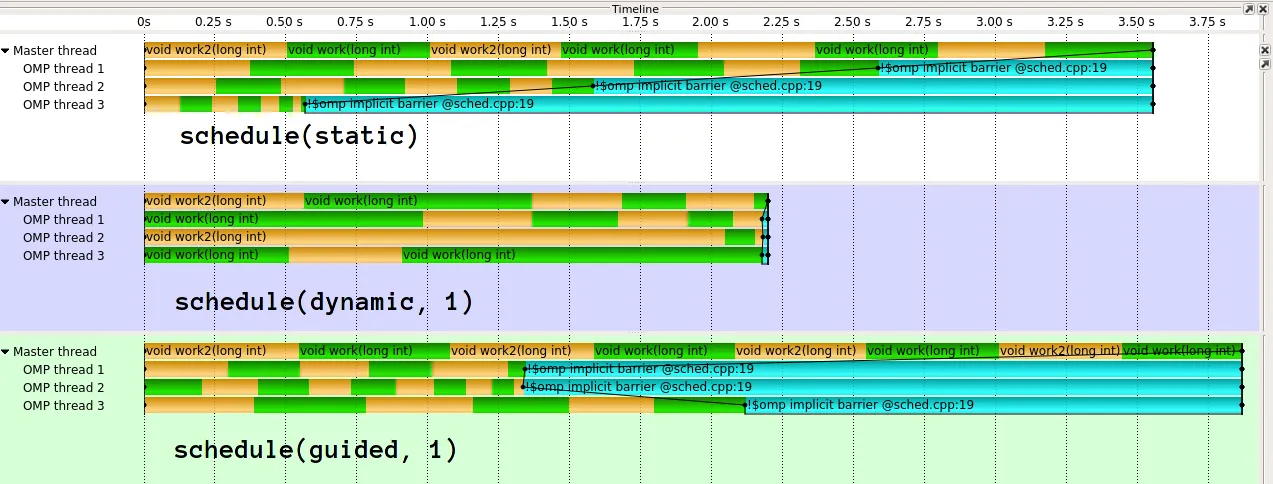
我正在研究OpenMP的调度,特别是不同类型。我了解每种类型的一般行为,但更清晰的解释有助于选择何时在dynamic和guided调度之间进行选择。
Intel的文档描述了dynamic调度:
使用内部工作队列,将循环迭代的块大小分配给每个线程。当一个线程完成时,它从工作队列的顶部检索下一个循环迭代的块。默认情况下,块大小为1。使用此调度类型时要小心,因为涉及额外的开销。
它还描述了guided调度:
类似于动态调度,但块大小从大到小递减,以更好地处理迭代之间的负载不平衡。可选的块参数指定要使用的最小块大小。默认情况下,块大小约为loop_count/number_of_threads。
由于guided调度在运行时动态减少块大小,那么我为什么要使用dynamic调度呢?
我研究了这个问题,并在Dartmouth的这个表格中找到了答案:
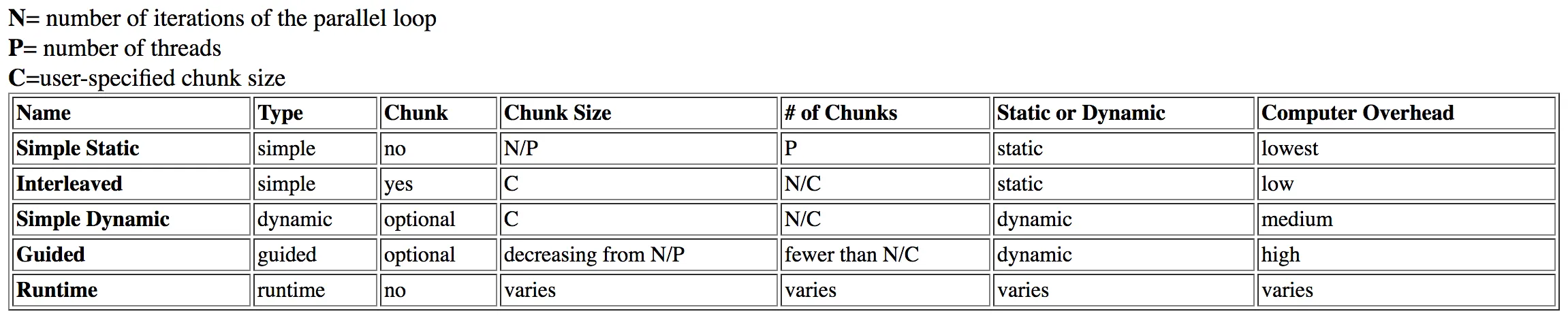
guided被列为具有high开销,而dynamic具有中等开销。
这原本是有道理的,但经过进一步调查,我在Intel文章中阅读到了相关内容。从前面的表格可以看出,我猜测 guided 调度会需要更长的时间,因为在运行时需要对块大小进行分析和调整(即使使用正确)。然而,在这篇Intel文章中指出:
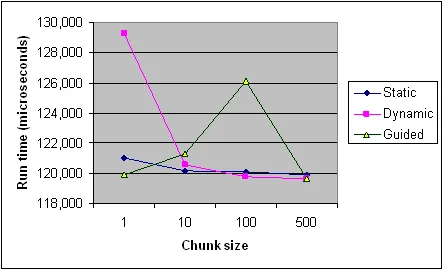
对于小的块大小,引导式调度表现最佳;这样可以获得最大的灵活性。不清楚为什么它们的表现在较大的块大小下会变差,但当限制到大块大小时,它们可能需要太长时间。
为什么块大小会影响 guided 比 dynamic 更耗时呢?如果将块大小锁定得太高,缺乏“灵活性”会导致性能损失,这是有道理的。但我不会将其描述为“开销”,而且锁定问题会否定之前的猜想。
最后,在文章中指出:
动态调度提供最大的灵活性,但当调度错误时会带来最大的性能损失。
对于 dynamic 调度比 static 更优秀,这是有道理的,但为什么它比 guided 更优秀呢?我是否只是在质疑开销呢?
这个与某种程度相关的SO帖子解释了与调度类型相关的NUMA。虽然这些调度类型的“先到先服务”行为会导致所需的组织被丢失,但这与本问题无关。
dynamic 调度可能是聚合的,从而提高性能,但相同的假设也适用于 guided。
以下是来自Intel文章的各种调度类型在不同块大小下的时间记录,供参考。 这只是一个程序的记录,并且一些规则在不同的程序和机器上适用不同(特别是在调度方面),但它应该提供一般趋势。
编辑(我的问题的核心):
guided调度的运行时间受什么影响?具体举例说明?为什么在某些情况下比dynamic慢?- 何时会优先选择
guided或dynamic,反之亦然? - 一旦解释清楚,上述来源是否支持您的解释?它们是否存在矛盾之处?