递归算法
对于计算整数 n 分割成 m 个部分的所有可能方案,递归算法是一个显而易见的选择。对于情况 n, m,该算法通过每个选项 k = 1, 2, 3... 来运行第一部分,对于这些选项中的每一个,它将使用情况 n - k, m - 1 进行递归。例如:
n = 16, m = 4
first part = 1 => recurse with n = 15, m = 3
first part = 2 => recurse with n = 14, m = 3
first part = 3 => recurse with n = 13, m = 3
etc...
递归多次后,当 m = 2 时,解为:
first part = 1 => second part = n - 1
first part = 2 => second part = n - 2
first part = 3 => second part = n - 3
etc...
因此,当 m = 2 时的解数等于第一部分选项的数量。
递增序列
要仅计算唯一解并丢弃重复,使得 2+4 和 4+2 不会同时被计数,只考虑部分形成非降序列的解;例如:
n = 9, m = 3
partitions: 1+1+7 1+2+6 1+3+5 1+4+4
2+2+5 2+3+4
3+3+3
在一个上升序列中,第一部分的值永远不能大于n / m。
具有最小值1的递归
为了保持上升序列,每次递归都必须将前一部分的值作为其部分的最小值;例如:
n = 9, m = 3
k = 1 => recurse with n = 8, m = 2, k >= 1 => 1+7 2+6 3+5 4+4
k = 2 => recurse with n = 7, m = 2, k >= 2 => 2+5 3+4
k = 3 => recurse with n = 6, m = 2, k >= 3 => 3+3
为避免需要在每次递归中传递最小值,每个递归n - k, m - 1, k都被替换成n - k - (m - 1) * (k - 1), m - 1, 1,其具有相同数量的解决方案。例如:
n = 9, m = 3
k = 1 => recurse with n = 8, m = 2, k >= 1 => 1+7 2+6 3+5 4+4
k = 2 => recurse with n = 5, m = 2, k >= 1 => 1+4 2+3
k = 3 => recurse with n = 2, m = 2, k >= 1 => 1+1
这不仅简化了代码,还有助于提高使用记忆化技术时的效率,因为像 2+2+3、3+3+4 和 5+5+6 这样的序列都被替换为它们的标准形式 1+1+2,并且更小的一组中间计算会经常重复。
记忆化技术
使用递归算法进行分区时,许多计算会被重复多次。随着n和m的增加,递归次数迅速变得巨大。例如,要解决用例150, 23(下图所示)时,需要计算用例4, 2 23,703,672次。
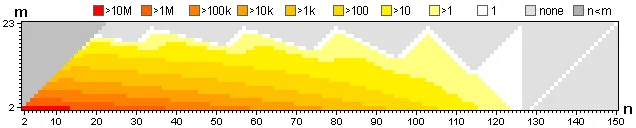
然而,唯一的计算数量永远不能超过n * m。因此,通过将每个计算的结果缓存在一个n*m大小的数组中,最多只需要做n * m次计算;在计算一次用例后,算法可以使用存储的值。这极大地提高了算法的效率。例如,如果没有记忆化技术,则需要422,910,232次递归才能解决用例150, 23;使用记忆化技术,只需要15,163次递归。
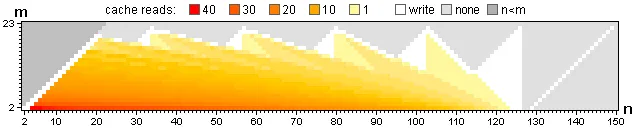
下图显示了此用例的缓存读取和写入。灰色单元格未使用,白色单元格已写入但从未读取。总共有2042次写入和12697次读取。
减少缓存大小
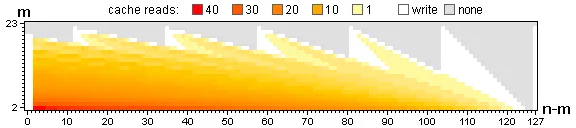
您会注意到顶部左侧和底部右侧的三角形从未使用过;而且m的值越接近n,未使用的区域就越大。为避免这种空间浪费,可以将两个三角形之间的平行四边形倾斜45°,通过在n-m,m中存储n,m的值来实现。因此,缓存大小从(n-1) * (m-1)减小到(n-m) * (m-1),而n,m <= 150的最坏情况不再是149 * 149 = 22201,而是75 * 74 = 5550,大小不到原来的25%。
示例1: 无记忆化代码
function partition(n, m) {
if (m < 2) return m;
if (n < m) return 0;
if (n <= m + 1) return 1;
var max = Math.floor(n / m);
if (m == 2) return max;
var count = 0;
for (; max--; n -= m) count += partition(n - 1, m - 1);
return count;
}
document.write(partition(6, 1) + "<br>");
document.write(partition(6, 2) + "<br>");
document.write(partition(9, 3) + "<br>");
document.write(partition(16, 4) + "<br>");
document.write(partition(150, 75) + "<br>");
代码示例2:使用记忆化的快速版本
这个版本缓存了中间结果,比基础算法要快得多。即使是 JavaScript 实现,在 n = 150 的最坏情况下也可以在不到一毫秒的时间内解决。
function partition(n, m) {
if (m < 2) return m;
if (n < m) return 0;
var memo = [];
for (var i = 0; i < n - 1; i++) memo[i] = [];
return p(n, m);
function p(n, m) {
if (n <= m + 1) return 1;
if (memo[n - 2][m - 2]) return memo[n - 2][m - 2];
var max = Math.floor(n / m);
if (m == 2) return max;
var count = 0;
for (; max--; n -= m) count += (memo[n - 3][m - 3] = p(n - 1, m - 1));
return count;
}
}
document.write(partition(150, 23) + "<br>");
(n = 1000时最坏情况为m = 81,解为4.01779428811641e+29,此结果也几乎瞬间返回。因为它超出了JavaScript的最大安全整数253-1,所以它当然不是一个精确的结果。)
这个示例代码3采用记忆化和较小缓存的偏斜缓存索引版本以降低内存需求。
function partition(n, m) {
if (m < 2) return m;
if (n < m) return 0;
var memo = [];
for (var i = 0; i <= n - m; i++) memo[i] = [];
return p(n, m);
function p(n, m) {
if (n <= m + 1) return 1;
if (memo[n - m][m - 2]) return memo[n - m][m - 2];
var max = Math.floor(n / m);
if (m == 2) return max;
var count = 0;
for (; max--; n -= m) count += (memo[n - m][m - 3] = p(n - 1, m - 1));
return count;
}
}
document.write(partition(150, 23) + "<br>");
document.write(partition(150, 75) + "<br>");
document.write(partition(150, 127) + "<br>");