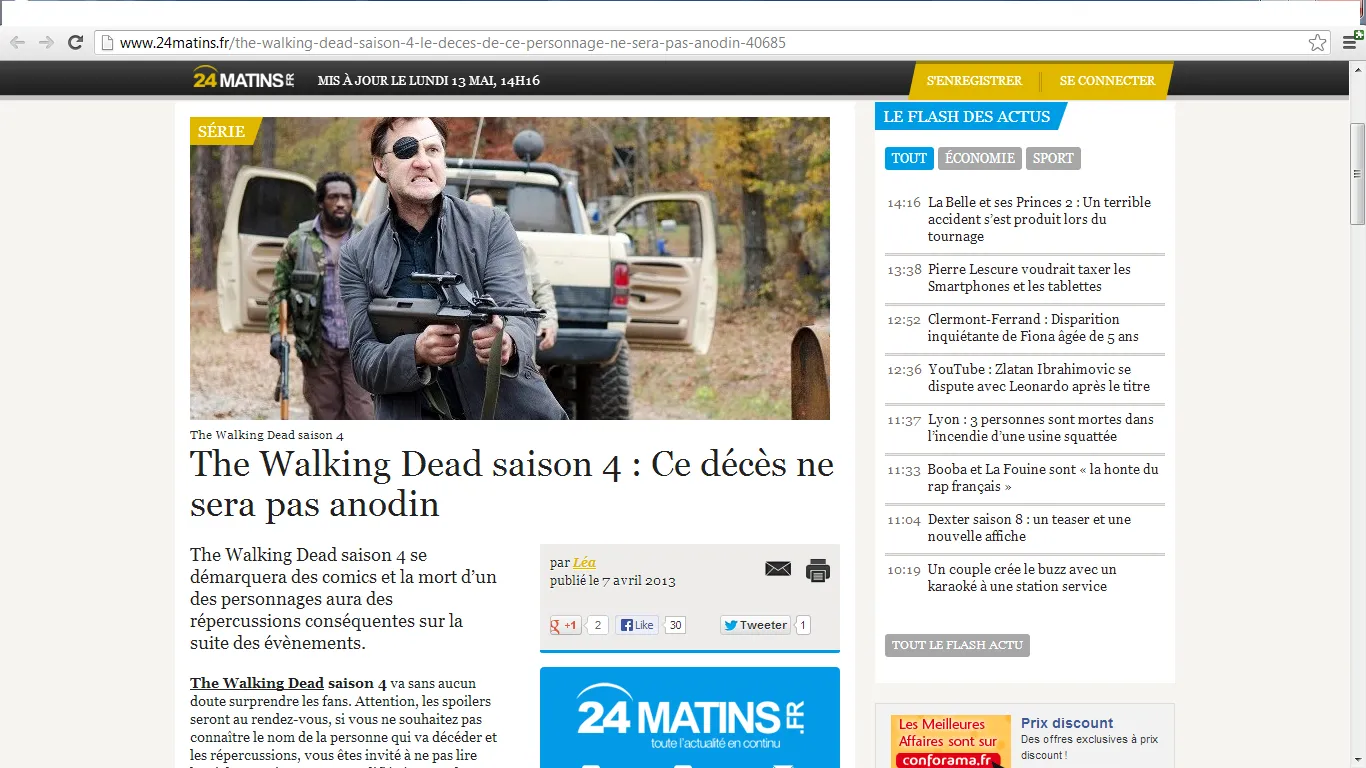
谢谢!