有没有办法在 Kotlin 中将字符串 'Dziękuję' 转换为 'Dziekuje' 或将 'šećer' 转换为 'secer'。我尝试使用 java.text.Normalizer,但它似乎不能按照预期的方式工作。
5个回答
55
规范化器只完成了一半的工作。以下是您可以使用它的方法:
private val REGEX_UNACCENT = "\\p{InCombiningDiacriticalMarks}+".toRegex()
fun CharSequence.unaccent(): String {
val temp = Normalizer.normalize(this, Normalizer.Form.NFD)
return REGEX_UNACCENT.replace(temp, "")
}
assert("áéíóů".unaccent() == "aeiou")
以下是工作原理:
我们调用normalize()方法。如果我们传入à,该方法将返回a + `。然后使用正则表达式清理字符串,仅保留有效的US-ASCII字符。
来源:http://www.rgagnon.com/javadetails/java-0456.html
请注意,Normalizer是一个Java类;这不是纯Kotlin,它只能在JVM上运行。
- Eugen Pechanec
1
谢谢。这正是我在寻找的。 - Rebronja
18
TL;DR:
- 使用
Normalizer将Unicode文本进行规范分解。 - 移除非间距组合字符(
\p{Mn})。
fun String.removeNonSpacingMarks() =
Normalizer.normalize(this, Normalizer.Form.NFD)
.replace("\\p{Mn}+".toRegex(), "")
长答案:
使用规范化器(Normalizer),您可以将原始文本转换为等效的组合或分解形式。
- NFD:规范分解。
- NFC:规范分解,然后进行规范组合。
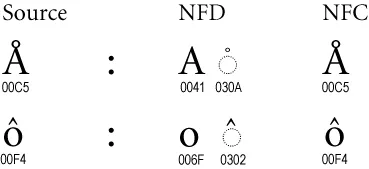 。(有关规范化的更多信息,请参见Unicode®标准附录#15)
。(有关规范化的更多信息,请参见Unicode®标准附录#15)
在我们的情况下,我们对NFD规范化形式感兴趣,因为它允许我们将所有组合字符与基字符分开。
分解文本后,我们必须运行一个正则表达式,以删除所有由分解导致的新字符,这些字符对应于组合字符。
组合字符是特殊字符,旨在相对于相关的基字符定位。 Unicode标准区分两种类型的组合字符:间距和非间距。
我们只对非间距组合字符感兴趣。变音符号是此组与拉丁文、希腊文和西里尔文及其相关语言一起使用的主要类别(但不是唯一的类别)。
为了使用正则表达式删除非间距字符,我们必须使用\p{Mn}。此组包括所有1826个非间距字符。
其他答案使用\p{InCombiningDiacriticalMarks},此块仅包含组合变音符号。它是\p{Mn}的一个子集,仅包括112个字符。
- David Miguel
1
1这是最完整的答案。 - walv
4
这是一个可以使用和进一步扩展的扩展功能:
使用方式如下:
fun String.normalize(): String {
val original = arrayOf("ę", "š")
val normalized = arrayOf("e", "s")
return this.map { it ->
val index = original.indexOf(it.toString())
if (index >= 0) normalized[index] else it
}.joinToString("")
}
使用方式如下:
val originalText = "aębšc"
val normalizedText = originalText.normalize()
println(normalizedText)
将打印
aebsc
扩展数组original和normalized,添加所需数量的元素。
- user8959091
2
谢谢你的回答。这是一个很好的解决方法,可以避开整个规范化的问题。 - Rebronja
我最终采用了这种解决方案,因为 Normalizer 对 Ø 字符没有影响,而我想将其转换为 O。 - Ronan
0
你只需要使用
Normalizer类的这种方法: fun String.removeAccents() =
Normalizer.normalize(this, Normalizer.Form.NFD)
例子:
var words ="Dziękuję šećer aębšc áéíóů canción ñiña Ioana"
println("${words.unaccent()}")
输出:
Dziekuje secer aebsc aeiou cancion nina Ioana
- Jorgesys
-4
如果有人在Kotlin中遇到困难,这段代码非常好用。为了避免不一致,我还使用了 .toUpperCase 和 Trim()。然后我将此函数强制转换。
fun stripAccents(s: String):String{
if (s == null) {
return "";
}
val chars: CharArray = s.toCharArray()
var sb = StringBuilder(s)
var cont: Int = 0
while (chars.size > cont) {
var c: kotlin.Char
c = chars[cont]
var c2:String = c.toString()
//these are my needs, in case you need to convert other accents just Add new entries aqui
c2 = c2.replace("Ã", "A")
c2 = c2.replace("Õ", "O")
c2 = c2.replace("Ç", "C")
c2 = c2.replace("Á", "A")
c2 = c2.replace("Ó", "O")
c2 = c2.replace("Ê", "E")
c2 = c2.replace("É", "E")
c2 = c2.replace("Ú", "U")
c = c2.single()
sb.setCharAt(cont, c)
cont++
}
return sb.toString()
}
要使用这些有趣的转换,请像这样编写代码:
var str: String
str = editText.text.toString() //get the text from EditText
str = str.toUpperCase().trim()
str = stripAccents(str) //call the function
- Thiago Silva
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接