我有以下表格 -
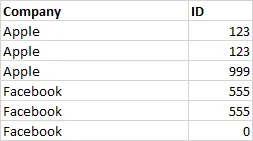
我的目标是按ID分组,返回具有最高“count”的公司/ID行。
因此,期望的输出应该像这样:

我的当前代码返回所有ID分区的计数,我只希望它返回具有最高计数的那个。
当前代码 -
select distinct Company, Id, count(*) over (partition by ID)
from table1
where company in ("Facebook","Apple")
我的输出:

我有以下表格 -
我的目标是按ID分组,返回具有最高“count”的公司/ID行。
因此,期望的输出应该像这样:
我的当前代码返回所有ID分区的计数,我只希望它返回具有最高计数的那个。
当前代码 -
select distinct Company, Id, count(*) over (partition by ID)
from table1
where company in ("Facebook","Apple")
我的输出:
您的基本查询有误。您按ID进行分区,而不考虑公司,但在您的请求注释中,您澄清希望按ID和公司计数。这将需要:
select distinct company, id, count(*) over (partition by company, id)
from table1
where company in ('Facebook','Apple');
但是这个查询归结为一个简单的聚合操作,并不需要使用窗口函数。它只是对每一行进行计数,然后用DISTINCT去除重复项。由于DISTINCT是一个昂贵的操作,所以为什么不直接在第一次聚合时就将行聚合起来呢?
select company, id, count(*)
from table1
where company in ('Facebook','Apple')
group by company, id;
现在,您只想保留每个公司数量最高的行,这就是窗口函数发挥作用的地方:
select company, id, total
from
(
select
company,
id,
count(*) as total,
max(count(*)) over (partition by company) as max_total
from table1
where company in ('Facebook','Apple')
group by company, id
) aggregated
where total = max_total;
ROW_NUMBER:WITH cte AS (
SELECT Company, ID, COUNT(*) AS Count,
ROW_NUMBER() OVER (PARTITION BY Company ORDER BY COUNT(*) DESC) rn
FROM table1
GROUP BY Company, ID
)
SELECT Company, ID, Count
FROM cte
WHERE rn = 1;
SELECT company, id, COUNT(*)
FROM table1
GROUP BY EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO
HAVING COUNT(*) > 1;
where company in ('Facebook','Apple')。 - Thorsten Kettner