在Spark Standalone模式下,存在主节点和工作节点。
以下是几个问题:
- 2个工作实例是否意味着一个工作节点有2个工作进程?
- 每个工作实例是否持有特定应用程序的执行器(管理存储和任务),还是一个工作节点拥有一个执行器?
- 是否有流程图解释Spark如何在运行时工作,例如单词计数?
在Spark Standalone模式下,存在主节点和工作节点。
以下是几个问题:
在Spark Standalone模式下,有主节点和工作节点。
如果我们将独立模式下主节点和工作节点(每个工作节点如果CPU和内存可用可以有多个执行器)表示在一个地方。
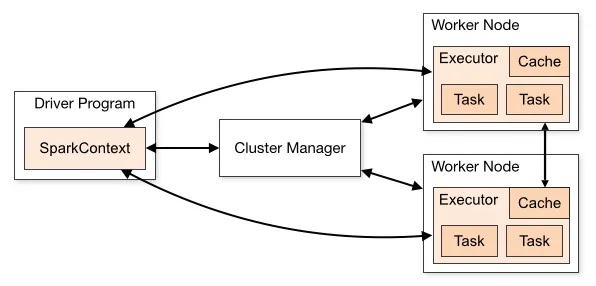
如果您想知道Spark如何与YARN一起使用,请查看此帖子Spark on YARN
1.两个工作实例是指一个工作节点具有两个工作进程吗?
通常情况下,我们将工作实例称为从节点,因为它是执行Spark任务/作业的进程。对于一个节点(物理或虚拟机)和一个worker的建议映射如下:
1 Node = 1 Worker process
2.每个工作实例是否都持有特定应用程序的执行器(管理存储、任务),还是一个工作节点只持有一个执行器?
是的,如果具备足够的CPU、内存和存储空间,一个工作节点可以持有多个执行器(进程)。
请参考给定图像中的工作节点。
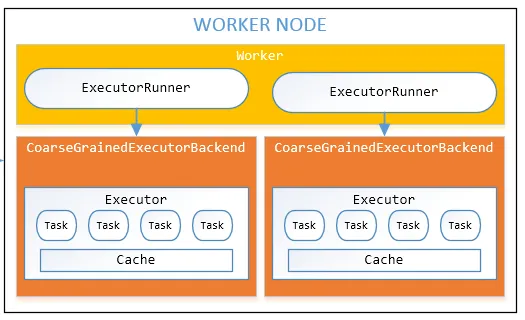
顺便说一句,在某个时间点上,一个工作节点中的执行器数量完全取决于集群上的工作负载以及节点运行多少执行器的能力。
3. 是否有一张流程图解释Spark运行时?
如果我们从Spark角度来看一个程序在任何资源管理器上的执行,它会join两个rdd并进行一些reduce操作,然后进行filter。
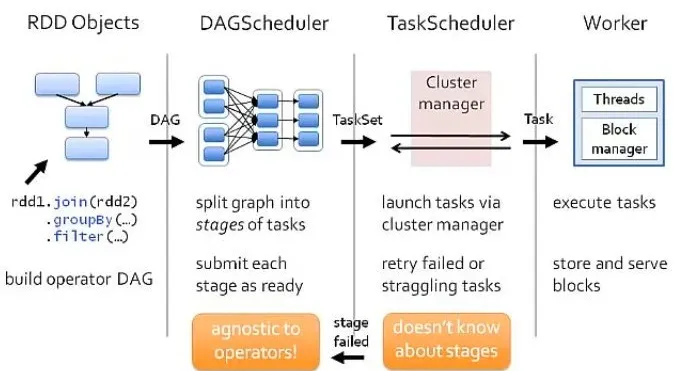
希望对你有所帮助。
我建议先阅读Spark集群文档,更重要的是阅读这篇Cloudera博客文章,解释了这些模式。
您的第一个问题取决于您所指的“实例”的含义。一个节点是一台机器,运行多个worker没有必要,因此两个worker节点通常意味着两台机器,每台机器上有一个Spark worker。
Worker保存许多执行器,用于许多应用程序。一个应用程序在多个worker上具有执行器。
您的第三个问题不清楚。