我发现一个有趣的现象:
我使用在i5-5257U Mac OS上的GCC 7.3.0编译代码,没有进行任何优化。这是10次运行的平均运行时间: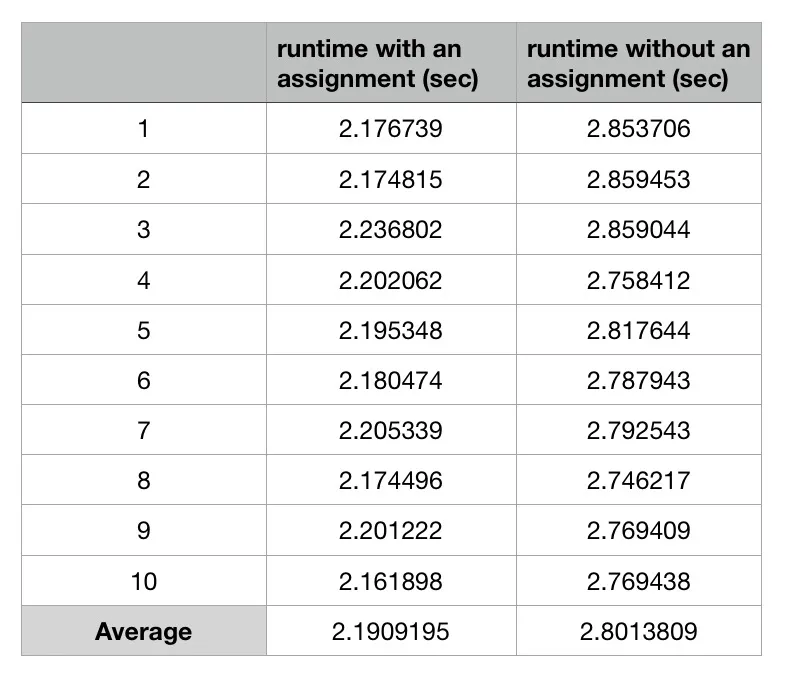 也有其他人在其他Intel平台上测试此案例并获得相同的结果。
我在这里张贴了由GCC生成的汇编代码:这里。两个汇编代码之间唯一的区别是在
也有其他人在其他Intel平台上测试此案例并获得相同的结果。
我在这里张贴了由GCC生成的汇编代码:这里。两个汇编代码之间唯一的区别是在
那么为什么这样的赋值会使程序运行更快呢?
Peter的回答非常有帮助。在AMD Phenom II X4 810和ARMv7处理器(BCM2835)上进行的测试显示了与一些Intel CPU相关的存储转发加速相反的结果。
BeeOnRope的评论和建议促使我重新编写问题。 :)
这个问题的核心是与处理器架构和汇编相关的有趣现象。因此,我认为它值得讨论。
#include<stdio.h>
#include<time.h>
int main() {
int p, q;
clock_t s,e;
s=clock();
for(int i = 1; i < 1000; i++){
for(int j = 1; j < 1000; j++){
for(int k = 1; k < 1000; k++){
p = i + j * k;
q = p; //Removing this line can increase running time.
}
}
}
e = clock();
double t = (double)(e - s) / CLOCKS_PER_SEC;
printf("%lf\n", t);
return 0;
}
我使用在i5-5257U Mac OS上的GCC 7.3.0编译代码,没有进行任何优化。这是10次运行的平均运行时间:
也有其他人在其他Intel平台上测试此案例并获得相同的结果。
我在这里张贴了由GCC生成的汇编代码:这里。两个汇编代码之间唯一的区别是在addl $1, -12(%rbp)之前,速度更快的那一个多了两个操作。movl -44(%rbp), %eax
movl %eax, -48(%rbp)
那么为什么这样的赋值会使程序运行更快呢?
Peter的回答非常有帮助。在AMD Phenom II X4 810和ARMv7处理器(BCM2835)上进行的测试显示了与一些Intel CPU相关的存储转发加速相反的结果。
BeeOnRope的评论和建议促使我重新编写问题。 :)
这个问题的核心是与处理器架构和汇编相关的有趣现象。因此,我认为它值得讨论。
k的循环依赖。如果你使用的是Skylake处理器,那么当相关的配对操作之间有更多操作(包括其他存储/加载操作)时,存储/重载延迟实际上可以更低(更好)。 - Peter Cordes