我正在使用concurrent.futures.ProcessPoolExecutor来在一个数字范围内查找一个数字的出现次数。我的目的是探究并发性能带来的加速效果。为了测试性能,我有一个控制组——一个串行代码来执行这个任务(如下所示)。我编写了两个并发代码,一个是使用concurrent.futures.ProcessPoolExecutor.submit(),另一个是使用concurrent.futures.ProcessPoolExecutor.map()来执行同样的任务。它们如下所示。有关起草前者和后者的建议可以在这里和这里看到。
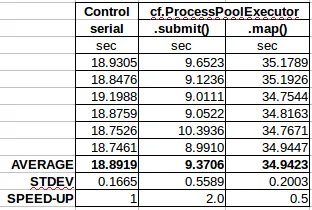
所有三个代码的任务都是在数字范围0到1E8中查找数字5出现的次数。同时给.submit()和.map()分配了6个工作进程,并且.map()的块大小为10,000。在并发代码中离散工作量的方式是相同的。但是,用于在两个代码中查找出现次数的函数是不同的。这是因为调用由.submit()和.map()调用的函数时传递参数的方式不同。
所有3个代码报告的出现次数相同,即56,953,279次。但是完成任务所需的时间非常不同。相对于控制组,.submit()的执行速度快两倍,而.map()的执行速度则慢两倍。
问题:
- 我想知道
.map()的低效表现是我的代码的产物还是本质上就很慢?如果是前者,我该如何改进它?我只是惊讶它的执行速度比控制组慢这么多,因为没有多大的动力使用它。 - 我想知道是否有办法使
.submit()代码执行得更快。我有一个条件,即函数_concurrent_submit()必须返回带有数字/包含数字5的出现次数的可迭代对象。
基准测试结果
concurrent.futures.ProcessPoolExecutor.submit()
#!/usr/bin/python3.5
# -*- coding: utf-8 -*-
import concurrent.futures as cf
from time import time
from traceback import print_exc
def _findmatch(nmin, nmax, number):
'''Function to find the occurrence of number in range nmin to nmax and return
the found occurrences in a list.'''
print('\n def _findmatch', nmin, nmax, number)
start = time()
match=[]
for n in range(nmin, nmax):
if number in str(n):
match.append(n)
end = time() - start
print("found {0} in {1:.4f}sec".format(len(match),end))
return match
def _concurrent_submit(nmax, number, workers):
'''Function that utilises concurrent.futures.ProcessPoolExecutor.submit to
find the occurences of a given number in a number range in a parallelised
manner.'''
# 1. Local variables
start = time()
chunk = nmax // workers
futures = []
found =[]
#2. Parallelization
with cf.ProcessPoolExecutor(max_workers=workers) as executor:
# 2.1. Discretise workload and submit to worker pool
for i in range(workers):
cstart = chunk * i
cstop = chunk * (i + 1) if i != workers - 1 else nmax
futures.append(executor.submit(_findmatch, cstart, cstop, number))
# 2.2. Instruct workers to process results as they come, when all are
# completed or .....
cf.as_completed(futures) # faster than cf.wait()
# 2.3. Consolidate result as a list and return this list.
for future in futures:
for f in future.result():
try:
found.append(f)
except:
print_exc()
foundsize = len(found)
end = time() - start
print('within statement of def _concurrent_submit():')
print("found {0} in {1:.4f}sec".format(foundsize, end))
return found
if __name__ == '__main__':
nmax = int(1E8) # Number range maximum.
number = str(5) # Number to be found in number range.
workers = 6 # Pool of workers
start = time()
a = _concurrent_submit(nmax, number, workers)
end = time() - start
print('\n main')
print('workers = ', workers)
print("found {0} in {1:.4f}sec".format(len(a),end))
concurrent.futures.ProcessPoolExecutor.map()
#!/usr/bin/python3.5
# -*- coding: utf-8 -*-
import concurrent.futures as cf
import itertools
from time import time
from traceback import print_exc
def _findmatch(listnumber, number):
'''Function to find the occurrence of number in another number and return
a string value.'''
#print('def _findmatch(listnumber, number):')
#print('listnumber = {0} and ref = {1}'.format(listnumber, number))
if number in str(listnumber):
x = listnumber
#print('x = {0}'.format(x))
return x
def _concurrent_map(nmax, number, workers):
'''Function that utilises concurrent.futures.ProcessPoolExecutor.map to
find the occurrences of a given number in a number range in a parallelised
manner.'''
# 1. Local variables
start = time()
chunk = nmax // workers
futures = []
found =[]
#2. Parallelization
with cf.ProcessPoolExecutor(max_workers=workers) as executor:
# 2.1. Discretise workload and submit to worker pool
for i in range(workers):
cstart = chunk * i
cstop = chunk * (i + 1) if i != workers - 1 else nmax
numberlist = range(cstart, cstop)
futures.append(executor.map(_findmatch, numberlist,
itertools.repeat(number),
chunksize=10000))
# 2.3. Consolidate result as a list and return this list.
for future in futures:
for f in future:
if f:
try:
found.append(f)
except:
print_exc()
foundsize = len(found)
end = time() - start
print('within statement of def _concurrent(nmax, number):')
print("found {0} in {1:.4f}sec".format(foundsize, end))
return found
if __name__ == '__main__':
nmax = int(1E8) # Number range maximum.
number = str(5) # Number to be found in number range.
workers = 6 # Pool of workers
start = time()
a = _concurrent_map(nmax, number, workers)
end = time() - start
print('\n main')
print('workers = ', workers)
print("found {0} in {1:.4f}sec".format(len(a),end))
序列代码:
#!/usr/bin/python3.5
# -*- coding: utf-8 -*-
from time import time
def _serial(nmax, number):
start = time()
match=[]
nlist = range(nmax)
for n in nlist:
if number in str(n):match.append(n)
end=time()-start
print("found {0} in {1:.4f}sec".format(len(match),end))
return match
if __name__ == '__main__':
nmax = int(1E8) # Number range maximum.
number = str(5) # Number to be found in number range.
start = time()
a = _serial(nmax, number)
end = time() - start
print('\n main')
print("found {0} in {1:.4f}sec".format(len(a),end))
2017年2月13日更新:
除了@niemmi的答案外,我还经过一些个人研究提供了一个答案,以展示:
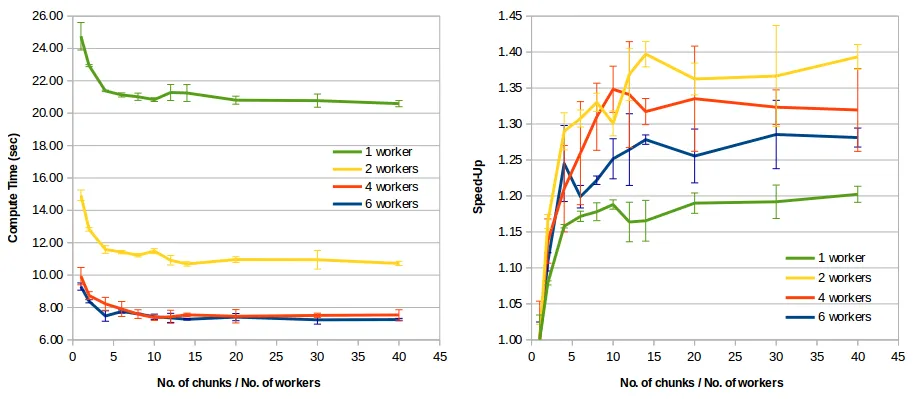
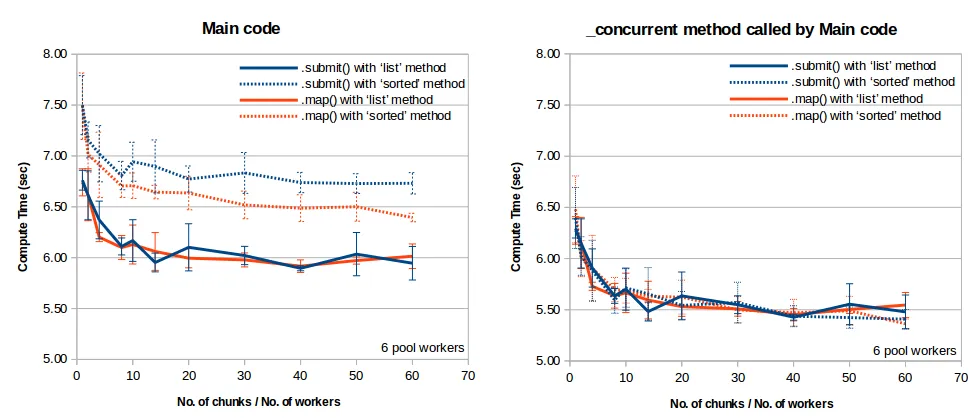
- 如何进一步加速@niemmi的
.map()和.submit()解决方案 ProcessPoolExecutor.map()何时比ProcessPoolExecutor.submit()更能带来速度提升。
.map()解决方案。哇...你重新编写cstart和cstop以将其应用于_findmatch()和.map()的方式真是巧妙。我从未想过可以这样做。这是我第一次使用.map()。这就是为什么.map()代码中的_findmatch与.submit()代码和控制代码中的_findmatch不同,导致了苹果与橙子的比较。;) 我试图在.map()中包含chunksize,但发现它会导致性能变慢。chunksize越大,.map代码执行得越慢。你能帮我理解为什么会这样吗? - Sun Bearchunksize=5,其中一个工作人员获得了6个部分中的5个,导致5/6的工作在一个核心上被处理。通常情况下,使用更大的chunksize是有意义的,但前提是它允许工作在工作者之间均匀分配。尝试使用原始的submit降低chunksize,您应该会看到它变慢了。 - niemmi